

Enhancing Top-Down Proteomics of Brain Tissue with FAIMS
- PMID: 33856812
- PMCID: PMC8672206
- DOI: 10.1021/acs.jproteome.1c00049
Enhancing Top-Down Proteomics of Brain Tissue with FAIMS
Abstract
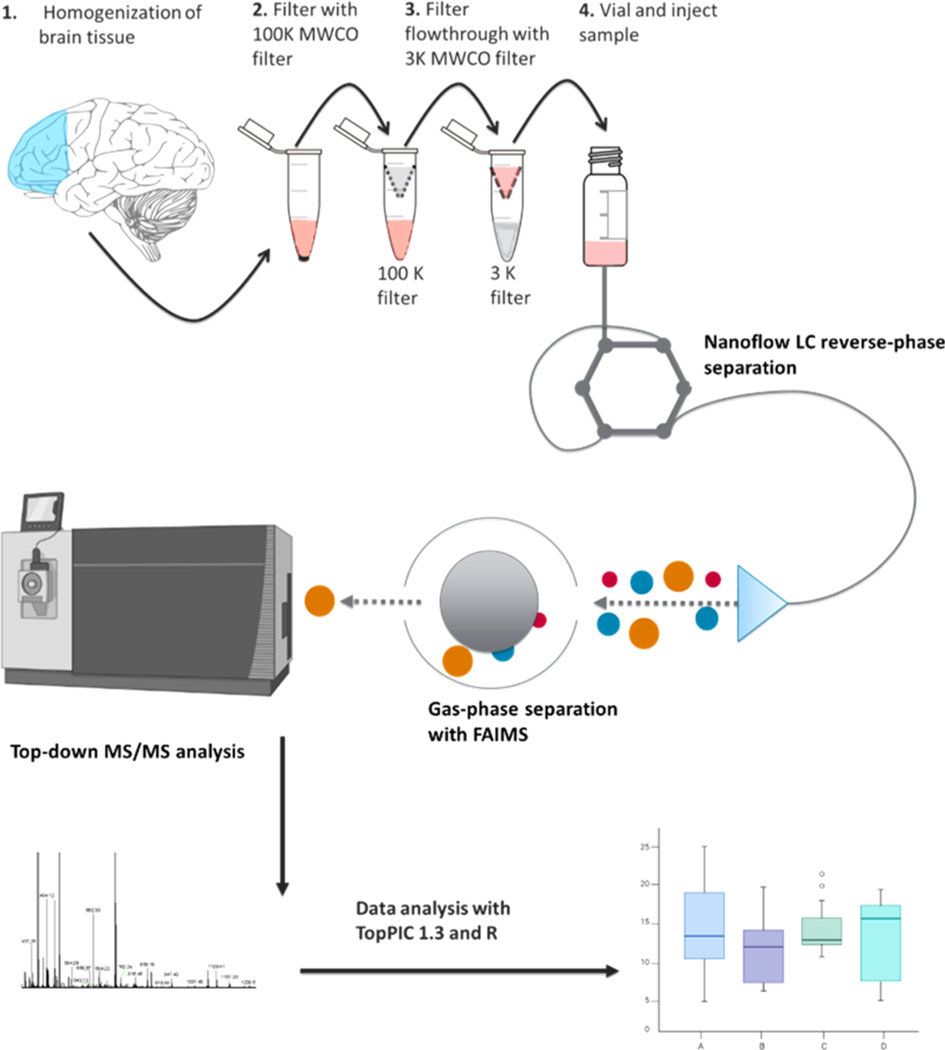
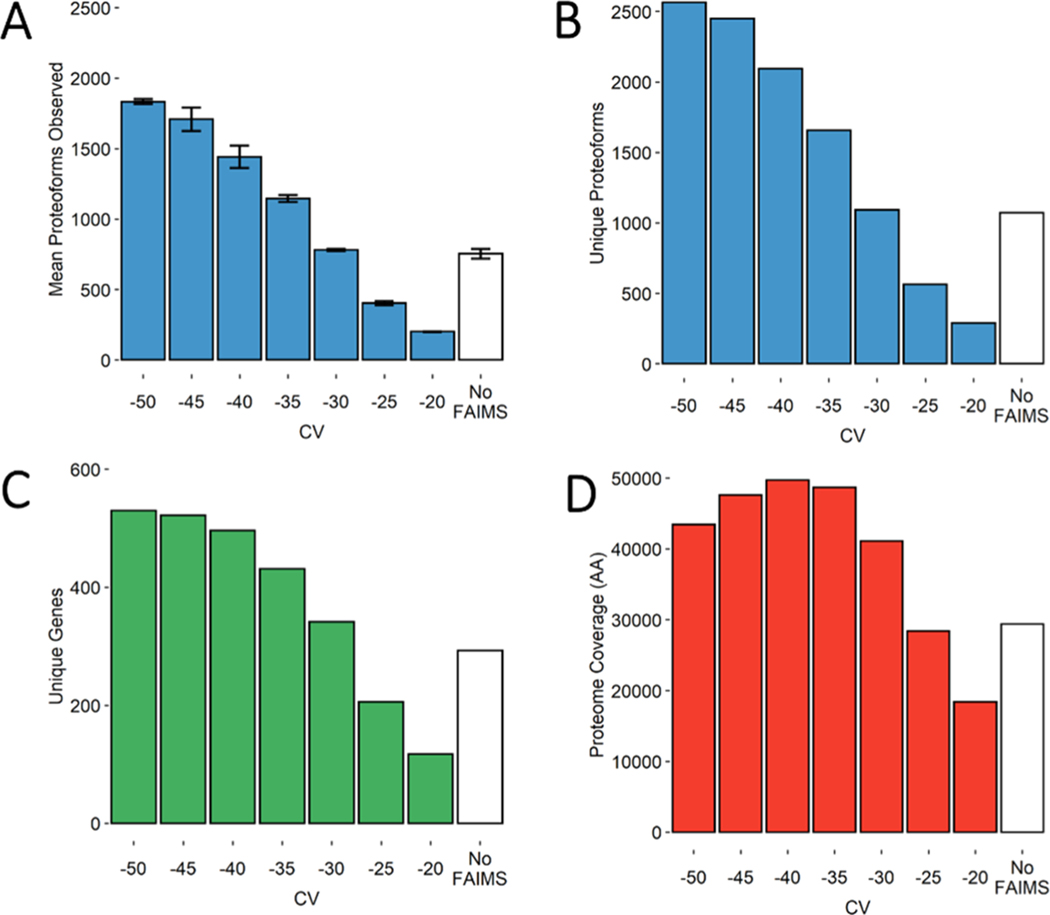
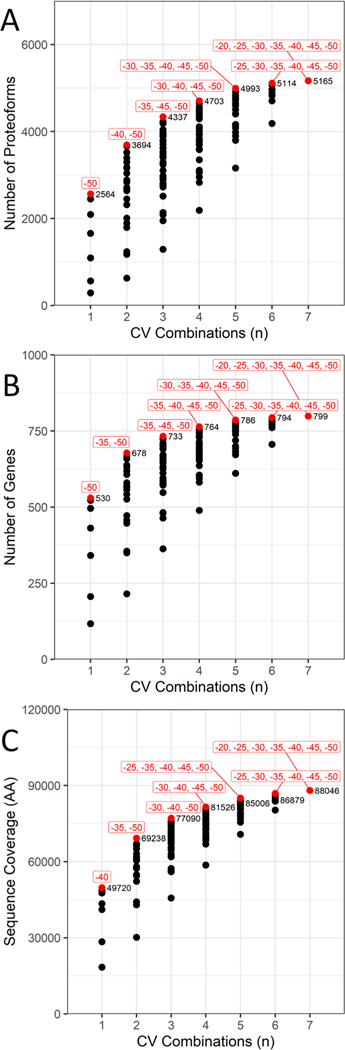
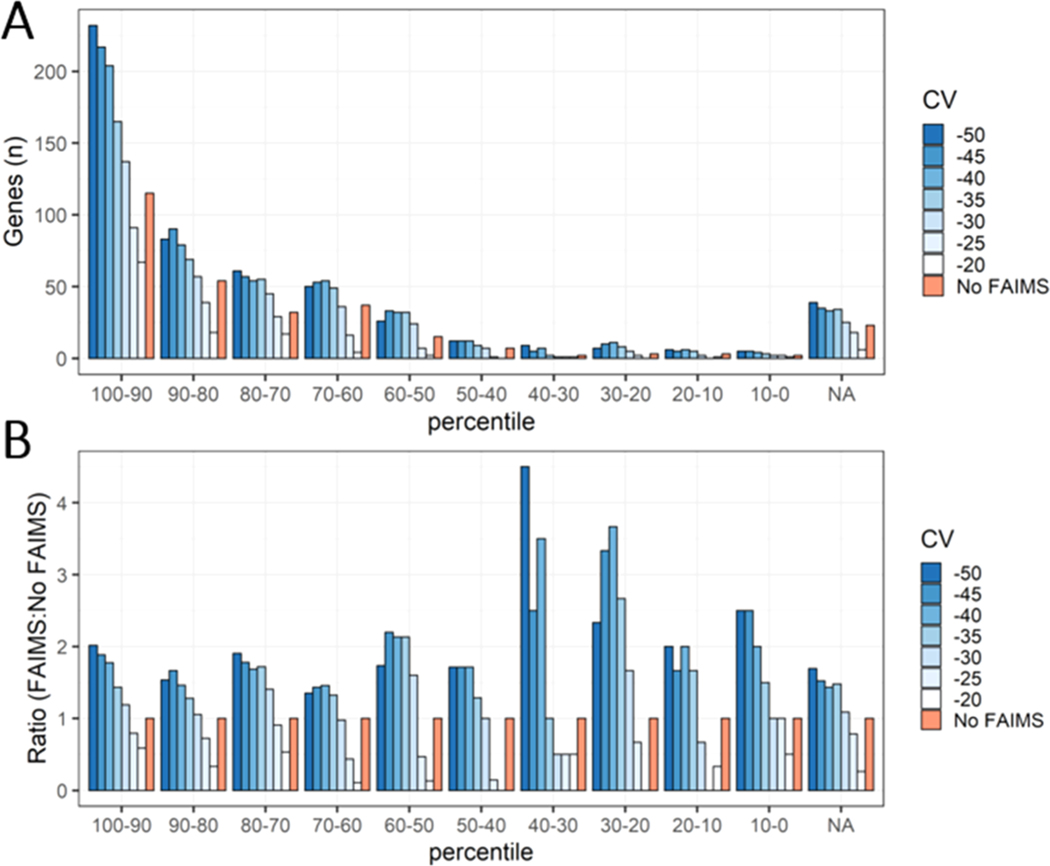
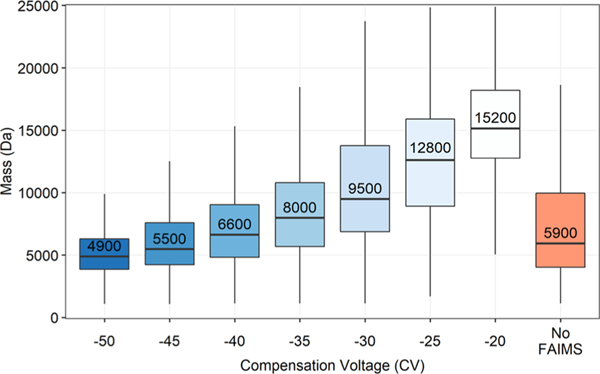
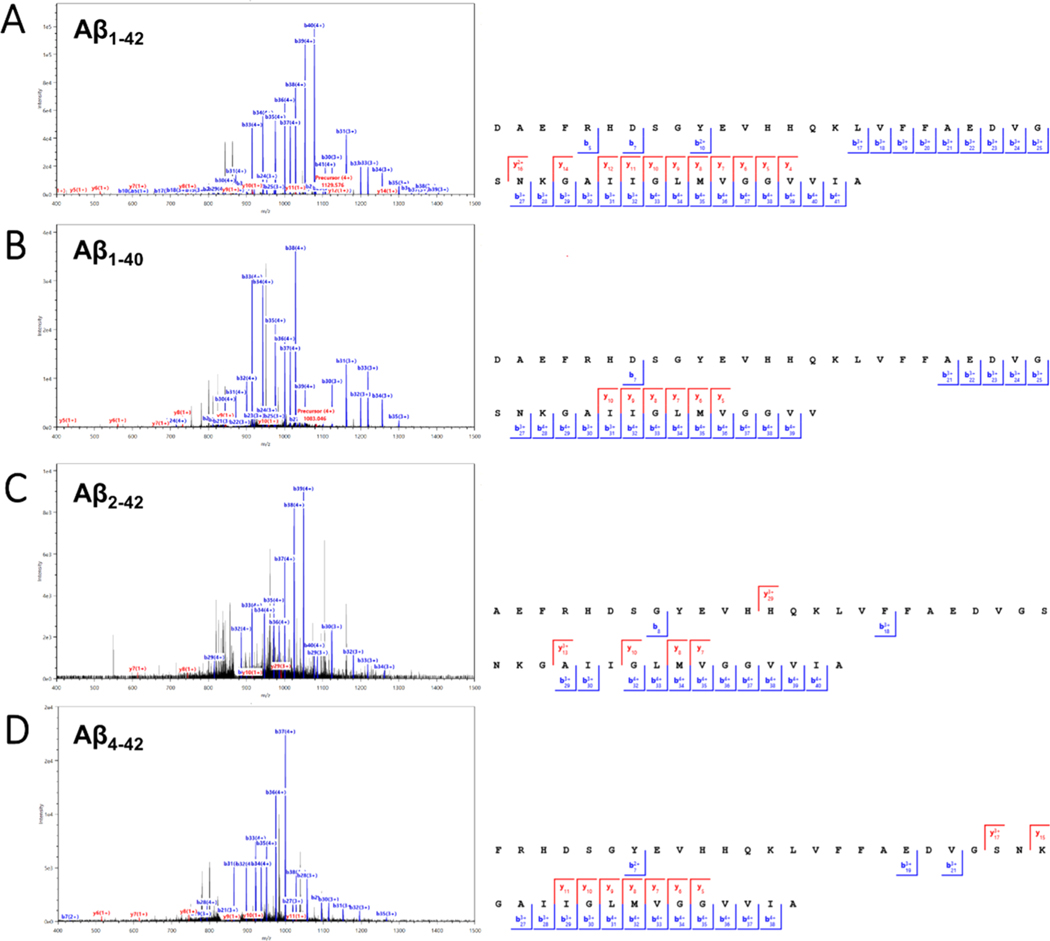
Proteomic investigations of Alzheimer's and Parkinson's disease have provided valuable insights into neurodegenerative disorders. Thus far, these investigations have largely been restricted to bottom-up approaches, hindering the degree to which one can characterize a protein's "intact" state. Top-down proteomics (TDP) overcomes this limitation; however, it is typically limited to observing only the most abundant proteoforms and of a relatively small size. Therefore, fractionation techniques are commonly used to reduce sample complexity. Here, we investigate gas-phase fractionation through high-field asymmetric waveform ion mobility spectrometry (FAIMS) within TDP. Utilizing a high complexity sample derived from Alzheimer's disease (AD) brain tissue, we describe how the addition of FAIMS to TDP can robustly improve the depth of proteome coverage. For example, implementation of FAIMS with external compensation voltage (CV) stepping at -50, -40, and -30 CV could more than double the mean number of non-redundant proteoforms, genes, and proteome sequence coverage compared to without FAIMS. We also found that FAIMS can influence the transmission of proteoforms and their charge envelopes based on their size. Importantly, FAIMS enabled the identification of intact amyloid beta (Aβ) proteoforms, including the aggregation-prone Aβ1-42 variant which is strongly linked to AD. Raw data and associated files have been deposited to the ProteomeXchange Consortium via the MassIVE data repository with data set identifier PXD023607.
Keywords: Alzheimer’s; FAIMS; brain tissue; differential mobility spectrometry; ion mobility; top-down proteomics.
Conflict of interest statement
The authors declare no competing financial interest.
Figures





References
-
- Nichols E; Szoeke CEI; Vollset SE; Abbasi N; Abd-Allah F; Abdela J; Aichour MTE; Akinyemi RO; Alahdab F; Asgedom SW; Awasthi A; Barker-Collo SL; Baune BT; Béjot Y; Belachew AB; Bennett DA; Biadgo B; Bijani A; Bin Sayeed MS; Brayne C; Carpenter DO; Carvalho F; Catalá-López F; Cerin E; Choi J-YJ; Dang AK; Degefa MG; Djalalinia S; Dubey M; Duken EE; Edvardsson D; Endres M; Eskandarieh S; Faro A; Farzadfar F; Fereshtehnejad S-M; Fernandes E; Filip I; Fischer F; Gebre AK; Geremew D; Ghasemi-Kasman M; Gnedovskaya EV; Gupta R; Hachinski V; Hagos TB; Hamidi S; Hankey GJ; Haro JM; Hay SI; Irvani SSN; Jha RP; Jonas JB; Kalani R; Karch A; Kasaeian A; Khader YS; Khalil IA; Khan EA; Khanna T; Khoja TAM; Khubchandani J; Kisa A; Kissimova-Skarbek K; Kivimäki M; Koyanagi A; Krohn KJ; Logroscino G; Lorkowski S; Majdan M; Malekzadeh R; März W; Massano J; Mengistu G; Meretoja A; Mohammadi M; Mohammadi-Khanaposhtani M; Mokdad AH; Mondello S; Moradi G; Nagel G; Naghavi M; Naik G; Nguyen LH; Nguyen TH; Nirayo YL; Nixon MR; Ofori-Asenso R; Ogbo FA; Olagunju AT; Owolabi MO; Panda-Jonas S; Passos V. M. d. A.; Pereira DM; Pinilla-Monsalve GD; Piradov MA; Pond CD; Poustchi H; Qorbani M; Radfar A; Reiner RC; Robinson SR; Roshandel G; Rostami A; Russ TC; Sachdev PS; Safari H; Safiri S; Sahathevan R; Salimi Y; Satpathy M; Sawhney M; Saylan M; Sepanlou SG; Shafieesabet A; Shaikh MA; Sahraian MA; Shigematsu M; Shiri R; Shiue I; Silva JP; Smith M; Sobhani S; Stein DJ; Tabarés-Seisdedos R; Tovani-Palone MR; Tran BX; Tran TT; Tsegay AT; Ullah I; Venketasubramanian N; Vlassov V; Wang Y-P; Weiss J; Westerman R; Wijeratne T; Wyper GMA; Yano Y; Yimer EM; Yonemoto N; Yousefifard M; Zaidi Z; Zare Z; Vos T; Feigin VL; Murray CJL Global, regional, and national burden of Alzheimer’s disease and other dementias, 1990–2016: a systematic analysis for the Global Burden of Disease Study 2016. Lancet Neurol. 2019, 18, 88–106. - PMC - PubMed
-
- Beyreuther K; Masters CL Amyloid precursor protein (APP) and beta A4 amyloid in the etiology of Alzheimer’s disease: precursor-product relationships in the derangement of neuronal function. Brain Pathol. 1991, 1, 241–251. - PubMed
-
- Hardy J; Higgins G. Alzheimer’s disease: the amyloid cascade hypothesis. Science 1992, 256, 184–185. - PubMed
-
- Goedert M. Tau protein and the neurofibrillary pathology of Alzheimer’s disease. Trends Neurosci. 1993, 16, 460–465. - PubMed
-
- Iqbal K; Liu F; Gong C-X Tau and neurodegenerative disease: the story so far. Nat. Rev. Neurol. 2016, 12, 15–27. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
