

Ontology-driven weak supervision for clinical entity classification in electronic health records
- PMID: 33795682
- PMCID: PMC8016863
- DOI: 10.1038/s41467-021-22328-4
Ontology-driven weak supervision for clinical entity classification in electronic health records
Abstract
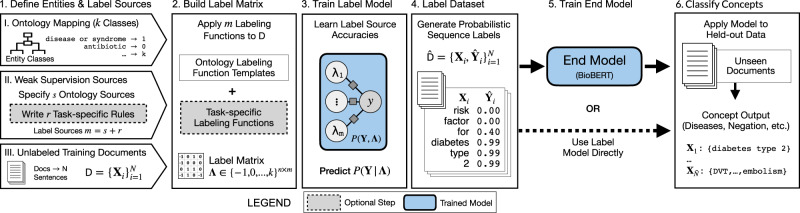
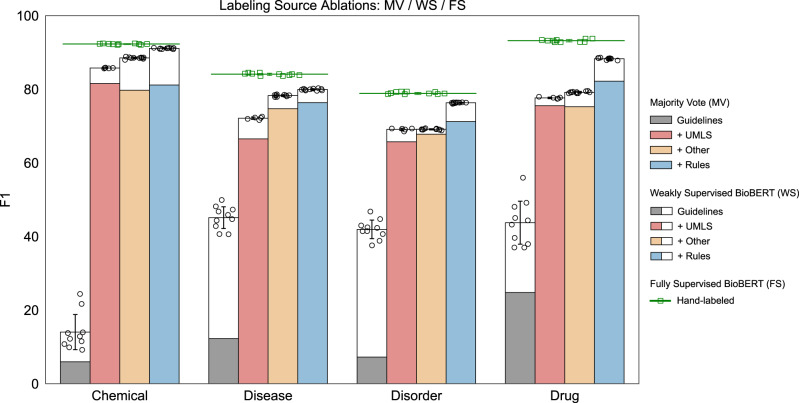
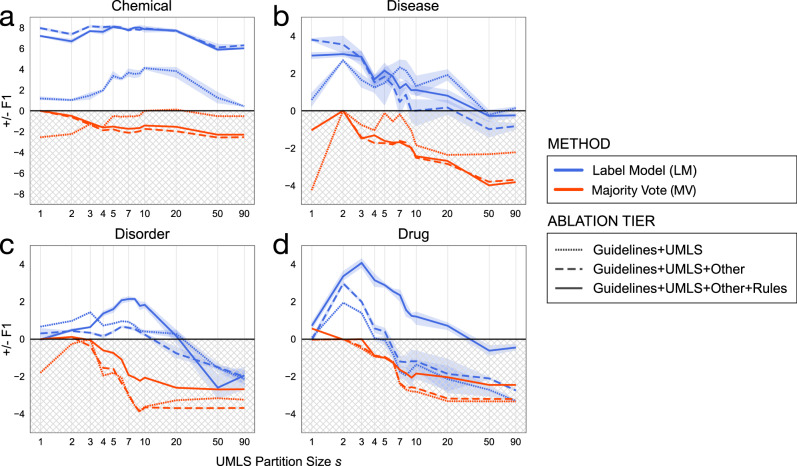
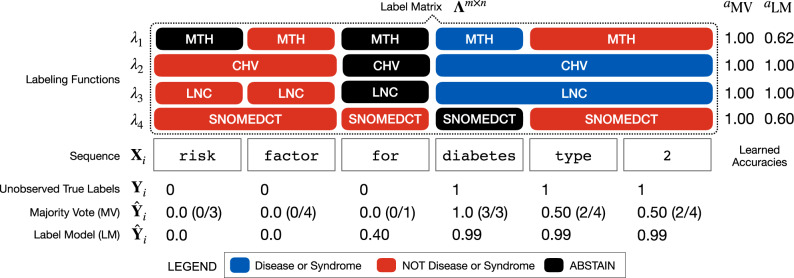
In the electronic health record, using clinical notes to identify entities such as disorders and their temporality (e.g. the order of an event relative to a time index) can inform many important analyses. However, creating training data for clinical entity tasks is time consuming and sharing labeled data is challenging due to privacy concerns. The information needs of the COVID-19 pandemic highlight the need for agile methods of training machine learning models for clinical notes. We present Trove, a framework for weakly supervised entity classification using medical ontologies and expert-generated rules. Our approach, unlike hand-labeled notes, is easy to share and modify, while offering performance comparable to learning from manually labeled training data. In this work, we validate our framework on six benchmark tasks and demonstrate Trove's ability to analyze the records of patients visiting the emergency department at Stanford Health Care for COVID-19 presenting symptoms and risk factors.
Conflict of interest statement
The authors declare no competing interests.
Figures
Update of
-
Ontology-driven weak supervision for clinical entity classification in electronic health records.ArXiv [Preprint]. 2020 Aug 5:arXiv:2008.01972v2. ArXiv. 2020. Update in: Nat Commun. 2021 Apr 1;12(1):2017. doi: 10.1038/s41467-021-22328-4. PMID: 32793768 Free PMC article. Updated. Preprint.
References
-
- Wang, L. L. et al. CORD-19: The COVID-19 open research dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020 (eds Karin Verspoor, Kevin Bretonnel Cohen, Mark Dredze, Emilio Ferrara, Jonathan May, Robert Munro, Cecile Paris & Byron Wallace) (Association for Computational Linguistics, Online, 2020) https://www.aclweb.org/anthology/2020.nlpcovid19-acl.1.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
