

AI-assisted superresolution cosmological simulations
- PMID: 33947816
- PMCID: PMC8126773
- DOI: 10.1073/pnas.2022038118
AI-assisted superresolution cosmological simulations
Abstract
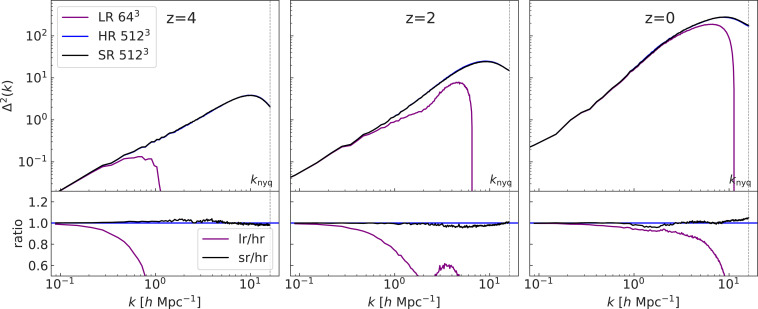
Cosmological simulations of galaxy formation are limited by finite computational resources. We draw from the ongoing rapid advances in artificial intelligence (AI; specifically deep learning) to address this problem. Neural networks have been developed to learn from high-resolution (HR) image data and then make accurate superresolution (SR) versions of different low-resolution (LR) images. We apply such techniques to LR cosmological N-body simulations, generating SR versions. Specifically, we are able to enhance the simulation resolution by generating 512 times more particles and predicting their displacements from the initial positions. Therefore, our results can be viewed as simulation realizations themselves, rather than projections, e.g., to their density fields. Furthermore, the generation process is stochastic, enabling us to sample the small-scale modes conditioning on the large-scale environment. Our model learns from only 16 pairs of small-volume LR-HR simulations and is then able to generate SR simulations that successfully reproduce the HR matter power spectrum to percent level up to [Formula: see text] and the HR halo mass function to within [Formula: see text] down to [Formula: see text] We successfully deploy the model in a box 1,000 times larger than the training simulation box, showing that high-resolution mock surveys can be generated rapidly. We conclude that AI assistance has the potential to revolutionize modeling of small-scale galaxy-formation physics in large cosmological volumes.
Keywords: cosmology; deep learning; simulation; super resolution.
Conflict of interest statement
The authors declare no competing interest.
Figures







References
-
- Vogelsberger M., Marinacci F., Torrey P., Puchwein E., Cosmological simulations of galaxy formation. Nat. Rev. Phys. 2, 42–66 (2020).
-
- Russell S. J., Norvig P., Artificial Intelligence: A Modern Approach (Pearson Series in Artificial Intelligence, Pearson, Upper Saddle River, NJ, ed. 4, 2020).
-
- Feng Y., et al. , The formation of Milky Way-mass disk galaxies in the first 500 million years of a cold dark matter universe. Acta Pathol. Jpn. 808, L17 (2015).
-
- Goodfellow I., Bengio Y., Courville A., Deep Learning (MIT Press, Cambridge, MA, 2016).
-
- Goodfellow I., et al. , Generative adversarial nets. Adv. Neural Information Processing Systems 27, 2672–2680 (2014).
Publication types
LinkOut - more resources
Full Text Sources
Research Materials
