

Artificial intelligence to deep learning: machine intelligence approach for drug discovery
- PMID: 33844136
- PMCID: PMC8040371
- DOI: 10.1007/s11030-021-10217-3
Artificial intelligence to deep learning: machine intelligence approach for drug discovery
Abstract
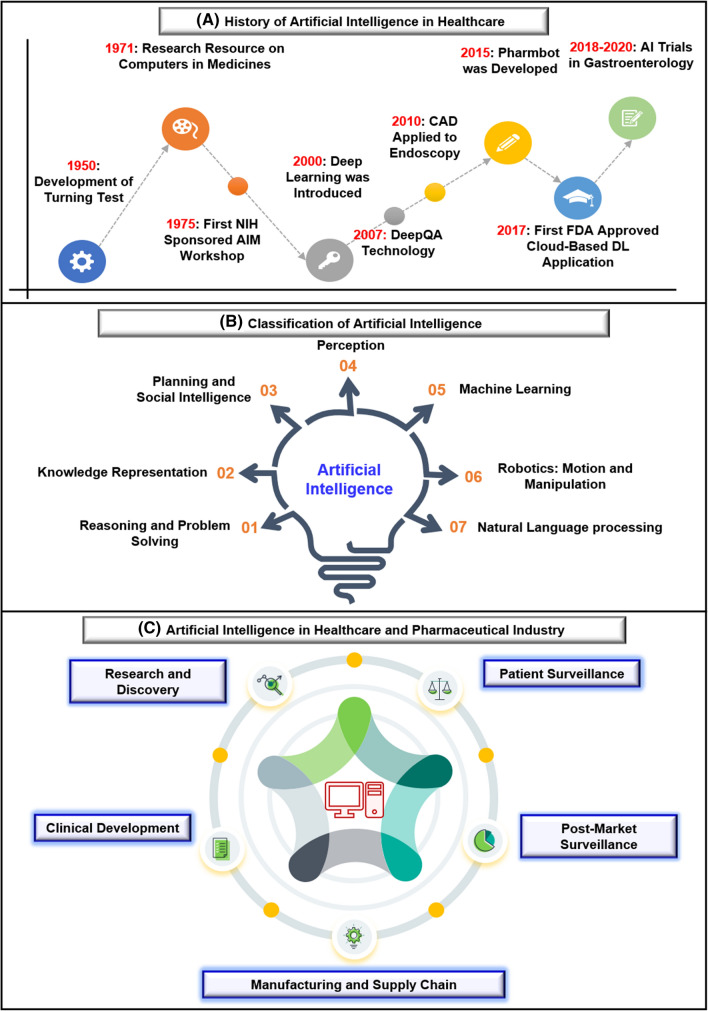
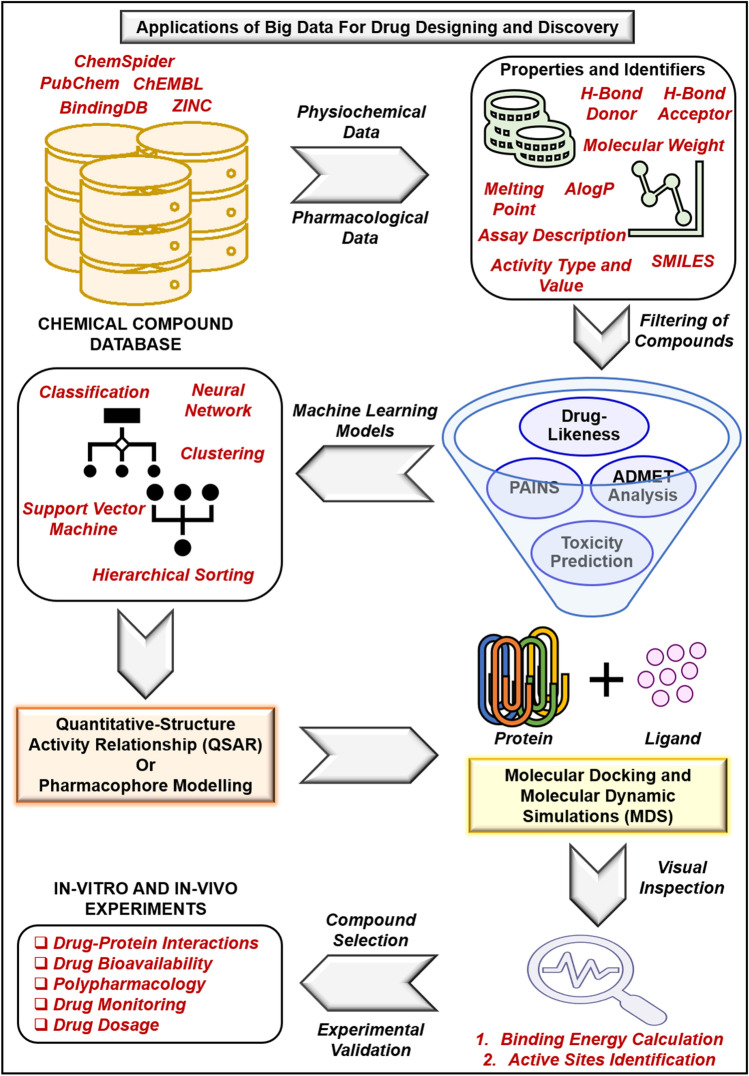
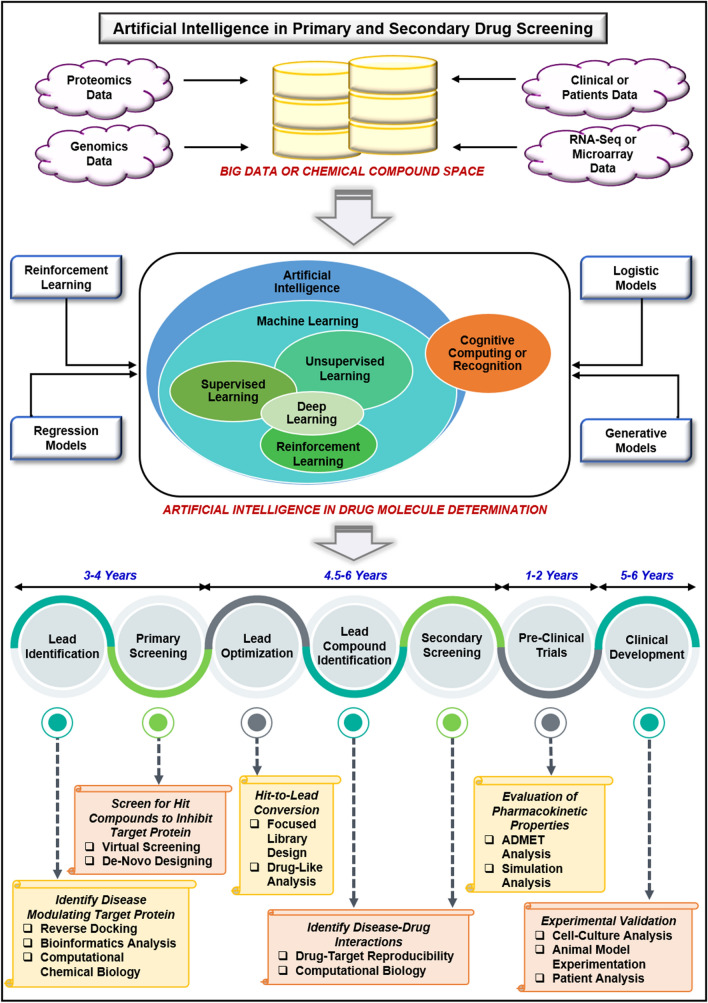
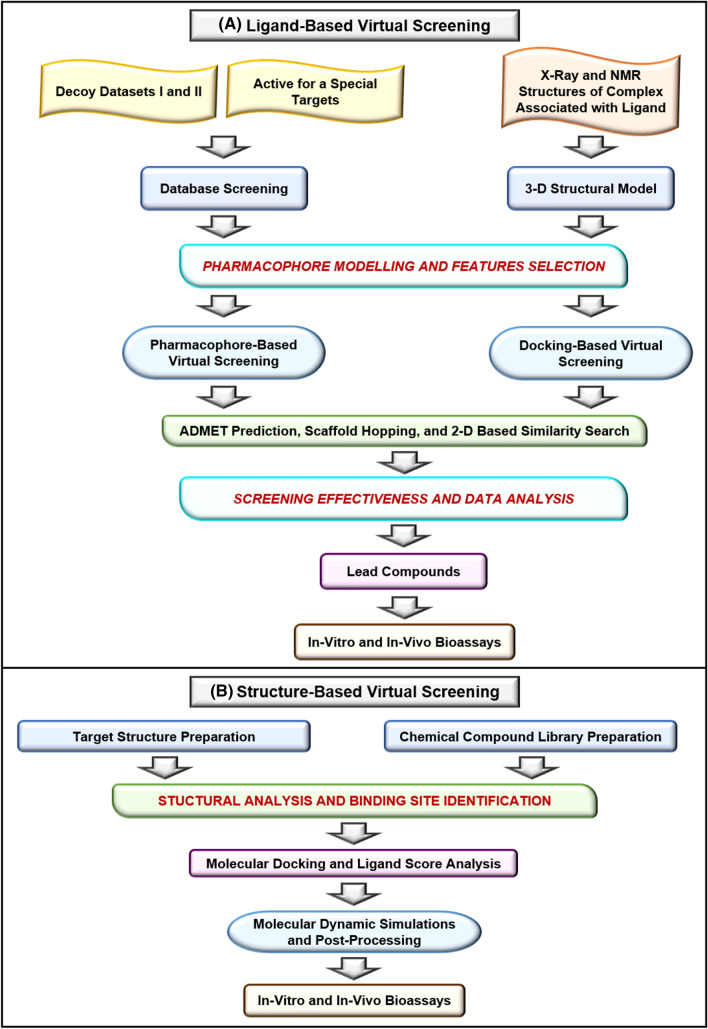
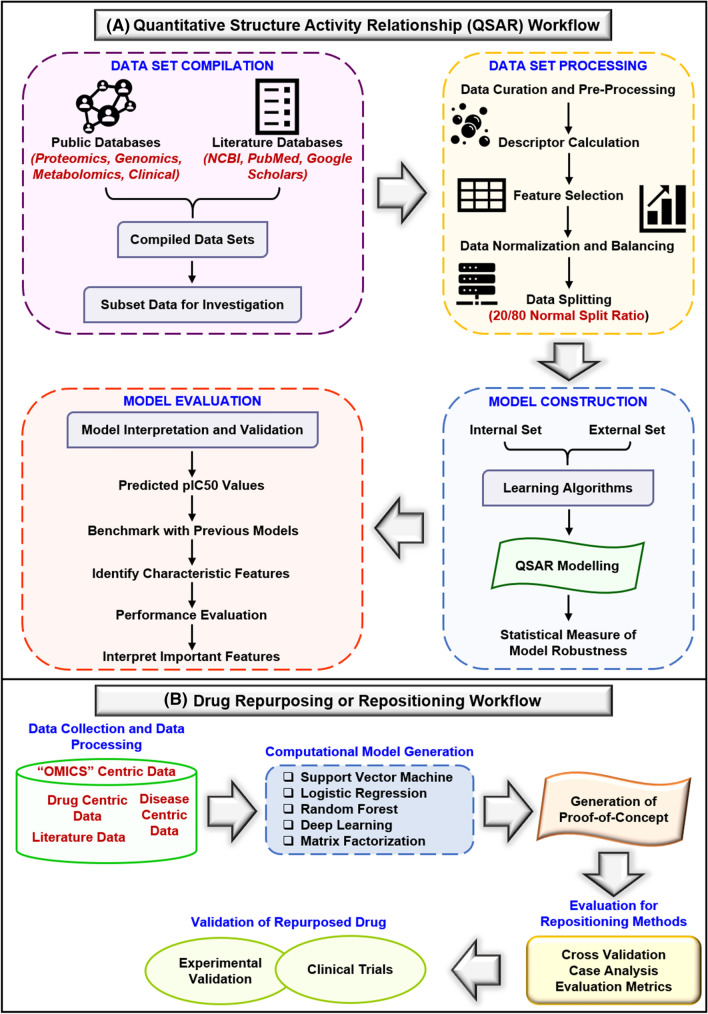
Drug designing and development is an important area of research for pharmaceutical companies and chemical scientists. However, low efficacy, off-target delivery, time consumption, and high cost impose a hurdle and challenges that impact drug design and discovery. Further, complex and big data from genomics, proteomics, microarray data, and clinical trials also impose an obstacle in the drug discovery pipeline. Artificial intelligence and machine learning technology play a crucial role in drug discovery and development. In other words, artificial neural networks and deep learning algorithms have modernized the area. Machine learning and deep learning algorithms have been implemented in several drug discovery processes such as peptide synthesis, structure-based virtual screening, ligand-based virtual screening, toxicity prediction, drug monitoring and release, pharmacophore modeling, quantitative structure-activity relationship, drug repositioning, polypharmacology, and physiochemical activity. Evidence from the past strengthens the implementation of artificial intelligence and deep learning in this field. Moreover, novel data mining, curation, and management techniques provided critical support to recently developed modeling algorithms. In summary, artificial intelligence and deep learning advancements provide an excellent opportunity for rational drug design and discovery process, which will eventually impact mankind. The primary concern associated with drug design and development is time consumption and production cost. Further, inefficiency, inaccurate target delivery, and inappropriate dosage are other hurdles that inhibit the process of drug delivery and development. With advancements in technology, computer-aided drug design integrating artificial intelligence algorithms can eliminate the challenges and hurdles of traditional drug design and development. Artificial intelligence is referred to as superset comprising machine learning, whereas machine learning comprises supervised learning, unsupervised learning, and reinforcement learning. Further, deep learning, a subset of machine learning, has been extensively implemented in drug design and development. The artificial neural network, deep neural network, support vector machines, classification and regression, generative adversarial networks, symbolic learning, and meta-learning are examples of the algorithms applied to the drug design and discovery process. Artificial intelligence has been applied to different areas of drug design and development process, such as from peptide synthesis to molecule design, virtual screening to molecular docking, quantitative structure-activity relationship to drug repositioning, protein misfolding to protein-protein interactions, and molecular pathway identification to polypharmacology. Artificial intelligence principles have been applied to the classification of active and inactive, monitoring drug release, pre-clinical and clinical development, primary and secondary drug screening, biomarker development, pharmaceutical manufacturing, bioactivity identification and physiochemical properties, prediction of toxicity, and identification of mode of action.
Keywords: Artificial intelligence; Artificial neural networks; Computer-aided drug design; Deep learning; Drug design and discovery; Drug repurposing; Machine learning; Quantitative structure–activity relationship; Virtual screening.
© 2021. The Author(s), under exclusive licence to Springer Nature Switzerland AG.
Conflict of interest statement
There is no conflict of interest declared by the authors.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
