

Rapid development of cloud-native intelligent data pipelines for scientific data streams using the HASTE Toolkit
- PMID: 33739401
- PMCID: PMC7976223
- DOI: 10.1093/gigascience/giab018
Rapid development of cloud-native intelligent data pipelines for scientific data streams using the HASTE Toolkit
Abstract
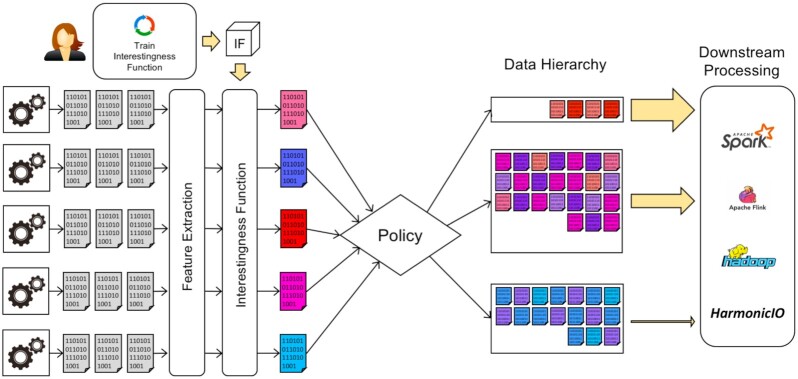
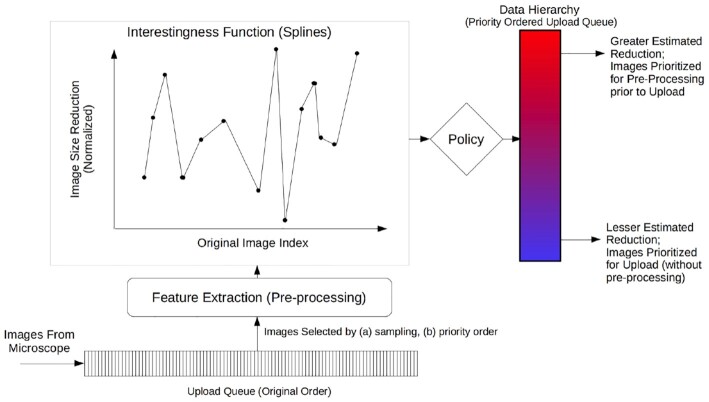
Background: Large streamed datasets, characteristic of life science applications, are often resource-intensive to process, transport and store. We propose a pipeline model, a design pattern for scientific pipelines, where an incoming stream of scientific data is organized into a tiered or ordered "data hierarchy". We introduce the HASTE Toolkit, a proof-of-concept cloud-native software toolkit based on this pipeline model, to partition and prioritize data streams to optimize use of limited computing resources.
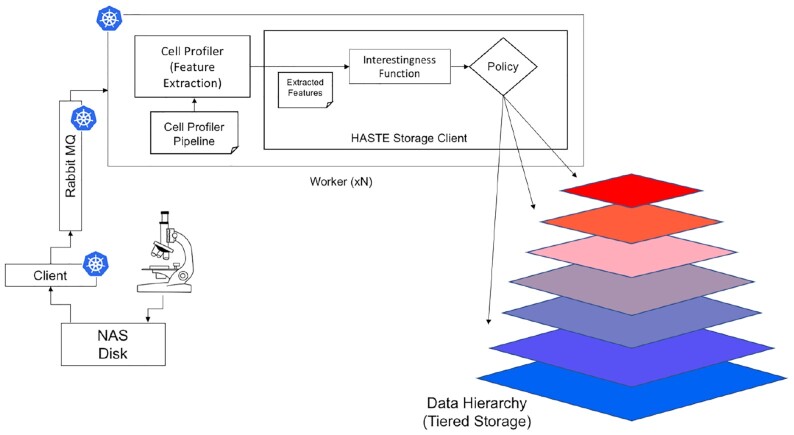
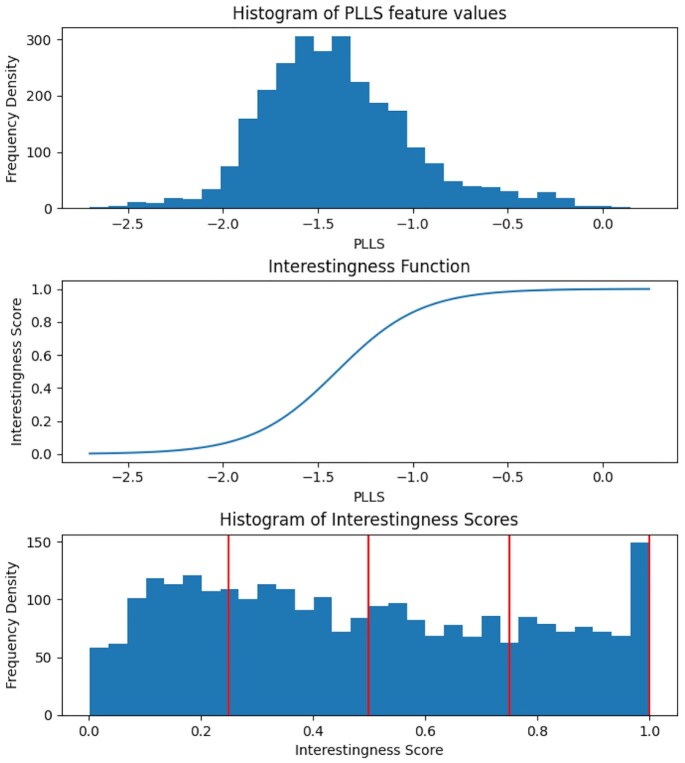
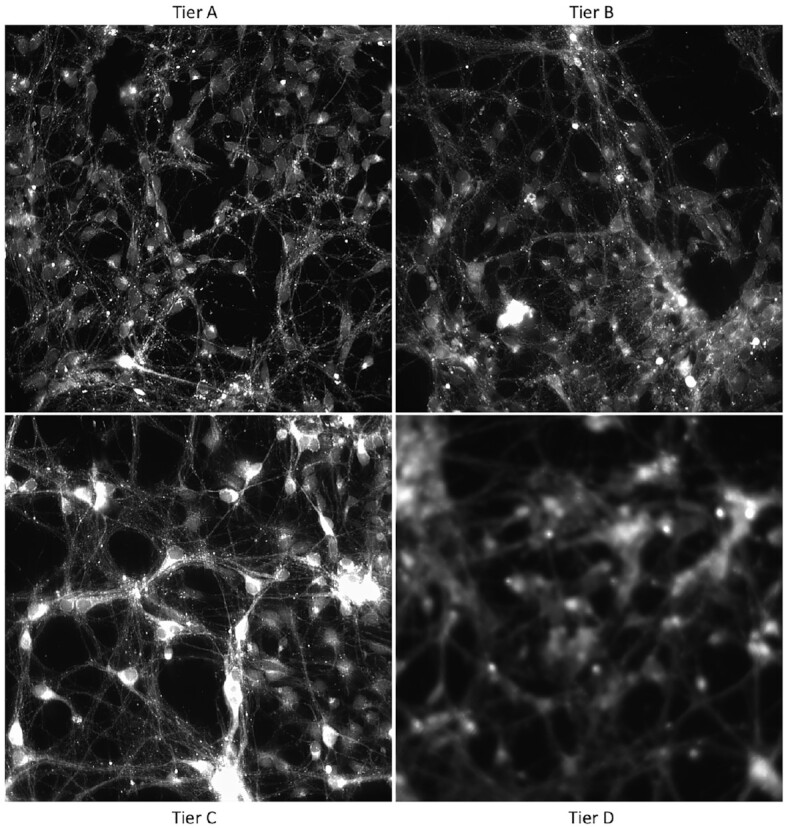
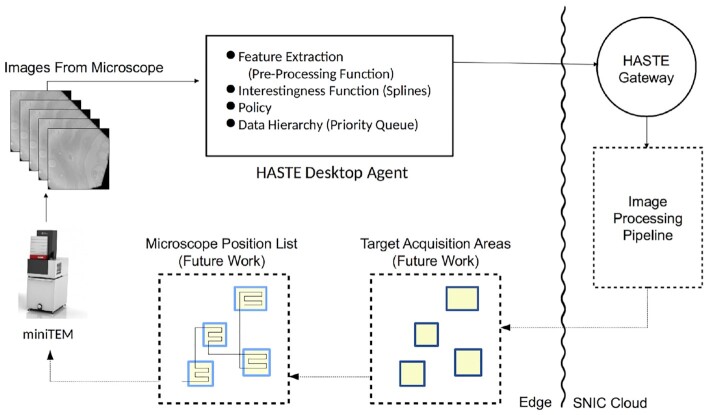
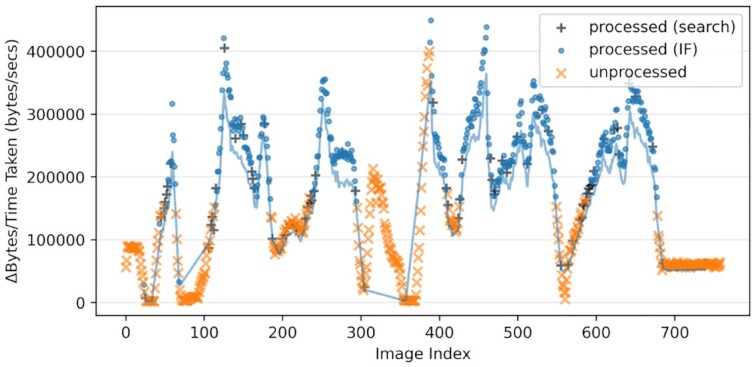
Findings: In our pipeline model, an "interestingness function" assigns an interestingness score to data objects in the stream, inducing a data hierarchy. From this score, a "policy" guides decisions on how to prioritize computational resource use for a given object. The HASTE Toolkit is a collection of tools to adopt this approach. We evaluate with 2 microscopy imaging case studies. The first is a high content screening experiment, where images are analyzed in an on-premise container cloud to prioritize storage and subsequent computation. The second considers edge processing of images for upload into the public cloud for real-time control of a transmission electron microscope.
Conclusions: Through our evaluation, we created smart data pipelines capable of effective use of storage, compute, and network resources, enabling more efficient data-intensive experiments. We note a beneficial separation between scientific concerns of data priority, and the implementation of this behaviour for different resources in different deployment contexts. The toolkit allows intelligent prioritization to be `bolted on' to new and existing systems - and is intended for use with a range of technologies in different deployment scenarios.
Keywords: HASTE; image analysis; interestingness functions; stream processing; tiered storage.
© The Author(s) 2021. Published by Oxford University Press GigaScience.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
References
-
- Ouyang W, Zimmer C. The imaging tsunami: computational opportunities and challenges. Curr Opin Syst Biol. 2017;4:105–13.
-
- Blamey B, Wrede F, Karlsson J, et al. Adapting the secretary hiring problem for optimal hot-cold tier placement under top-K workloads. In: 2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID) Larnaca, Cyprus; 2019:576–583.
-
- Sivarajah U, Kamal MM, Irani Z, et al. Critical analysis of big data challenges and analytical methods. J Bus Res. 2017;70:263–86.
-
- Reinsel D, Gantz J, Rydning J. Data Age 2025: The Digitization of the World from Edge to Core (Seagate White Paper); 2018. https://www.seagate.com/www-content/our-story/trends/files/idc-seagate-d.... An IDC White Paper – #US44413318. Accessed: April 2020
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
