

Pattern discovery and disentanglement on relational datasets
- PMID: 33707478
- PMCID: PMC7952710
- DOI: 10.1038/s41598-021-84869-4
Pattern discovery and disentanglement on relational datasets
Abstract
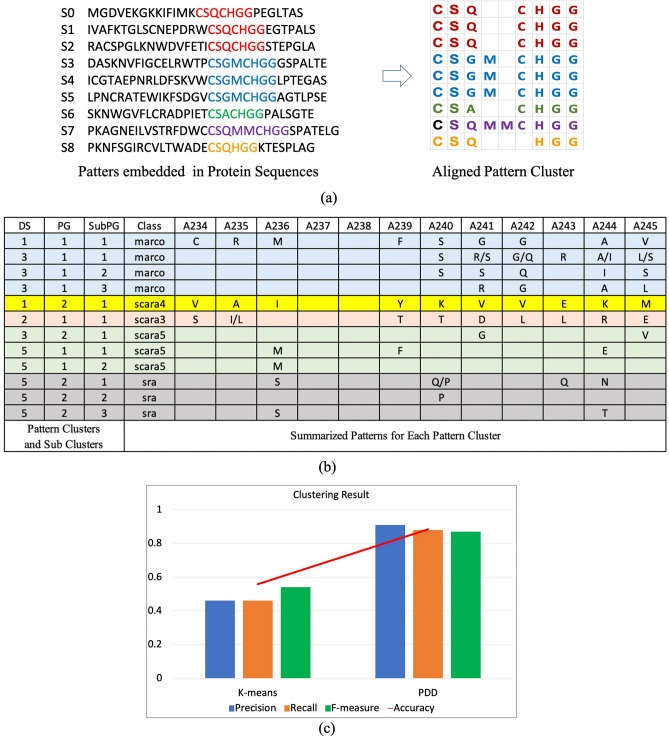
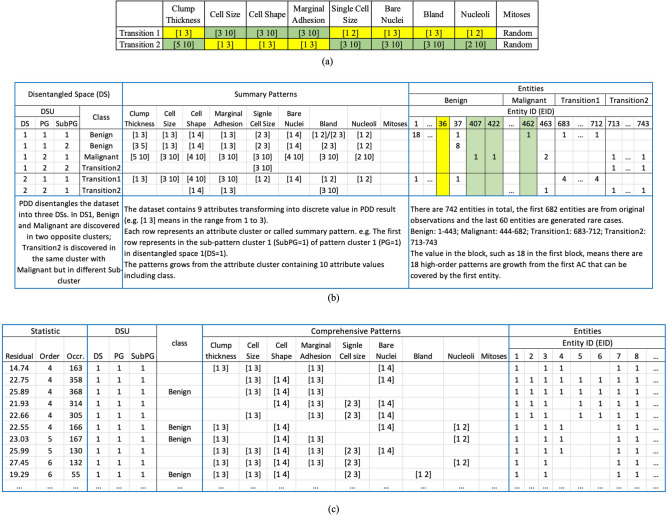
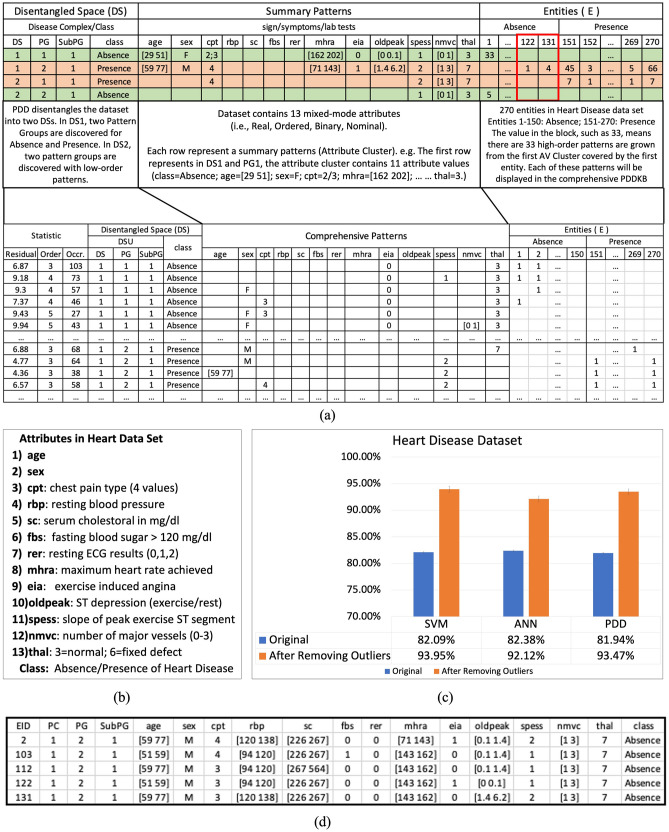
Machine Learning has made impressive advances in many applications akin to human cognition for discernment. However, success has been limited in the areas of relational datasets, particularly for data with low volume, imbalanced groups, and mislabeled cases, with outputs that typically lack transparency and interpretability. The difficulties arise from the subtle overlapping and entanglement of functional and statistical relations at the source level. Hence, we have developed Pattern Discovery and Disentanglement System (PDD), which is able to discover explicit patterns from the data with various sizes, imbalanced groups, and screen out anomalies. We present herein four case studies on biomedical datasets to substantiate the efficacy of PDD. It improves prediction accuracy and facilitates transparent interpretation of discovered knowledge in an explicit representation framework PDD Knowledge Base that links the sources, the patterns, and individual patients. Hence, PDD promises broad and ground-breaking applications in genomic and biomedical machine learning.
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Voosen, P. How AI detectives are cracking open the black box of deep learning. Science. https://www.sciencemag.org/news/2017/07/how-ai-detectives-are-cracking-o... (2017).
-
- Samek, W., Wiegand, T. & Müller, K. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv preprint, arXiv:1708.08296 (2017).
-
- Aggarwal, C. & Sathe, S. Bias reduction in outlier ensembles: the guessing game. In Outlier Ensembles (Springer, 2017). 10.1007/978-3-319-54765-7_4
-
- Napierala K, Stefanowski J. Types of minority class examples and their influence on learning classifiers from imbalanced data. J. Intell. Inf. Syst. 2016;46(3):563–597. doi: 10.1007/s10844-015-0368-1. - DOI
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources
