

GRAM: Graph-based Attention Model for Healthcare Representation Learning
- PMID: 33717639
- PMCID: PMC7954122
- DOI: 10.1145/3097983.3098126
GRAM: Graph-based Attention Model for Healthcare Representation Learning
Abstract
Deep learning methods exhibit promising performance for predictive modeling in healthcare, but two important challenges remain: Data insufficiency: Often in healthcare predictive modeling, the sample size is insufficient for deep learning methods to achieve satisfactory results.Interpretation: The representations learned by deep learning methods should align with medical knowledge. To address these challenges, we propose GRaph-based Attention Model (GRAM) that supplements electronic health records (EHR) with hierarchical information inherent to medical ontologies. Based on the data volume and the ontology structure, GRAM represents a medical concept as a combination of its ancestors in the ontology via an attention mechanism. We compared predictive performance (i.e. accuracy, data needs, interpretability) of GRAM to various methods including the recurrent neural network (RNN) in two sequential diagnoses prediction tasks and one heart failure prediction task. Compared to the basic RNN, GRAM achieved 10% higher accuracy for predicting diseases rarely observed in the training data and 3% improved area under the ROC curve for predicting heart failure using an order of magnitude less training data. Additionally, unlike other methods, the medical concept representations learned by GRAM are well aligned with the medical ontology. Finally, GRAM exhibits intuitive attention behaviors by adaptively generalizing to higher level concepts when facing data insufficiency at the lower level concepts.
Keywords: Attention Model; Electronic Health Records; Graph; Predictive Healthcare.
Figures
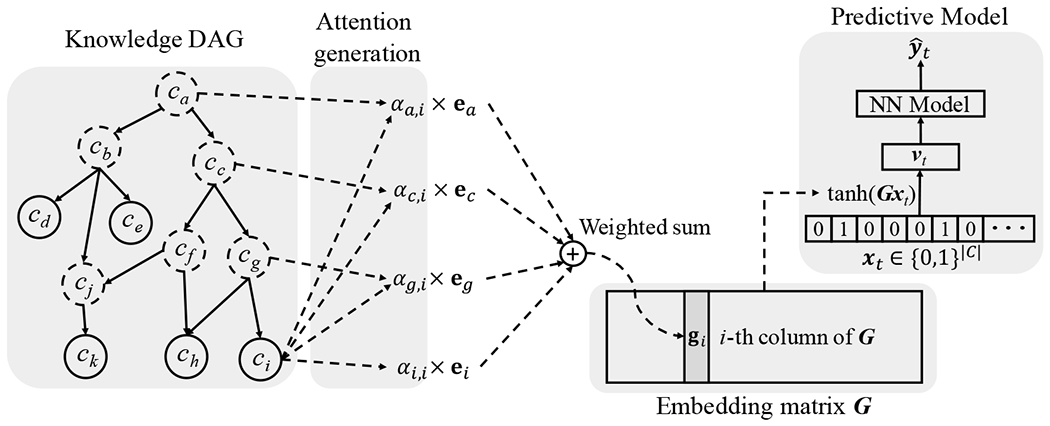
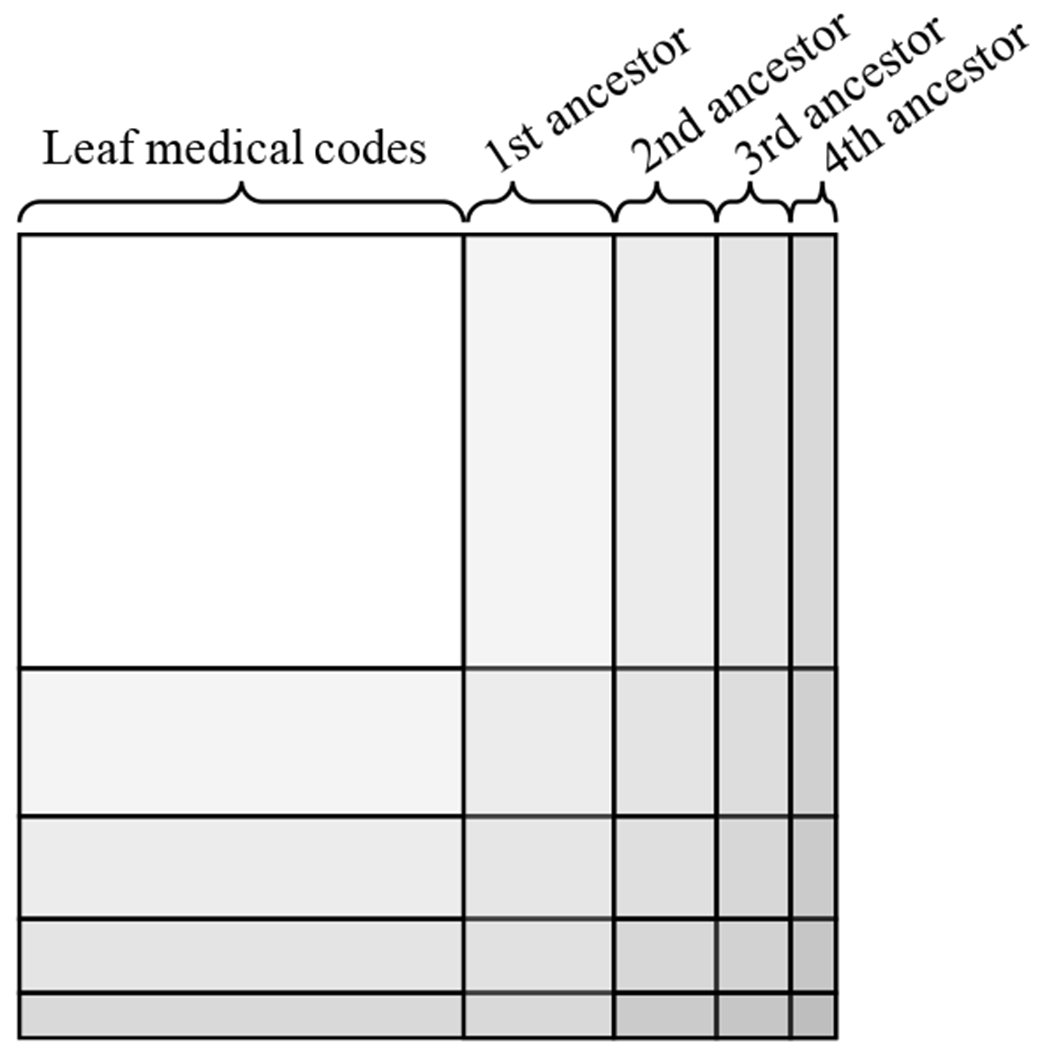
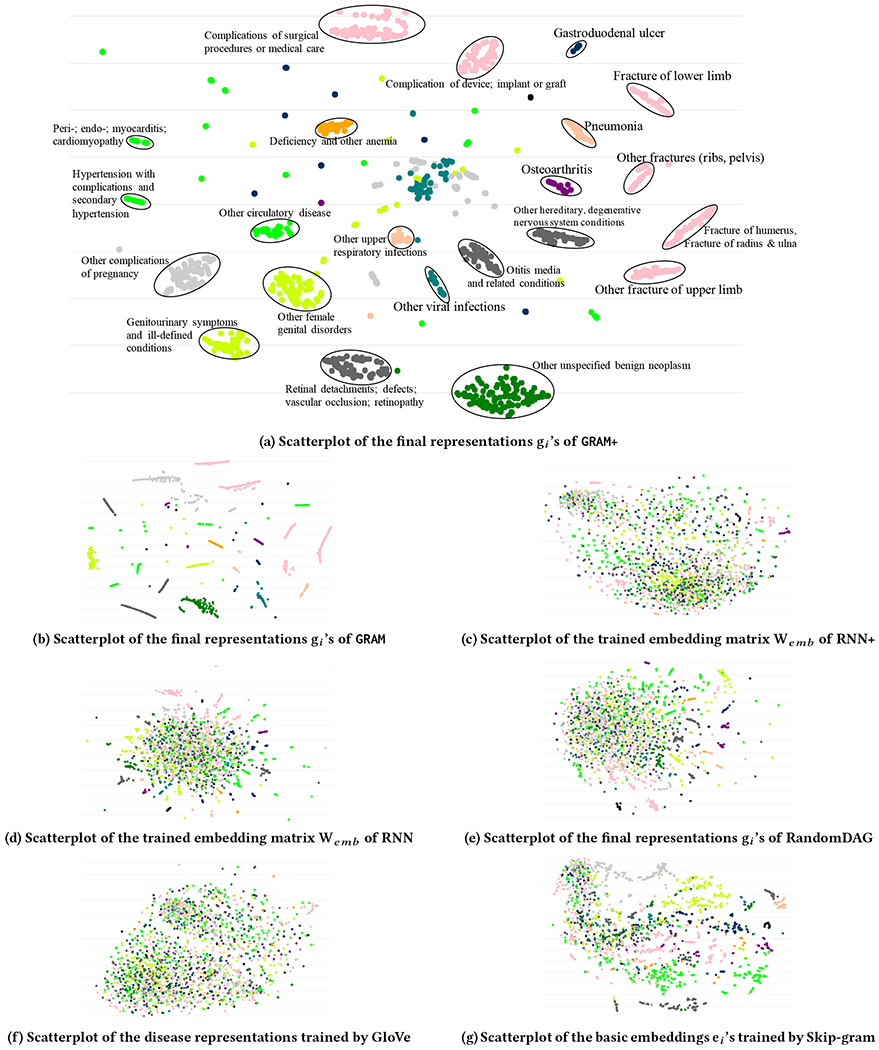
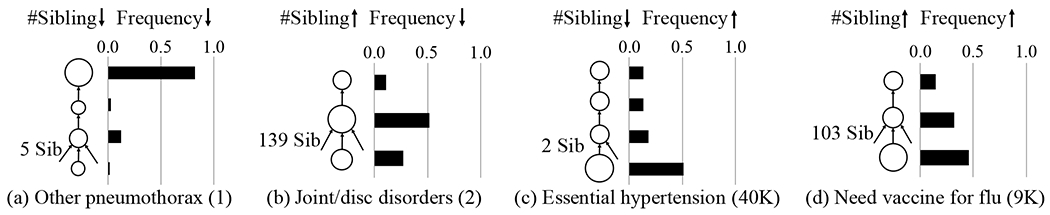
References
-
- Ba Jimmy, Mnih Volodymyr, and Kavukcuoglu Koray. 2014. Multiple object recognition with visual attention. arXiv:1412.7755 (2014).
-
- Bahdanau Dzmitry, Cho Kyunghyun, and Bengio Yoshua. 2014. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473 (2014).
-
- Bengio Yoshua, Simard Patrice, and Frasconi Paolo. 1994. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks 5, 2 (1994). - PubMed
-
- Bollacker Kurt, Evans Colin, Paritosh Praveen, Sturge Tim, and Taylor Jamie. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In SIGMOD.
-
- Bordes Antoine, Usunier Nicolas, Garcia-Duran Alberto, Weston Jason and Yakhnenko Oksana. 2013. Translating embeddings for modeling multi-relational data. In NIPS.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources