

The virtual loss function in the summary perception of motion and its limited adjustability
- PMID: 33944907
- PMCID: PMC8107510
- DOI: 10.1167/jov.21.5.2
The virtual loss function in the summary perception of motion and its limited adjustability
Abstract
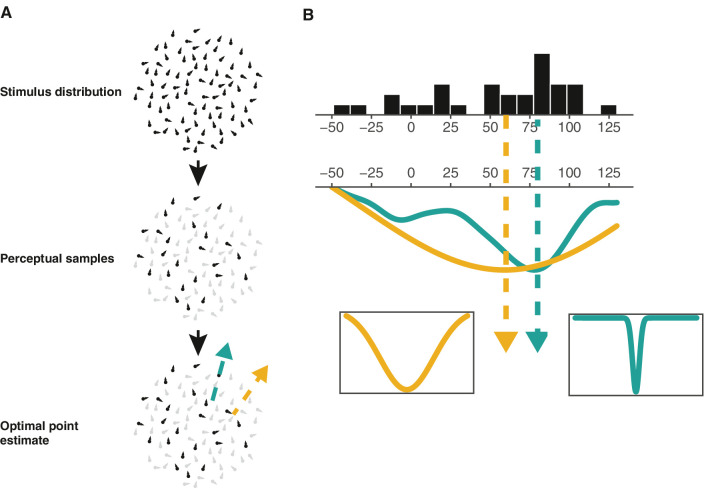
Humans can grasp the "average" feature of a visual ensemble quickly and effortlessly. However, it is largely unknown what is the exact form of the summary statistic humans perceive and it is even less known whether this form can be changed by feedback. Here we borrow the concept of loss function to characterize how the summary perception is related to the distribution of feature values in the ensemble, assuming that the summary statistic minimizes a virtual expected loss associated with its deviation from individual feature values. In two experiments, we investigated a random-dot motion estimation task to infer the virtual loss function implicit in ensemble perception and see whether it can be changed by feedback. On each trial, participants reported the average moving direction of an ensemble of moving dots whose distribution of moving directions was skewed. In Experiment 1, where no feedback was available, participants' estimates fell between the mean and the mode of the distribution and were closer to the mean. In particular, the deviation from the mean and toward the mode increased almost linearly with the mode-to-mean distance. The pattern was best modeled by an inverse Gaussian loss function, which punishes large errors less heavily than the quadratic loss function does. In Experiment 2, we tested whether this virtual loss function can be altered by feedback. Two groups of participants either received the mode or the mean as the correct answer. After extensive training up to five days, both groups' estimates moved slightly towards the mode. That is, feedback had no specific influence on participants' virtual loss function. To conclude, the virtual loss function in the summary perception of motion is close to inverse Gaussian, and it can hardly be changed by feedback.
Figures




References
-
- Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control , 19(6), 716–723, doi: 10.1109/TAC.1974.1100705. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
