

Critical assessment of protein intrinsic disorder prediction
- PMID: 33875885
- PMCID: PMC8105172
- DOI: 10.1038/s41592-021-01117-3
Critical assessment of protein intrinsic disorder prediction
Abstract
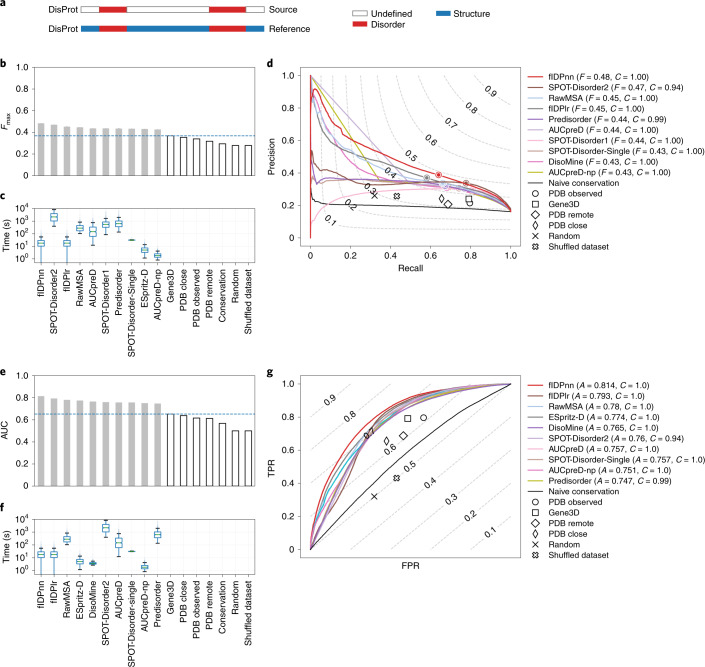
Intrinsically disordered proteins, defying the traditional protein structure-function paradigm, are a challenge to study experimentally. Because a large part of our knowledge rests on computational predictions, it is crucial that their accuracy is high. The Critical Assessment of protein Intrinsic Disorder prediction (CAID) experiment was established as a community-based blind test to determine the state of the art in prediction of intrinsically disordered regions and the subset of residues involved in binding. A total of 43 methods were evaluated on a dataset of 646 proteins from DisProt. The best methods use deep learning techniques and notably outperform physicochemical methods. The top disorder predictor has Fmax = 0.483 on the full dataset and Fmax = 0.792 following filtering out of bona fide structured regions. Disordered binding regions remain hard to predict, with Fmax = 0.231. Interestingly, computing times among methods can vary by up to four orders of magnitude.
Conflict of interest statement
The authors declare no competing interests.
Figures



Comment in
-
A community effort to bring structure to disorder.Nat Methods. 2021 May;18(5):454-455. doi: 10.1038/s41592-021-01123-5. Nat Methods. 2021. PMID: 33875888 No abstract available.
References
-
- Tompa, P. & Fersht, A. Structure and Function of Intrinsically Disordered Proteins (CRC Press, 2009).
-
- Dunker AK, Bondos SE, Huang F, Oldfield CJ. Intrinsically disordered proteins and multicellular organisms. Semin. Cell Dev. Biol. 2015;37:44–55. - PubMed
-
- Ward JJ, Sodhi JS, McGuffin LJ, Buxton BF, Jones DT. Prediction and functional analysis of native disorder in proteins from the three kingdoms of life. J. Mol. Biol. 2004;337:635–645. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
