

Comparison of Short-Read Sequence Aligners Indicates Strengths and Weaknesses for Biologists to Consider
- PMID: 33936141
- PMCID: PMC8087178
- DOI: 10.3389/fpls.2021.657240
Comparison of Short-Read Sequence Aligners Indicates Strengths and Weaknesses for Biologists to Consider
Abstract
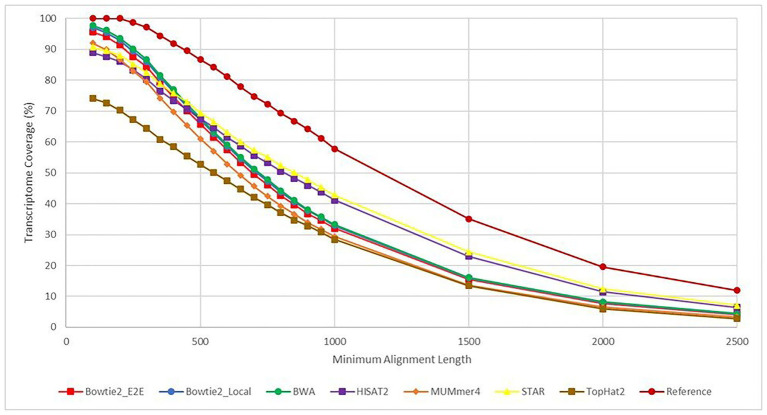
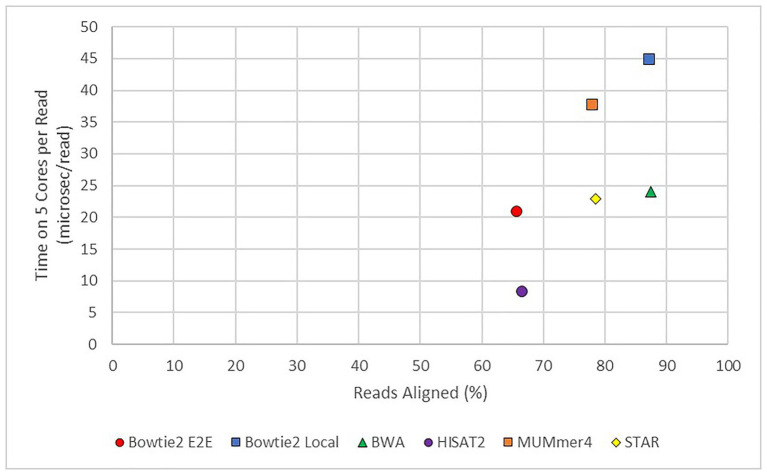
Aligning short-read sequences is the foundational step to most genomic and transcriptomic analyses, but not all tools perform equally, and choosing among the growing body of available tools can be daunting. Here, in order to increase awareness in the research community, we discuss the merits of common algorithms and programs in a way that should be approachable to biologists with limited experience in bioinformatics. We will only in passing consider the effects of data cleanup, a precursor analysis to most alignment tools, and no consideration will be given to downstream processing of the aligned fragments. To compare aligners [Bowtie2, Burrows Wheeler Aligner (BWA), HISAT2, MUMmer4, STAR, and TopHat2], an RNA-seq dataset was used containing data from 48 geographically distinct samples of the grapevine powdery mildew fungus Erysiphe necator. Based on alignment rate and gene coverage, all aligners performed well with the exception of TopHat2, which HISAT2 superseded. BWA perhaps had the best performance in these metrics, except for longer transcripts (>500 bp) for which HISAT2 and STAR performed well. HISAT2 was ~3-fold faster than the next fastest aligner in runtime, which we consider a secondary factor in most alignments. At the end, this direct comparison of commonly used aligners illustrates key considerations when choosing which tool to use for the specific sequencing data and objectives. No single tool meets all needs for every user, and there are many quality aligners available.
Keywords: accuracy; alignment; comparison; runtime; short-read sequencing.
Copyright © 2021 Musich, Cadle-Davidson and Osier.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
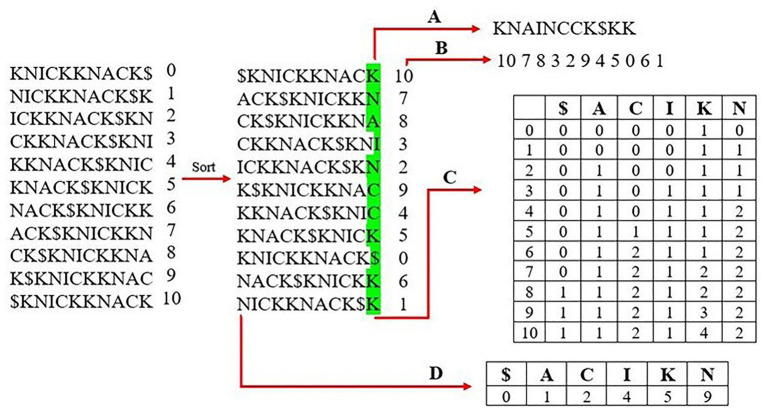
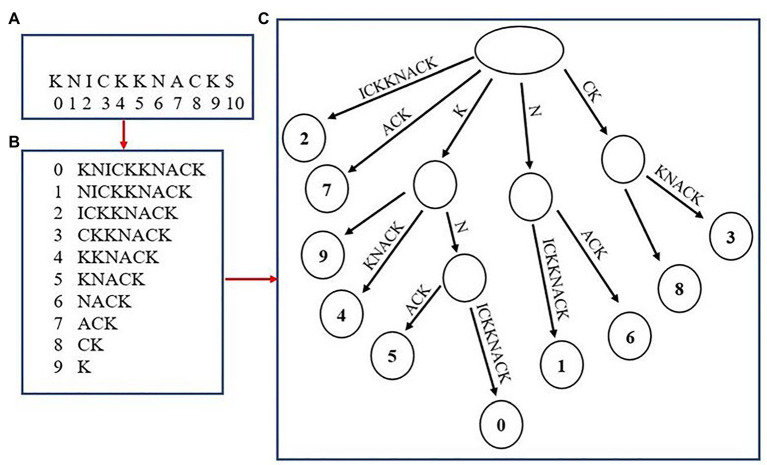
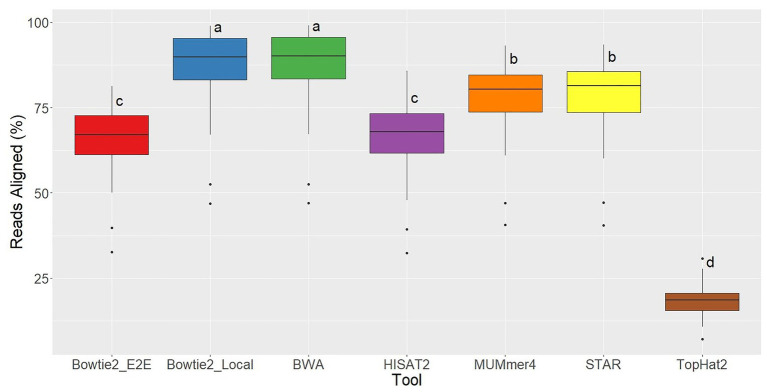
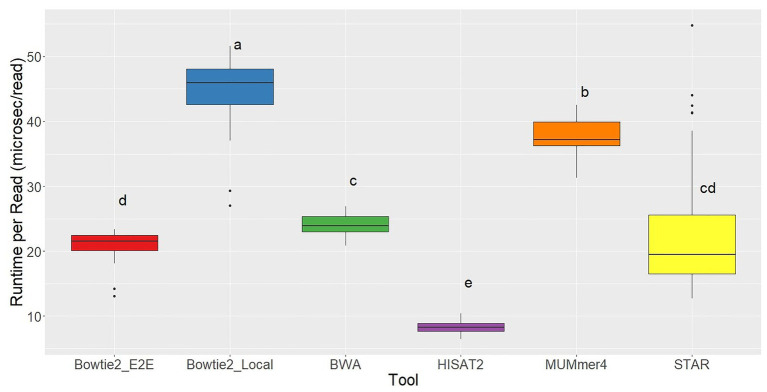
References
-
- Andrews S. (2018). FastQC (v0.11.7). Available at: https://www.bioinformatics.babraham.ac.uk/projects/fastqc/ (Accessed May 1, 2020).
-
- Cadle-Davidson L., Wakefield L., Seem R. C., Gadoury D. M. (2009). Specific isolation of RNA from the grape powdery mildew pathogen Erysiphe necator, an epiphytic, obligate parasite. J. Phytopathol. 158, 69–71. 10.1111/j.1439-0434.2009.01578.x - DOI
LinkOut - more resources
Full Text Sources
Other Literature Sources