

Annotation and initial evaluation of a large annotated German oncological corpus
- PMID: 33898938
- PMCID: PMC8054032
- DOI: 10.1093/jamiaopen/ooab025
Annotation and initial evaluation of a large annotated German oncological corpus
Abstract
Objective: We present the Berlin-Tübingen-Oncology corpus (BRONCO), a large and freely available corpus of shuffled sentences from German oncological discharge summaries annotated with diagnosis, treatments, medications, and further attributes including negation and speculation. The aim of BRONCO is to foster reproducible and openly available research on Information Extraction from German medical texts.
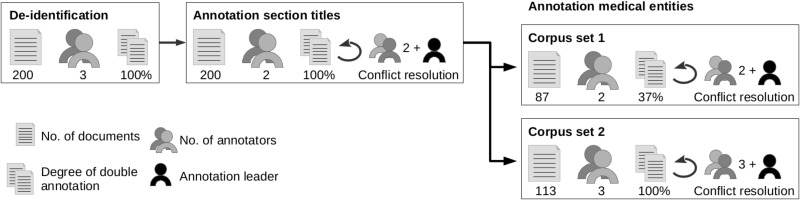
Materials and methods: BRONCO consists of 200 manually deidentified discharge summaries of cancer patients. Annotation followed a structured and quality-controlled process involving 2 groups of medical experts to ensure consistency, comprehensiveness, and high quality of annotations. We present results of several state-of-the-art techniques for different IE tasks as baselines for subsequent research.
Results: The annotated corpus consists of 11 434 sentences and 89 942 tokens, annotated with 11 124 annotations for medical entities and 3118 annotations of related attributes. We publish 75% of the corpus as a set of shuffled sentences, and keep 25% as held-out data set for unbiased evaluation of future IE tools. On this held-out dataset, our baselines reach depending on the specific entity types F1-scores of 0.72-0.90 for named entity recognition, 0.10-0.68 for entity normalization, 0.55 for negation detection, and 0.33 for speculation detection.
Discussion: Medical corpus annotation is a complex and time-consuming task. This makes sharing of such resources even more important.
Conclusion: To our knowledge, BRONCO is the first sizable and freely available German medical corpus. Our baseline results show that more research efforts are necessary to lift the quality of information extraction in German medical texts to the level already possible for English.
Keywords: German language; corpus annotation; medical information extraction.
© The Author(s) 2021. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures


References
-
- Jensen PB, Jensen LJ, Brunak S.. Mining electronic health records: towards better research applications and clinical care. Nat Rev Genet 2012; 13 (6): 395–405. - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases