

Estimating SARS-CoV-2 seroprevalence and epidemiological parameters with uncertainty from serological surveys
- PMID: 33666169
- PMCID: PMC7979159
- DOI: 10.7554/eLife.64206
Estimating SARS-CoV-2 seroprevalence and epidemiological parameters with uncertainty from serological surveys
Abstract
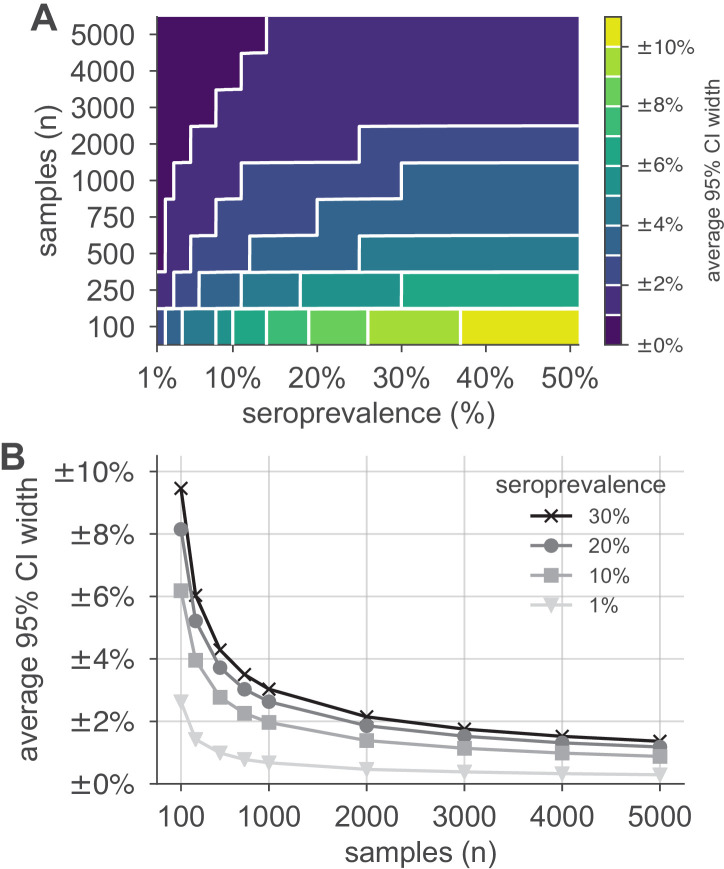
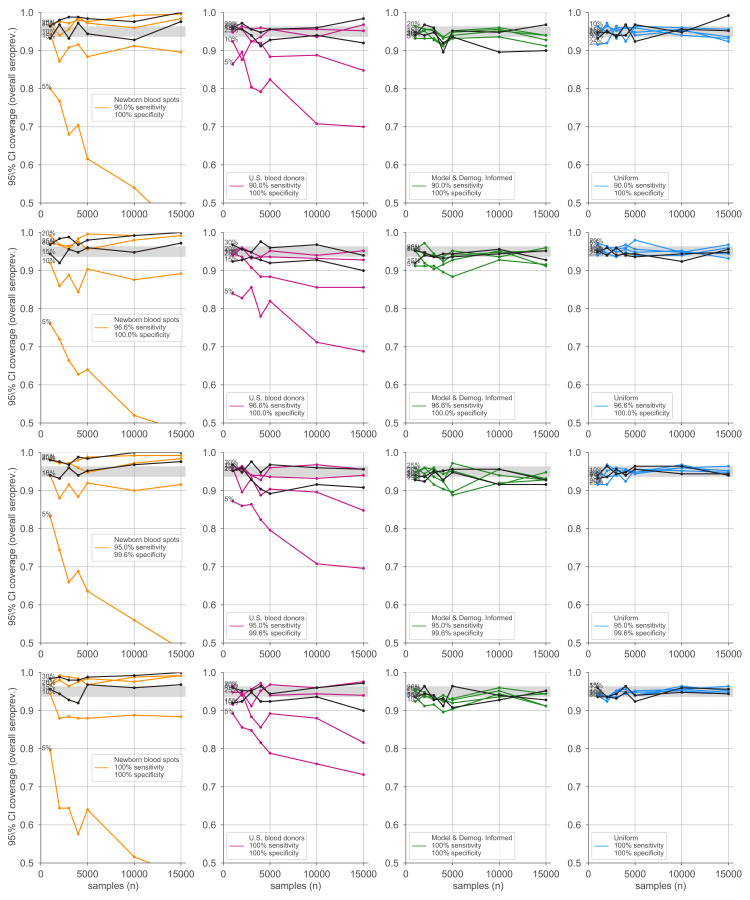
Establishing how many people have been infected by SARS-CoV-2 remains an urgent priority for controlling the COVID-19 pandemic. Serological tests that identify past infection can be used to estimate cumulative incidence, but the relative accuracy and robustness of various sampling strategies have been unclear. We developed a flexible framework that integrates uncertainty from test characteristics, sample size, and heterogeneity in seroprevalence across subpopulations to compare estimates from sampling schemes. Using the same framework and making the assumption that seropositivity indicates immune protection, we propagated estimates and uncertainty through dynamical models to assess uncertainty in the epidemiological parameters needed to evaluate public health interventions and found that sampling schemes informed by demographics and contact networks outperform uniform sampling. The framework can be adapted to optimize serosurvey design given test characteristics and capacity, population demography, sampling strategy, and modeling approach, and can be tailored to support decision-making around introducing or removing interventions.
Keywords: COVID-19; SARS-CoV-2; antibody; epidemiology; global health; infectious disease; microbiology; modeling; none; serology; uncertainty.
© 2021, Larremore et al.
Conflict of interest statement
DL, BF, KB, SZ, SK, CM, CB, YG No competing interests declared
Figures











References
-
- Ainslie KEC, Walters CE, Fu H, Bhatia S, Wang H, Xi X, Baguelin M, Bhatt S, Boonyasiri A, Boyd O, Cattarino L, Ciavarella C, Cucunuba Z, Cuomo-Dannenburg G, Dighe A, Dorigatti I, van Elsland SL, FitzJohn R, Gaythorpe K, Ghani AC, Green W, Hamlet A, Hinsley W, Imai N, Jorgensen D, Knock E, Laydon D, Nedjati-Gilani G, Okell LC, Siveroni I, Thompson HA, Unwin HJT, Verity R, Vollmer M, Walker PGT, Wang Y, Watson OJ, Whittaker C, Winskill P, Donnelly CA, Ferguson NM, Riley S. Evidence of initial success for China exiting COVID-19 social distancing policy after achieving containment. Wellcome Open Research. 2020;5:81. doi: 10.12688/wellcomeopenres.15843.2. - DOI - PMC - PubMed
-
- Buckee CO, Balsari S, Chan J, Crosas M, Dominici F, Gasser U, Grad YH, Grenfell B, Halloran ME, Kraemer MUG, Lipsitch M, Metcalf CJE, Meyers LA, Perkins TA, Santillana M, Scarpino SV, Viboud C, Wesolowski A, Schroeder A. Aggregated mobility data could help fight COVID-19. Science. 2020;368:145–146. doi: 10.1126/science.abb8021. - DOI - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
