

Deep Active Inference and Scene Construction
- PMID: 33733195
- PMCID: PMC7861336
- DOI: 10.3389/frai.2020.509354
Deep Active Inference and Scene Construction
Abstract
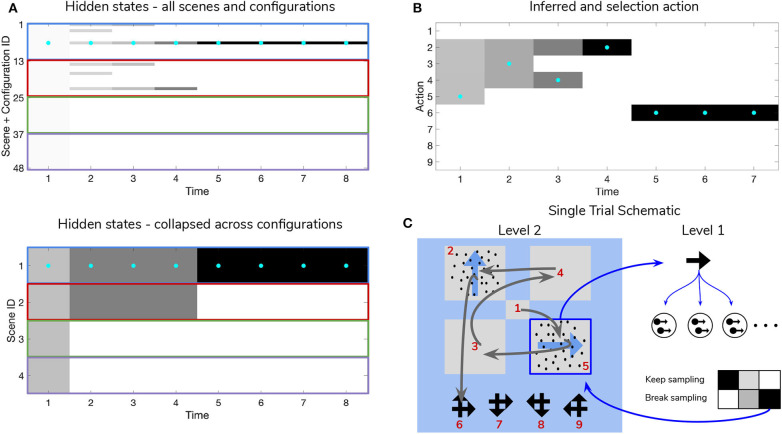
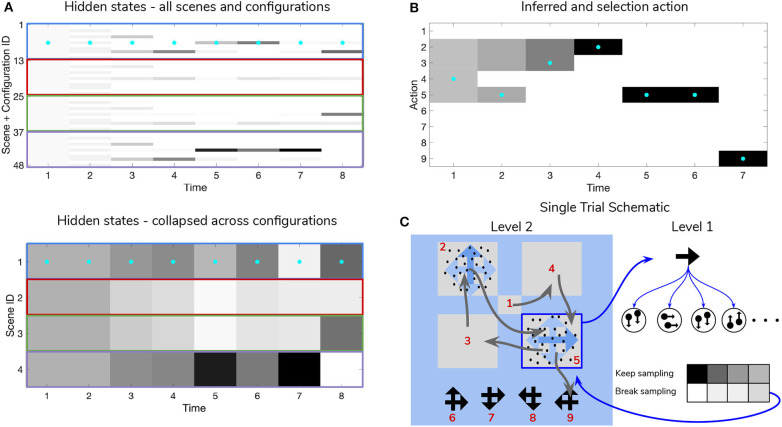
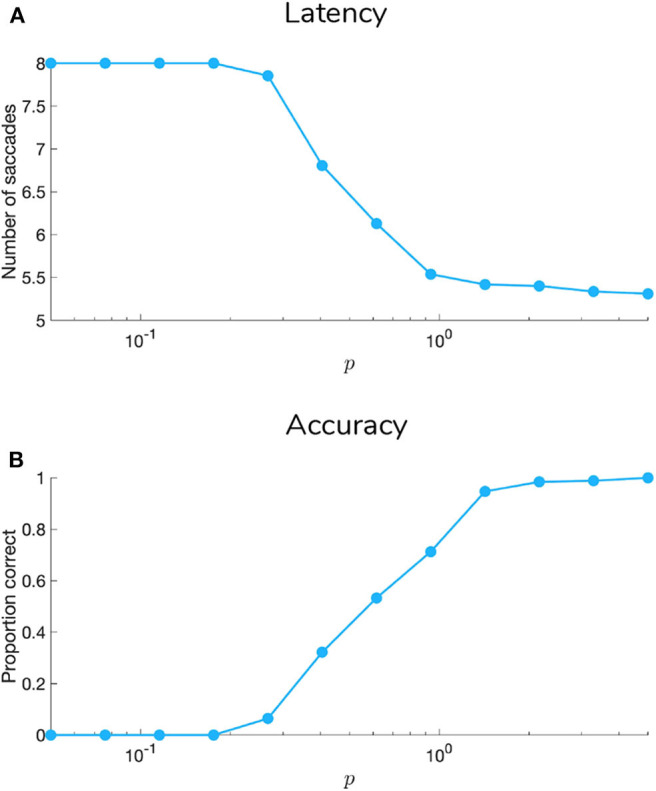
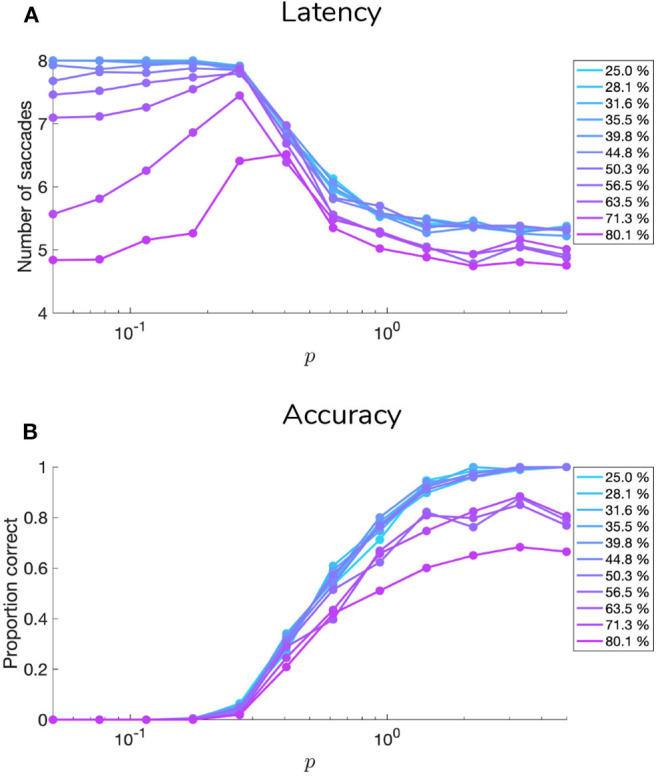
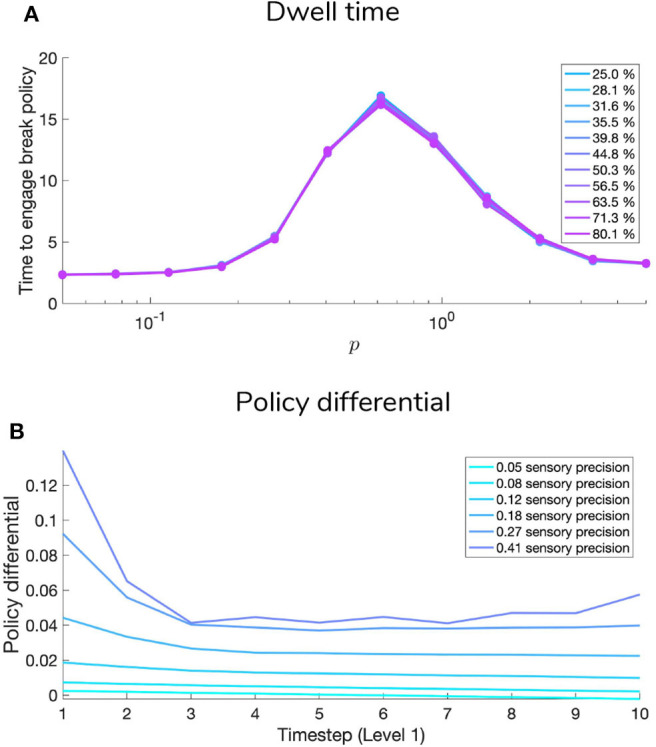
Adaptive agents must act in intrinsically uncertain environments with complex latent structure. Here, we elaborate a model of visual foraging-in a hierarchical context-wherein agents infer a higher-order visual pattern (a "scene") by sequentially sampling ambiguous cues. Inspired by previous models of scene construction-that cast perception and action as consequences of approximate Bayesian inference-we use active inference to simulate decisions of agents categorizing a scene in a hierarchically-structured setting. Under active inference, agents develop probabilistic beliefs about their environment, while actively sampling it to maximize the evidence for their internal generative model. This approximate evidence maximization (i.e., self-evidencing) comprises drives to both maximize rewards and resolve uncertainty about hidden states. This is realized via minimization of a free energy functional of posterior beliefs about both the world as well as the actions used to sample or perturb it, corresponding to perception and action, respectively. We show that active inference, in the context of hierarchical scene construction, gives rise to many empirical evidence accumulation phenomena, such as noise-sensitive reaction times and epistemic saccades. We explain these behaviors in terms of the principled drives that constitute the expected free energy, the key quantity for evaluating policies under active inference. In addition, we report novel behaviors exhibited by these active inference agents that furnish new predictions for research on evidence accumulation and perceptual decision-making. We discuss the implications of this hierarchical active inference scheme for tasks that require planned sequences of information-gathering actions to infer compositional latent structure (such as visual scene construction and sentence comprehension). This work sets the stage for future experiments to investigate active inference in relation to other formulations of evidence accumulation (e.g., drift-diffusion models) in tasks that require planning in uncertain environments with higher-order structure.
Keywords: Bayesian brain; active inference; epistemic value; free energy; hierarchical inference; random dot motion; visual foraging.
Copyright © 2020 Heins, Mirza, Parr, Friston, Kagan and Pooresmaeili.
Figures
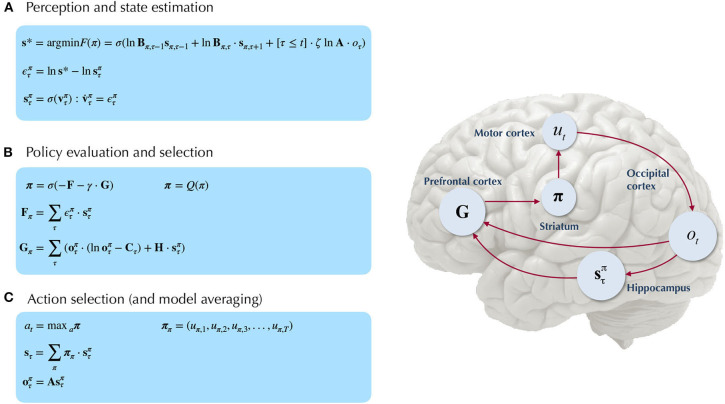
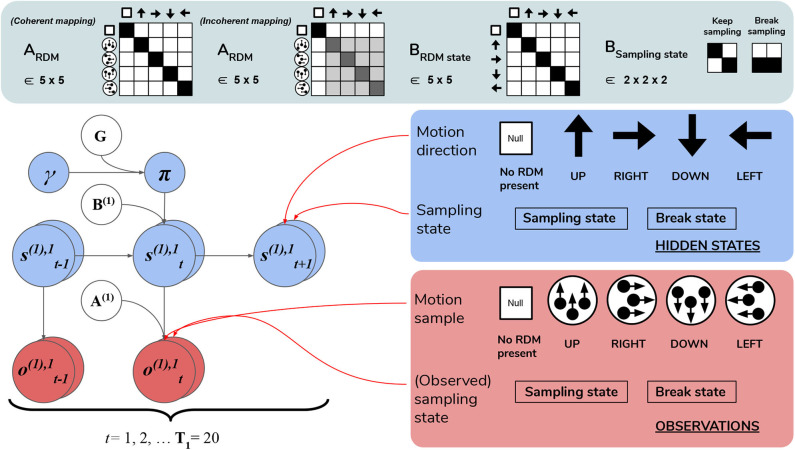
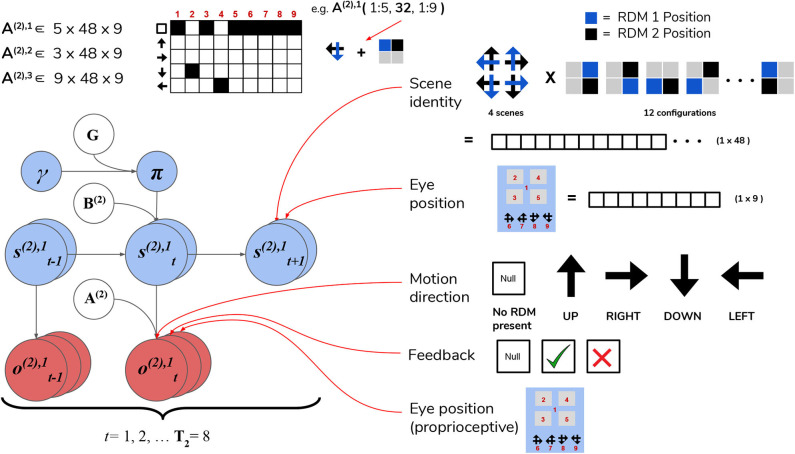
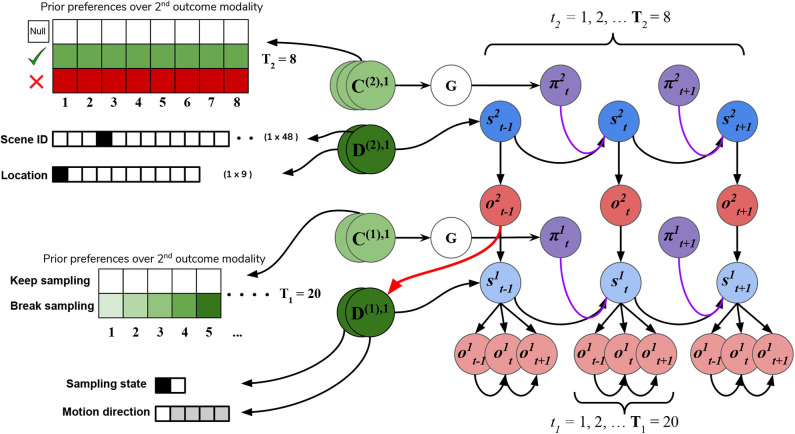
References
-
- Beal M. J. (2004). Variational algorithms for approximate bayesian inference (Ph.D. thesis), Gatsby Unit, University College London, London, United Kingdom.
-
- Blei D. M., Kucukelbir A., McAuliffe J. D. (2017). Variational inference: a review for statisticians. J. Am. Stat. Assoc. 112, 859–877. 10.1080/01621459.2017.1285773 - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous