

The Need for a Human Pangenome Reference Sequence
- PMID: 33929893
- PMCID: PMC8410644
- DOI: 10.1146/annurev-genom-120120-081921
The Need for a Human Pangenome Reference Sequence
Abstract
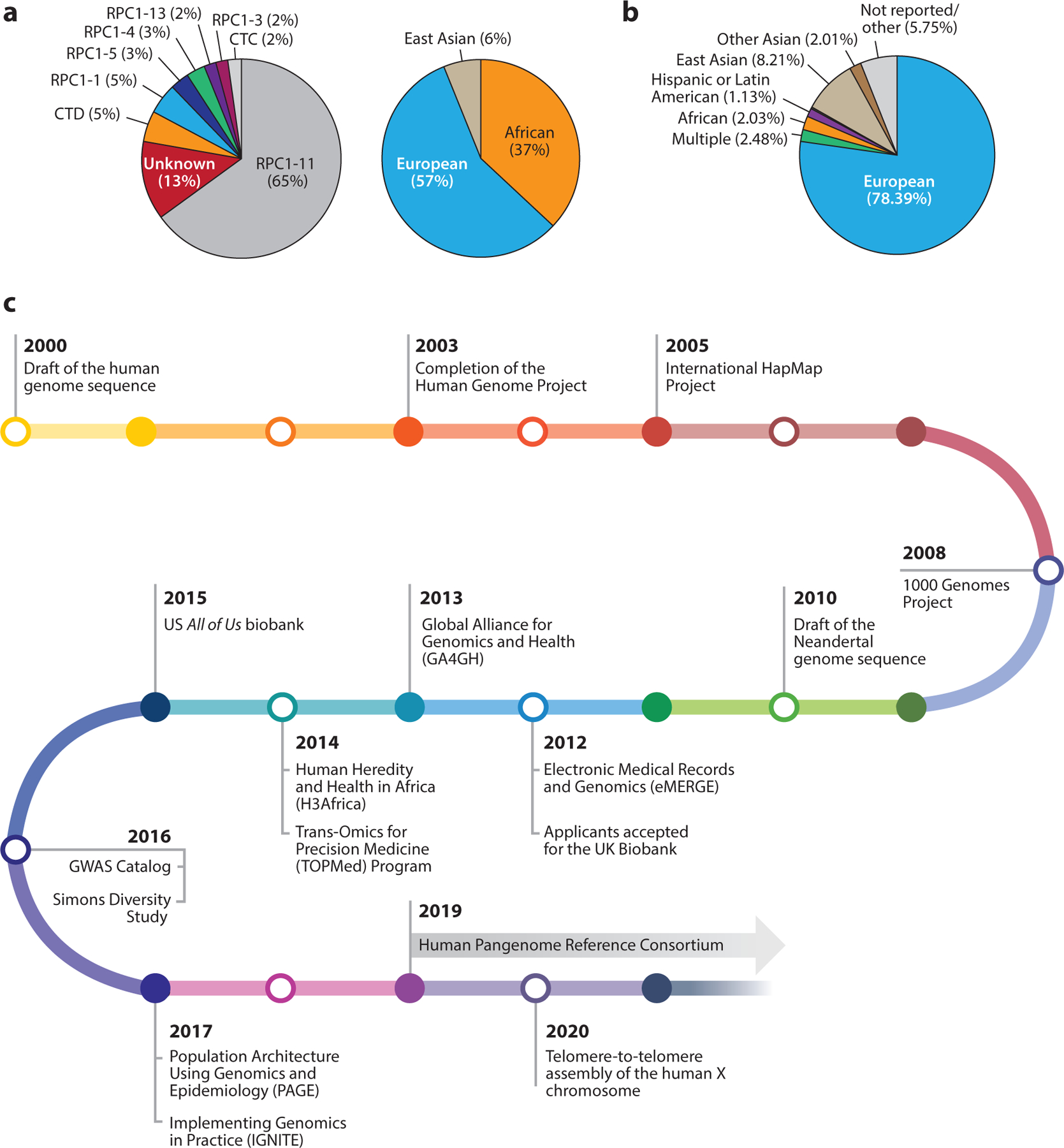
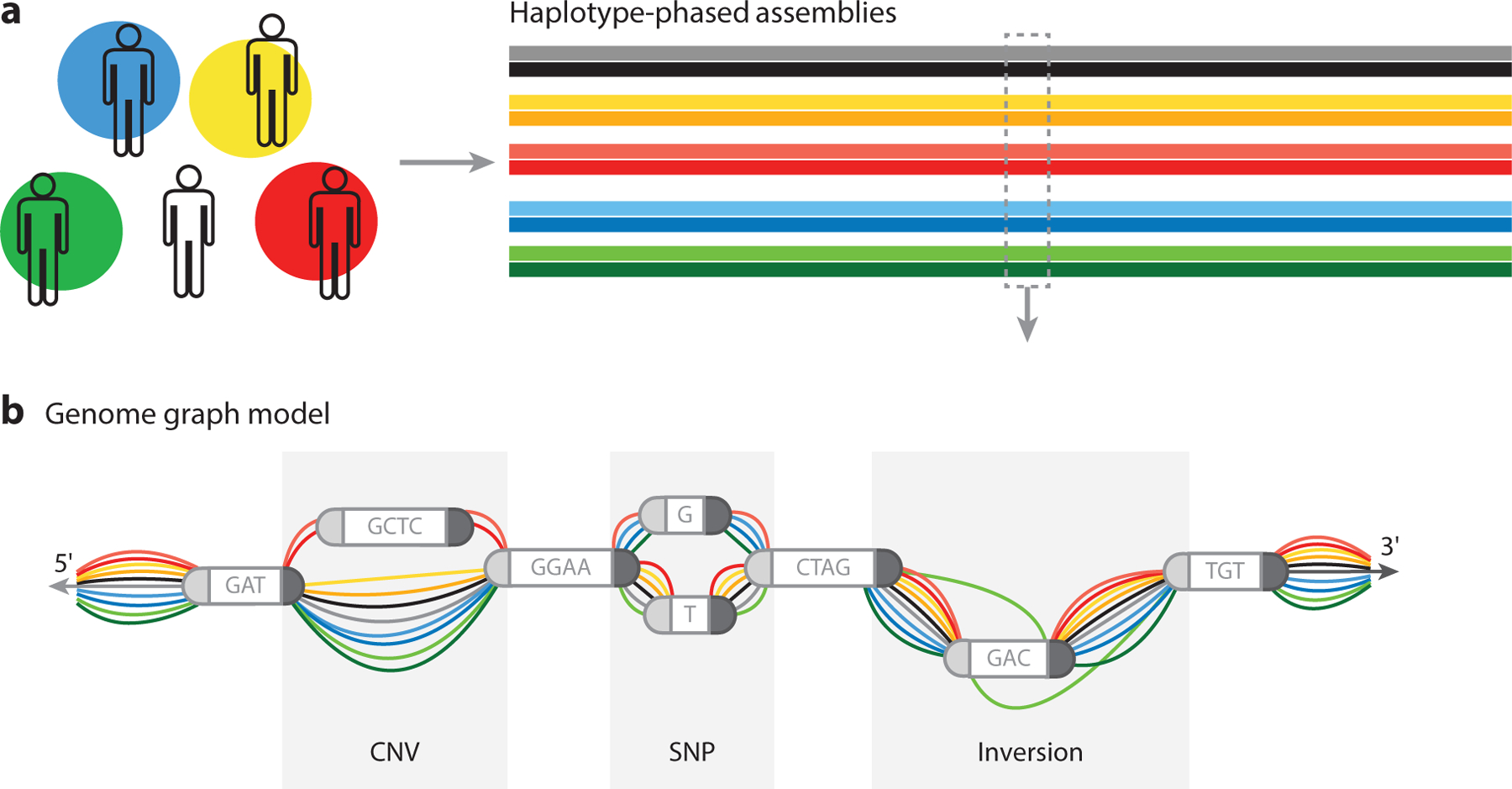
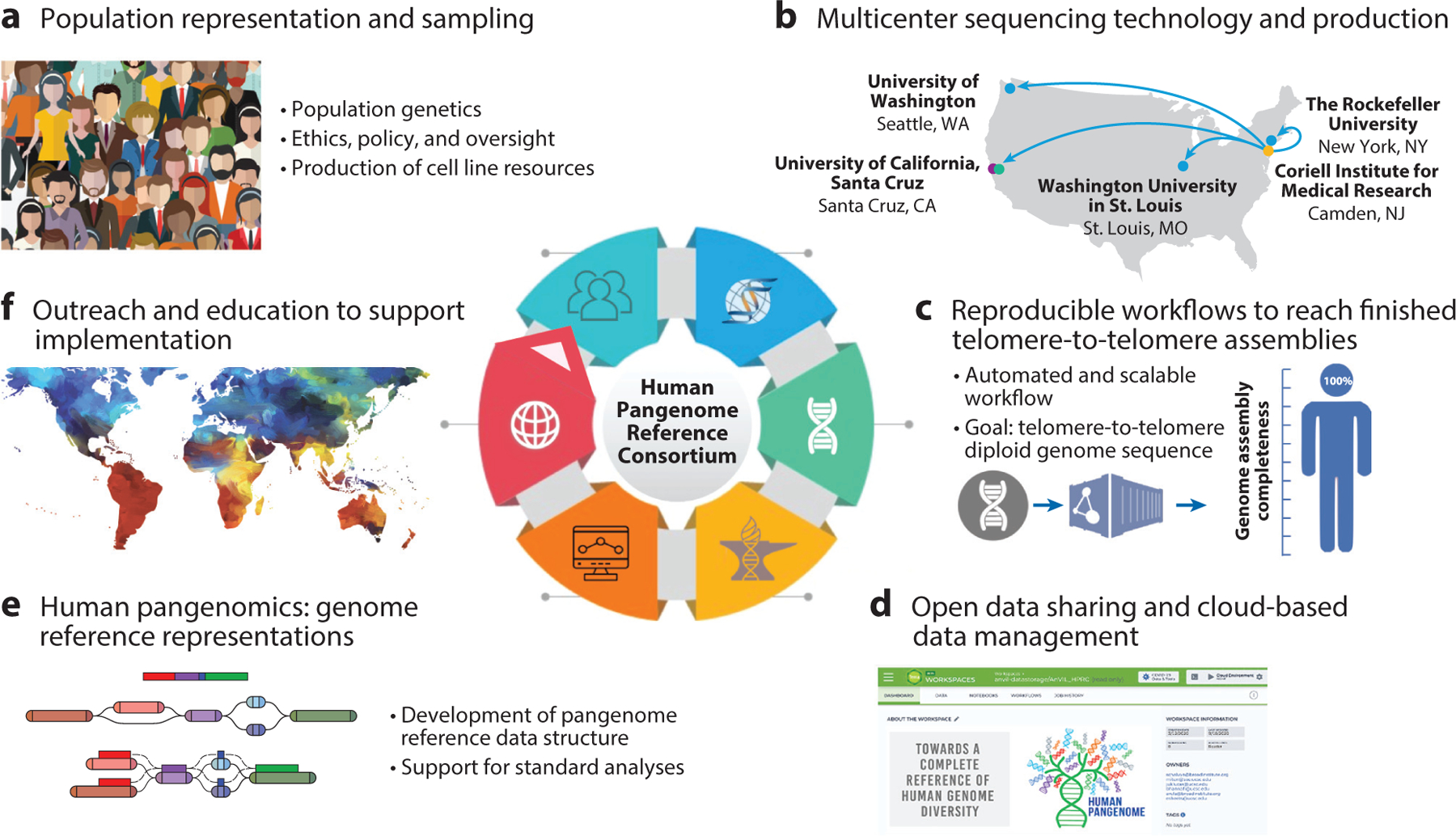
The reference human genome sequence is inarguably the most important and widely used resource in the fields of human genetics and genomics. It has transformed the conduct of biomedical sciences and brought invaluable benefits to the understanding and improvement of human health. However, the commonly used reference sequence has profound limitations, because across much of its span, it represents the sequence of just one human haplotype. This single, monoploid reference structure presents a critical barrier to representing the broad genomic diversity in the human population. In this review, we discuss the modernization of the reference human genome sequence to a more complete reference of human genomic diversity, known as a human pangenome.
Keywords: Human Genome Project; clinical genomics; diversity; pangenome.
Figures
References
-
- Abe M, Ishikawa O, Miyachi Y. 1998. Lupoid sycosis successfully treated with minocycline. Br. J. Dermatol 138:199–200 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
