

Automated quality control and cell identification of droplet-based single-cell data using dropkick
- PMID: 33837131
- PMCID: PMC8494217
- DOI: 10.1101/gr.271908.120
Automated quality control and cell identification of droplet-based single-cell data using dropkick
Abstract
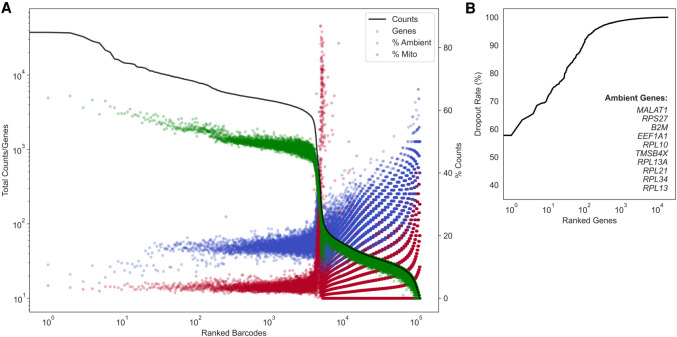
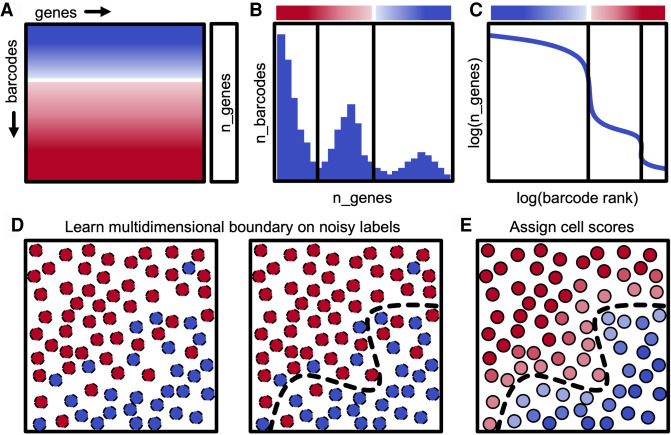
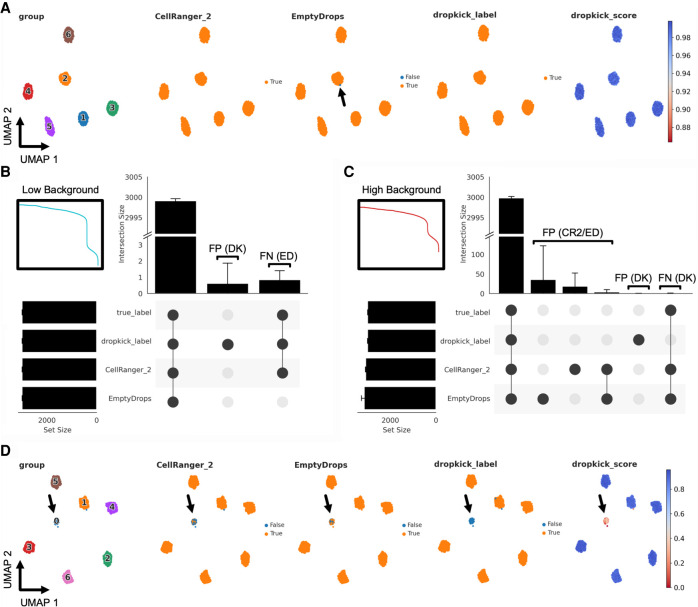
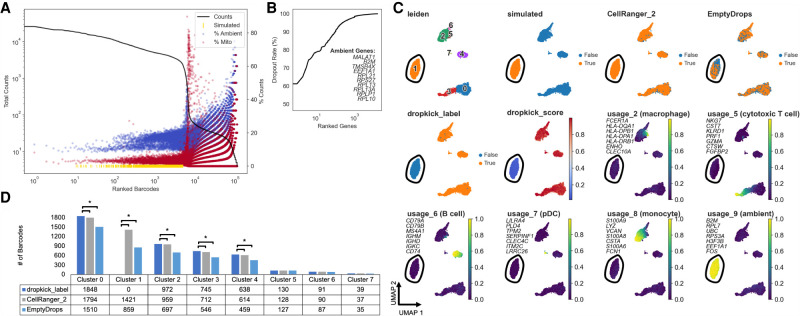
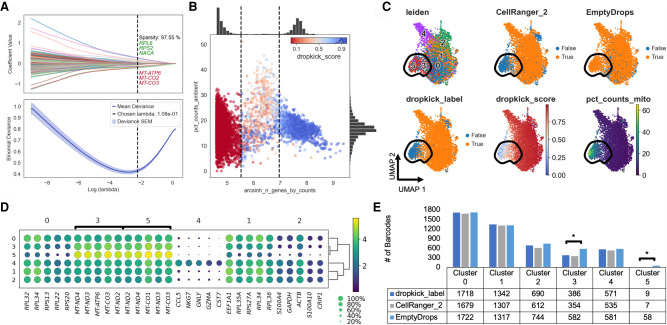
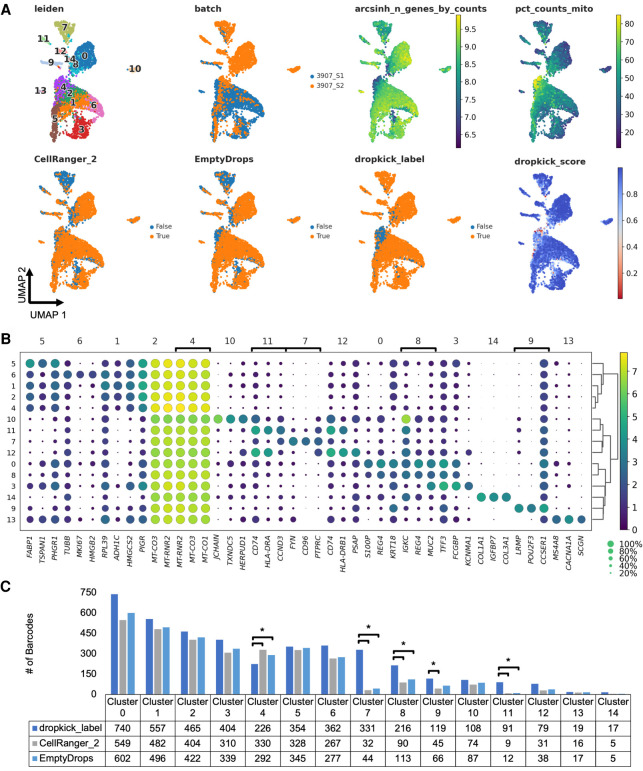
A major challenge for droplet-based single-cell sequencing technologies is distinguishing true cells from uninformative barcodes in data sets with disparate library sizes confounded by high technical noise (i.e., batch-specific ambient RNA). We present dropkick, a fully automated software tool for quality control and filtering of single-cell RNA sequencing (scRNA-seq) data with a focus on excluding ambient barcodes and recovering real cells bordering the quality threshold. By automatically determining data set-specific training labels based on predictive global heuristics, dropkick learns a gene-based representation of real cells and ambient noise, calculating a cell probability score for each barcode. Using simulated and real-world scRNA-seq data, we benchmarked dropkick against conventional thresholding approaches and EmptyDrops, a popular computational method, showing greater recovery of rare cell types and exclusion of empty droplets and noisy, uninformative barcodes. We show for both low- and high-background data sets that dropkick's weakly supervised model reliably learns which genes are enriched in ambient barcodes and draws a multidimensional boundary that is more robust to data set-specific variation than existing filtering approaches. dropkick provides a fast, automated tool for reproducible cell identification from scRNA-seq data that is critical to downstream analysis and compatible with popular single-cell Python packages.
© 2021 Heiser et al.; Published by Cold Spring Harbor Laboratory Press.
Figures
Similar articles
-
Identification of cell barcodes from long-read single-cell RNA-seq with BLAZE.Genome Biol. 2023 Apr 6;24(1):66. doi: 10.1186/s13059-023-02907-y. Genome Biol. 2023. PMID: 37024980 Free PMC article.
-
DropletQC: improved identification of empty droplets and damaged cells in single-cell RNA-seq data.Genome Biol. 2021 Dec 2;22(1):329. doi: 10.1186/s13059-021-02547-0. Genome Biol. 2021. PMID: 34857027 Free PMC article.
-
SiftCell: A robust framework to detect and isolate cell-containing droplets from single-cell RNA sequence reads.Cell Syst. 2023 Jul 19;14(7):620-628.e3. doi: 10.1016/j.cels.2023.06.002. Cell Syst. 2023. PMID: 37473732 Free PMC article.
-
GE-Impute: graph embedding-based imputation for single-cell RNA-seq data.Brief Bioinform. 2022 Sep 20;23(5):bbac313. doi: 10.1093/bib/bbac313. Brief Bioinform. 2022. PMID: 35901457
-
Machine learning and statistical methods for clustering single-cell RNA-sequencing data.Brief Bioinform. 2020 Jul 15;21(4):1209-1223. doi: 10.1093/bib/bbz063. Brief Bioinform. 2020. PMID: 31243426 Review.
Cited by
-
Studying stochastic systems biology of the cell with single-cell genomics data.Cell Syst. 2023 Oct 18;14(10):822-843.e22. doi: 10.1016/j.cels.2023.08.004. Epub 2023 Sep 25. Cell Syst. 2023. PMID: 37751736 Free PMC article. Review.
-
A Novel Type of Monocytic Leukemia Stem Cell Revealed by the Clinical Use of Venetoclax-Based Therapy.Cancer Discov. 2023 Sep 6;13(9):2032-2049. doi: 10.1158/2159-8290.CD-22-1297. Cancer Discov. 2023. PMID: 37358260 Free PMC article.
-
Human Colon Cancer-Derived Clostridioides difficile Strains Drive Colonic Tumorigenesis in Mice.Cancer Discov. 2022 Aug 5;12(8):1873-1885. doi: 10.1158/2159-8290.CD-21-1273. Cancer Discov. 2022. PMID: 35678528 Free PMC article.
-
AI-Driven Quality Monitoring and Control in Stem Cell Cultures: A Comprehensive Review.Biotechnol J. 2025 Aug;20(8):e70100. doi: 10.1002/biot.70100. Biotechnol J. 2025. PMID: 40785233 Free PMC article. Review.
-
Oncogenic K-Ras suppresses global miRNA function.Mol Cell. 2023 Jul 20;83(14):2509-2523.e13. doi: 10.1016/j.molcel.2023.06.008. Epub 2023 Jul 3. Mol Cell. 2023. PMID: 37402366 Free PMC article.
References
-
- Banerjee A, Herring CA, Chen B, Kim H, Simmons AJ, Southard-Smith AN, Allaman MM, White JR, Macedonia MC, McKinley ET, et al. 2020. Succinate produced by intestinal microbes promotes specification of tuft cells to suppress ileal inflammation. Gastroenterology 159: 2101–2115.e5. 10.1053/j.gastro.2020.08.029 - DOI - PMC - PubMed
-
- Fleming SJ, Marioni JC, Babadi M. 2019. CellBender remove-background: a deep generative model for unsupervised removal of background noise from scRNA-seq datasets. bioRxiv 10.1101/791699 - DOI
-
- Hoerl AE, Kennard RW. 1970. Ridge regression: biased estimation for nonorthogonal problems. Technometrics 12: 55–67. 10.1080/00401706.1970.10488634 - DOI
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases