

Inferring the function performed by a recurrent neural network
- PMID: 33857170
- PMCID: PMC8049287
- DOI: 10.1371/journal.pone.0248940
Inferring the function performed by a recurrent neural network
Abstract
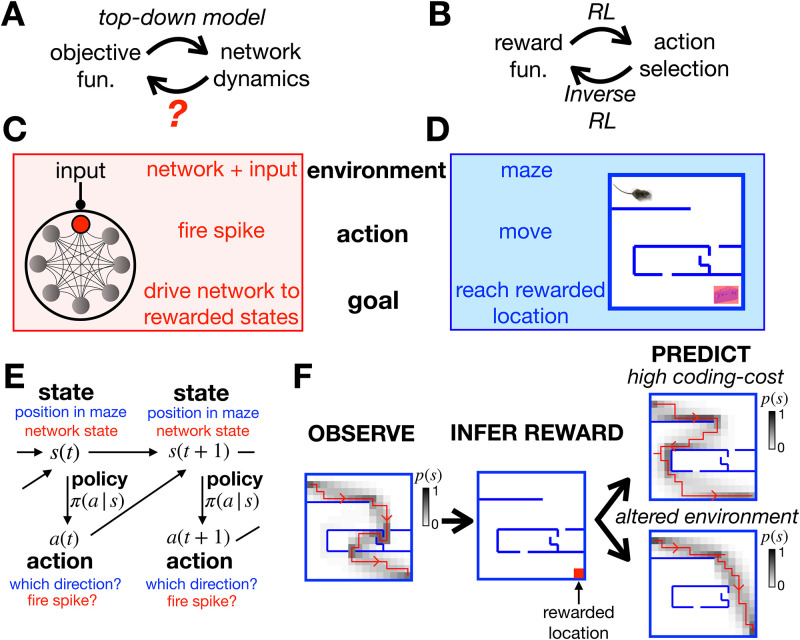
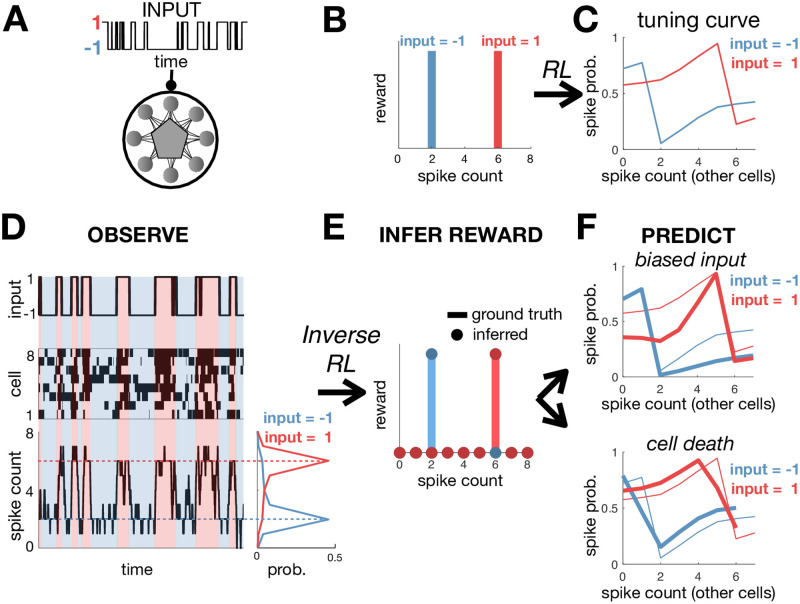
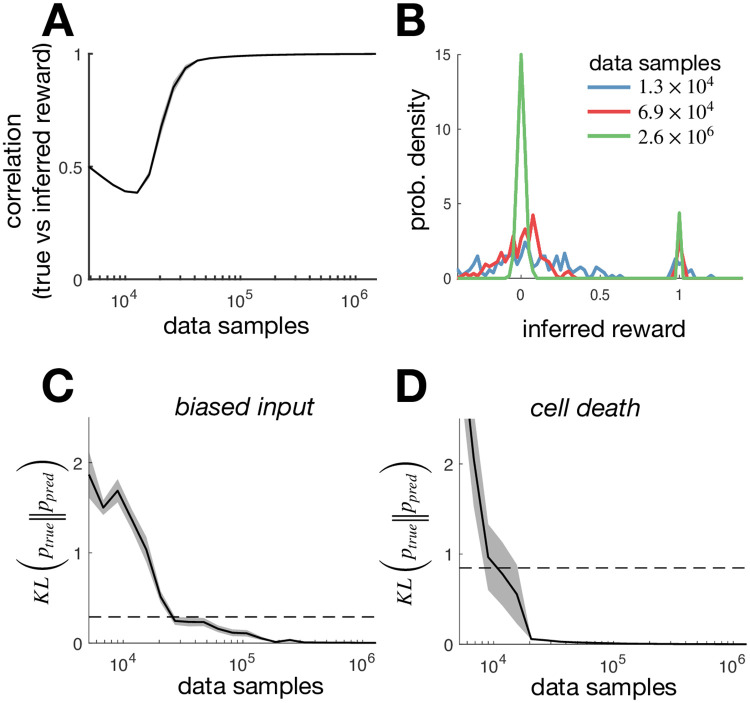
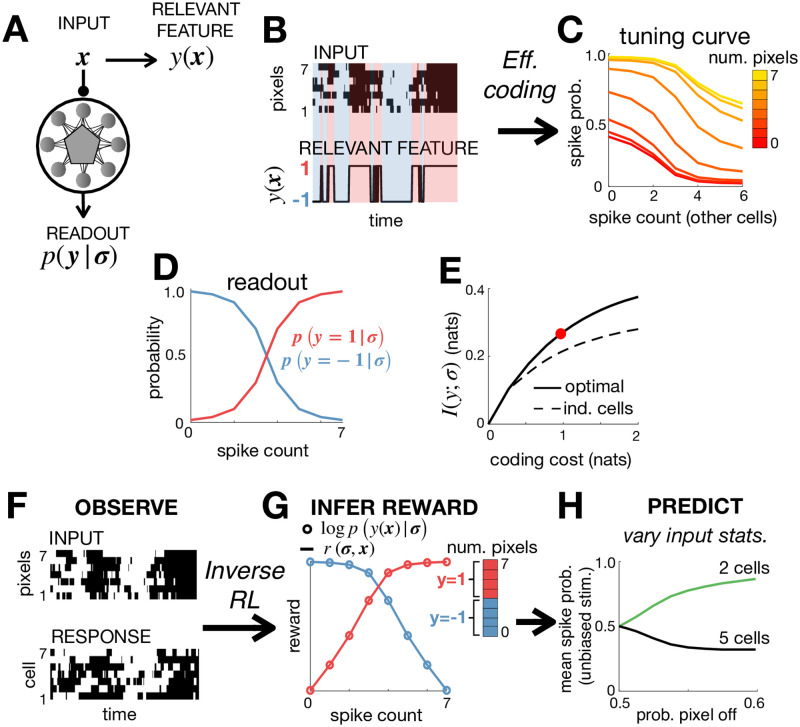
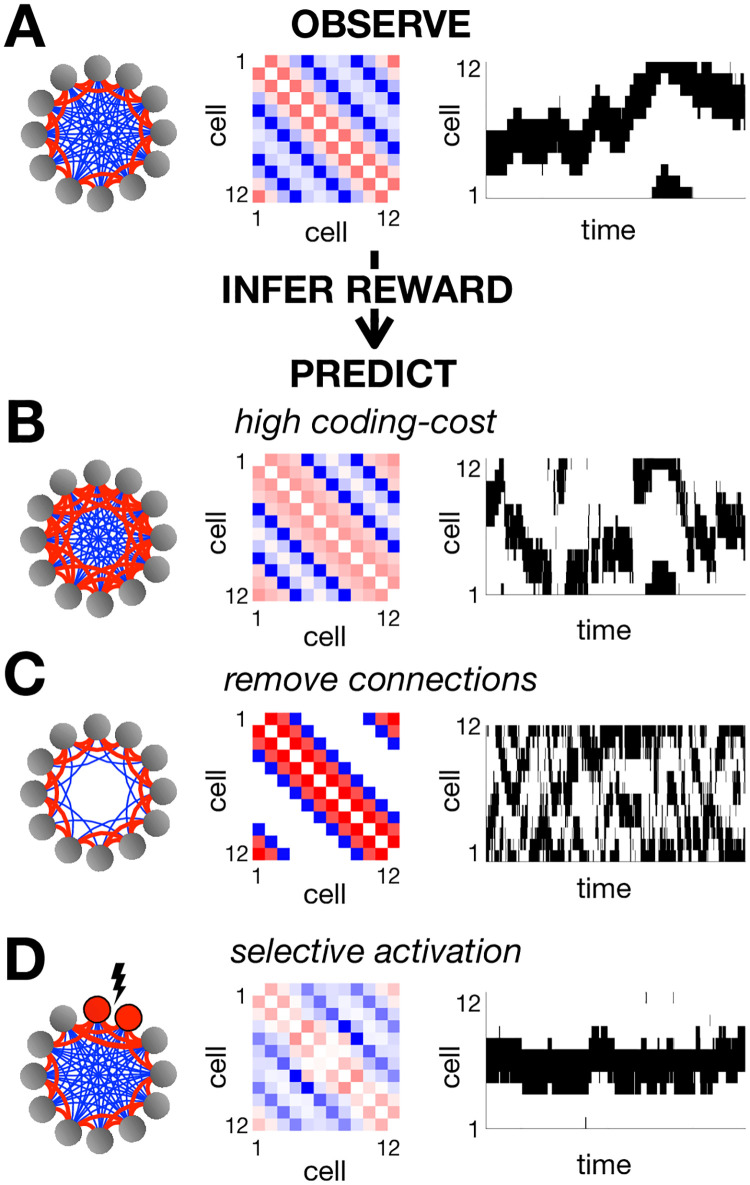
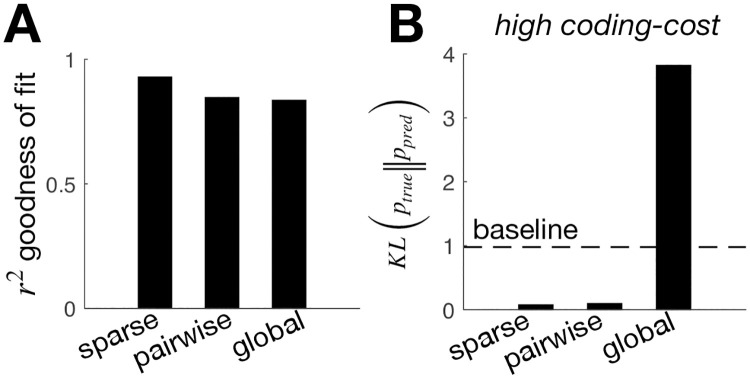
A central goal in systems neuroscience is to understand the functions performed by neural circuits. Previous top-down models addressed this question by comparing the behaviour of an ideal model circuit, optimised to perform a given function, with neural recordings. However, this requires guessing in advance what function is being performed, which may not be possible for many neural systems. To address this, we propose an inverse reinforcement learning (RL) framework for inferring the function performed by a neural network from data. We assume that the responses of each neuron in a network are optimised so as to drive the network towards 'rewarded' states, that are desirable for performing a given function. We then show how one can use inverse RL to infer the reward function optimised by the network from observing its responses. This inferred reward function can be used to predict how the neural network should adapt its dynamics to perform the same function when the external environment or network structure changes. This could lead to theoretical predictions about how neural network dynamics adapt to deal with cell death and/or varying sensory stimulus statistics.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
