

An Introductory Review of Deep Learning for Prediction Models With Big Data
- PMID: 33733124
- PMCID: PMC7861305
- DOI: 10.3389/frai.2020.00004
An Introductory Review of Deep Learning for Prediction Models With Big Data
Abstract
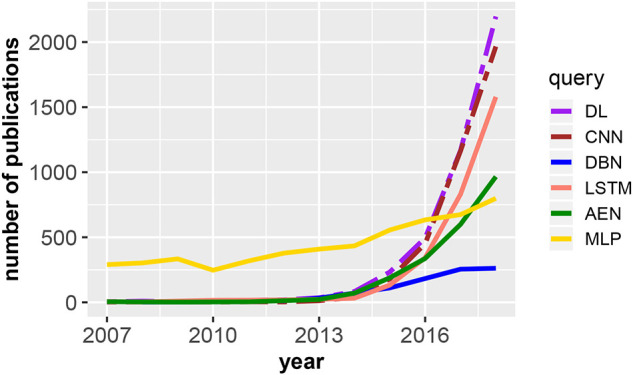
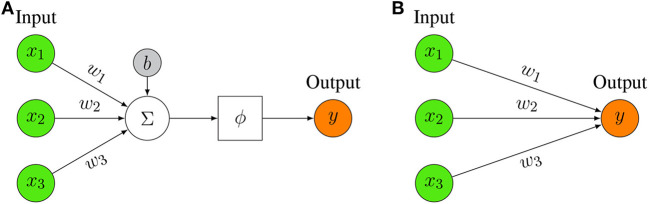
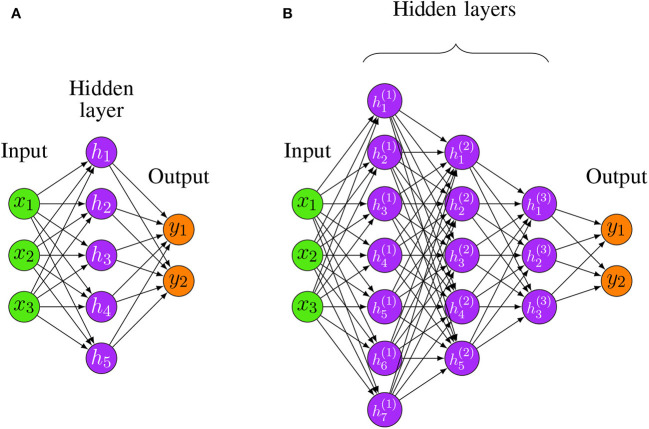
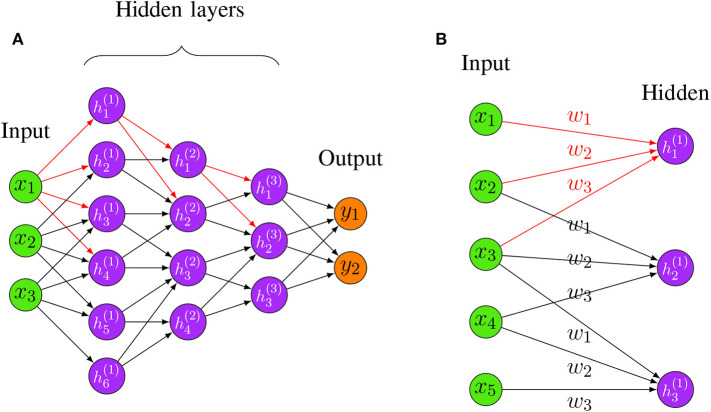
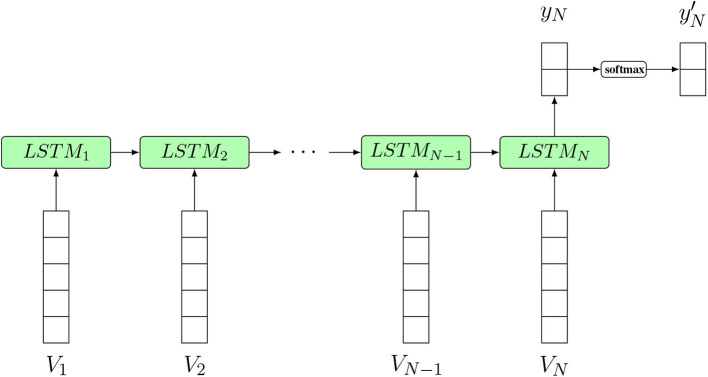
Deep learning models stand for a new learning paradigm in artificial intelligence (AI) and machine learning. Recent breakthrough results in image analysis and speech recognition have generated a massive interest in this field because also applications in many other domains providing big data seem possible. On a downside, the mathematical and computational methodology underlying deep learning models is very challenging, especially for interdisciplinary scientists. For this reason, we present in this paper an introductory review of deep learning approaches including Deep Feedforward Neural Networks (D-FFNN), Convolutional Neural Networks (CNNs), Deep Belief Networks (DBNs), Autoencoders (AEs), and Long Short-Term Memory (LSTM) networks. These models form the major core architectures of deep learning models currently used and should belong in any data scientist's toolbox. Importantly, those core architectural building blocks can be composed flexibly-in an almost Lego-like manner-to build new application-specific network architectures. Hence, a basic understanding of these network architectures is important to be prepared for future developments in AI.
Keywords: artificial intelligence; data science; deep learning; machine learning; neural networks; prediction models.
Copyright © 2020 Emmert-Streib, Yang, Feng, Tripathi and Dehmer.
Figures


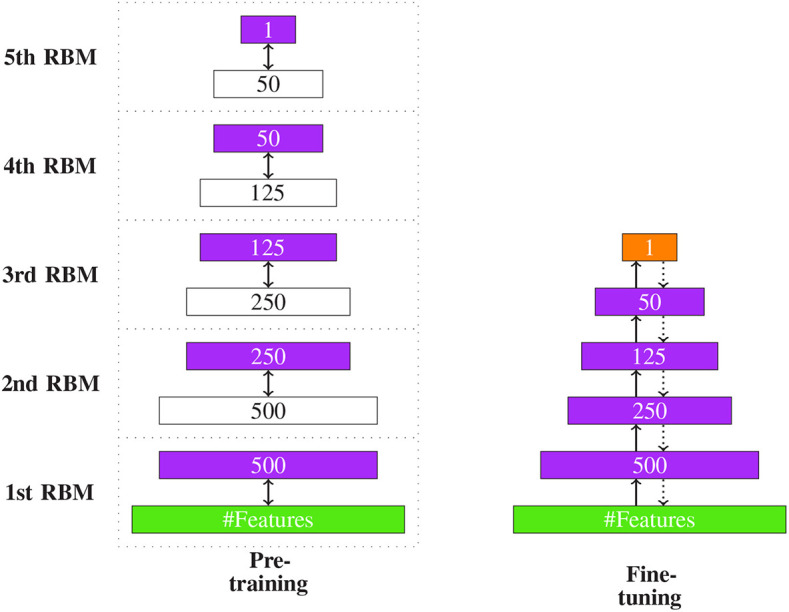
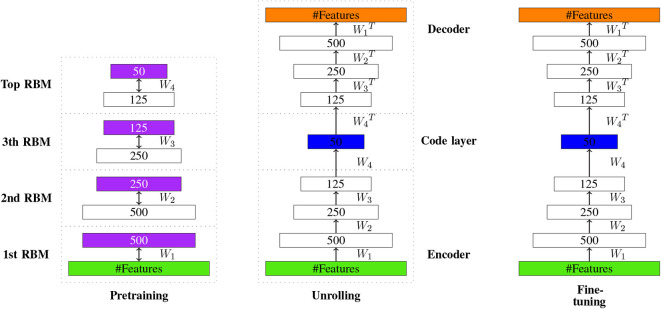

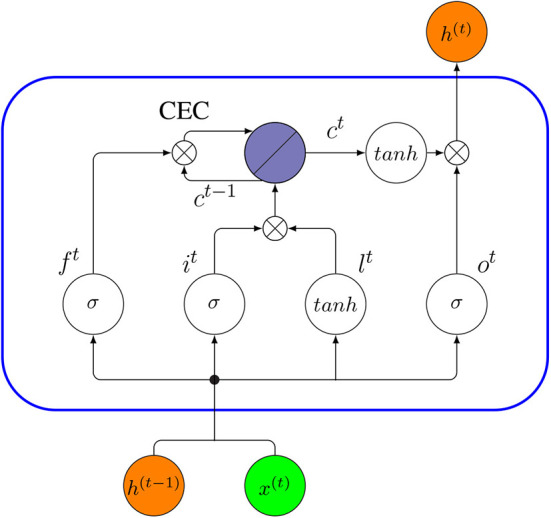
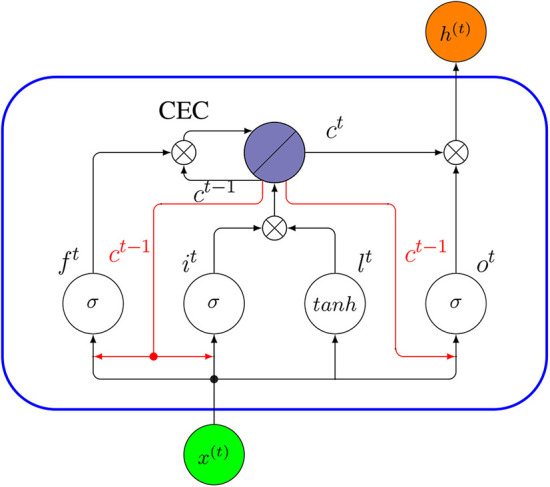

References
-
- An J., Cho S. (2015). Variational Autoencoder Based Anomaly Detection Using Reconstruction Probability. Special Lecture on IE 2.
-
- Arulkumaran K., Deisenroth M. P., Brundage M., Bharath A. A. (2017). Deep reinforcement learning: a brief survey. IEEE Signal Process. Mag. 34, 26–38. 10.1109/MSP.2017.2743240 - DOI
-
- Bergmeir C., Benítez J. M. (2012). Neural networks in R using the stuttgart neural network simulator: RSNNS. J. Stat. Softw. 46, 1–26. 10.18637/jss.v046.i07 - DOI
-
- Biran O., Cotton C. (2017). Explanation and justification in machine learning: a survey, in IJCAI-17 Workshop on Explainable AI (XAI). Vol. 8, 1.
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources