

Reconstructing feedback representations in the ventral visual pathway with a generative adversarial autoencoder
- PMID: 33760819
- PMCID: PMC8059812
- DOI: 10.1371/journal.pcbi.1008775
Reconstructing feedback representations in the ventral visual pathway with a generative adversarial autoencoder
Abstract
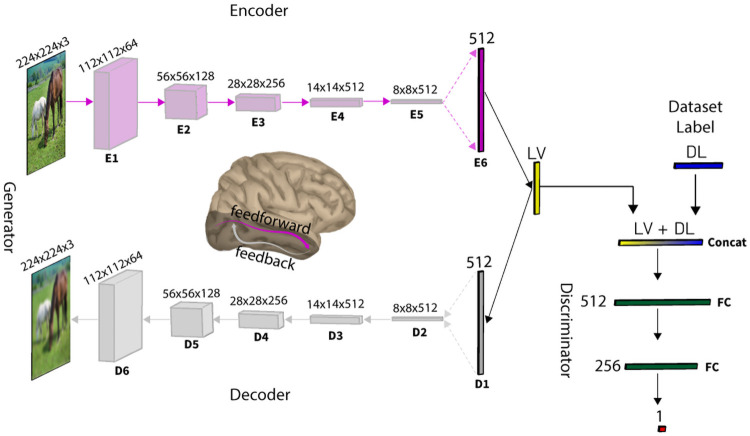
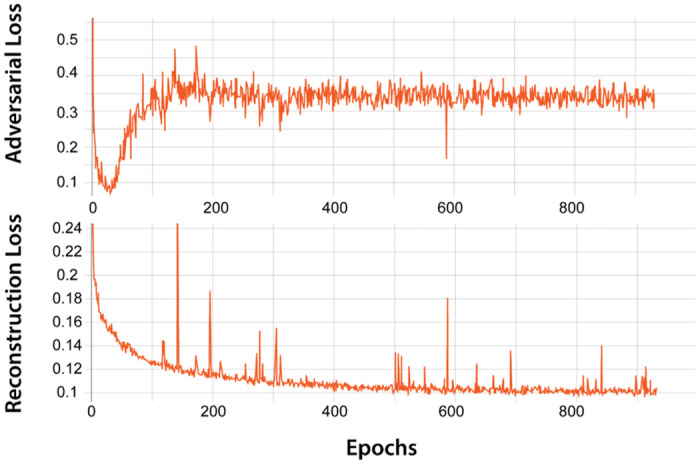
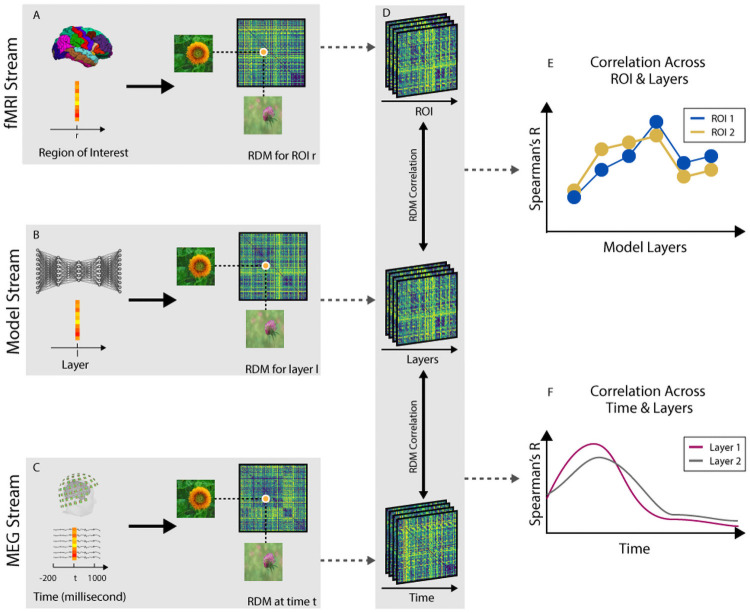
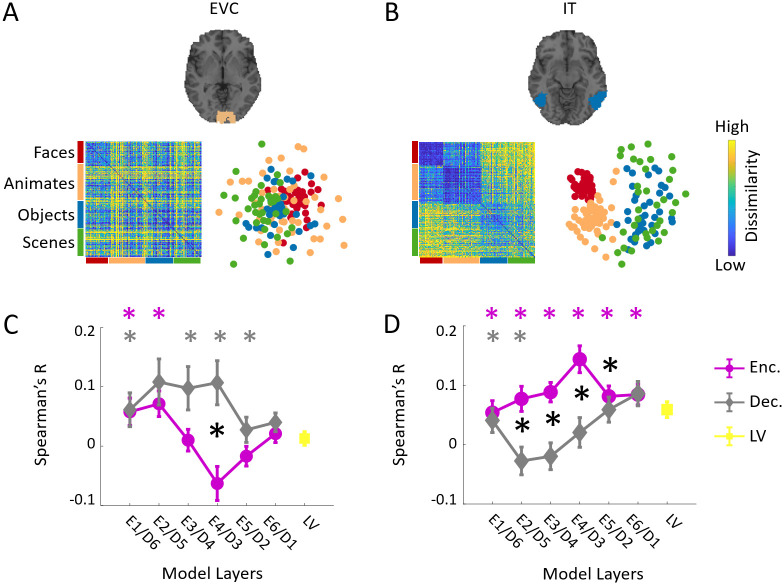
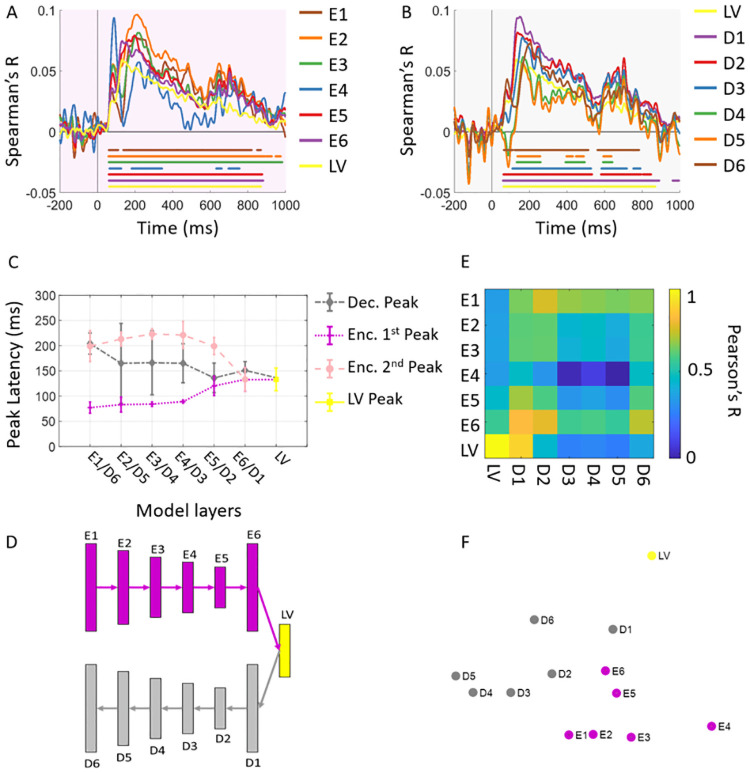
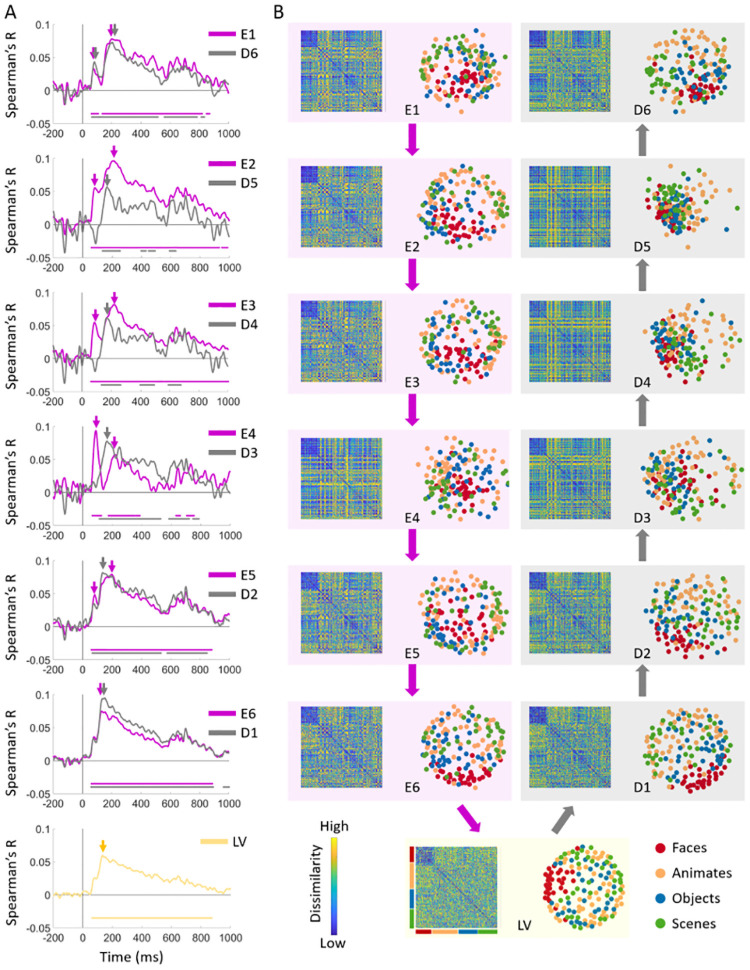
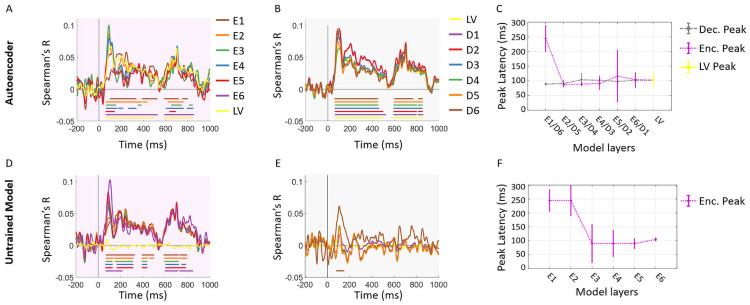
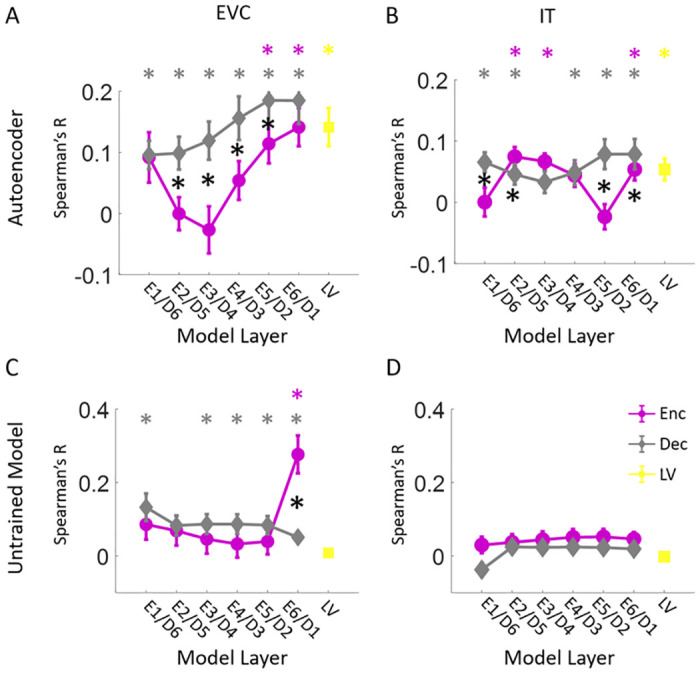
While vision evokes a dense network of feedforward and feedback neural processes in the brain, visual processes are primarily modeled with feedforward hierarchical neural networks, leaving the computational role of feedback processes poorly understood. Here, we developed a generative autoencoder neural network model and adversarially trained it on a categorically diverse data set of images. We hypothesized that the feedback processes in the ventral visual pathway can be represented by reconstruction of the visual information performed by the generative model. We compared representational similarity of the activity patterns in the proposed model with temporal (magnetoencephalography) and spatial (functional magnetic resonance imaging) visual brain responses. The proposed generative model identified two segregated neural dynamics in the visual brain. A temporal hierarchy of processes transforming low level visual information into high level semantics in the feedforward sweep, and a temporally later dynamics of inverse processes reconstructing low level visual information from a high level latent representation in the feedback sweep. Our results append to previous studies on neural feedback processes by presenting a new insight into the algorithmic function and the information carried by the feedback processes in the ventral visual pathway.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
