

Continuous learning of emergent behavior in robotic matter
- PMID: 33972408
- PMCID: PMC8166149
- DOI: 10.1073/pnas.2017015118
Continuous learning of emergent behavior in robotic matter
Abstract
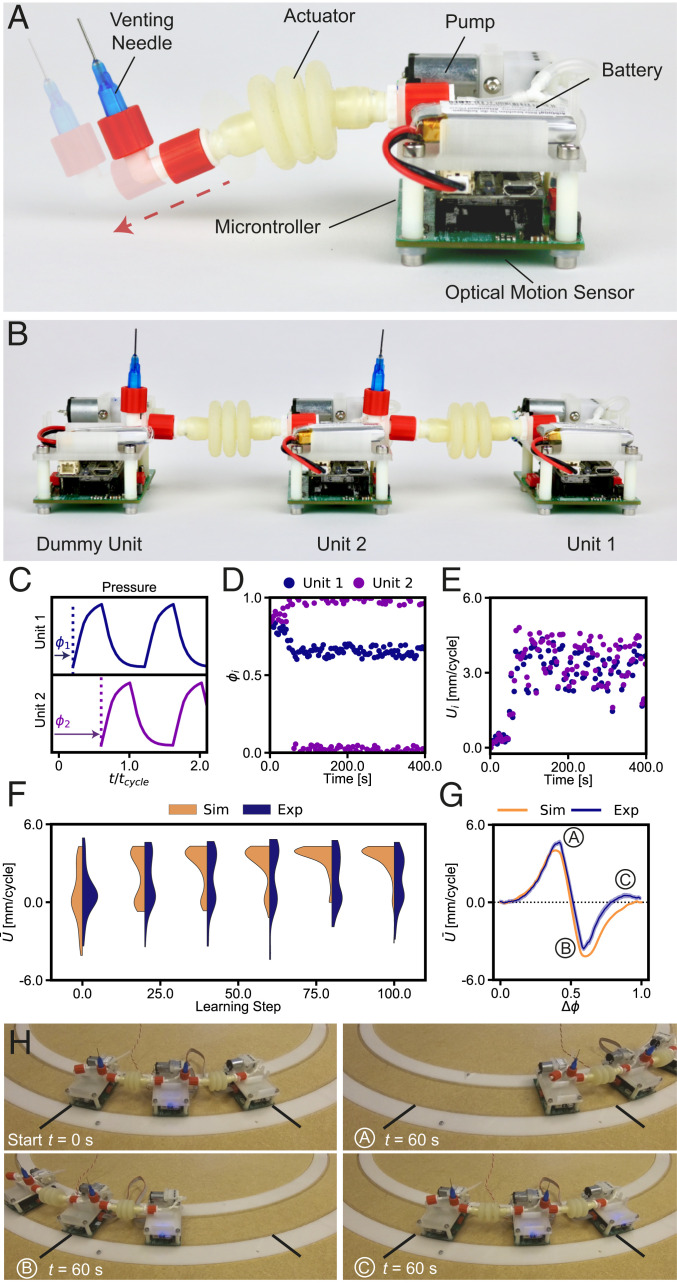
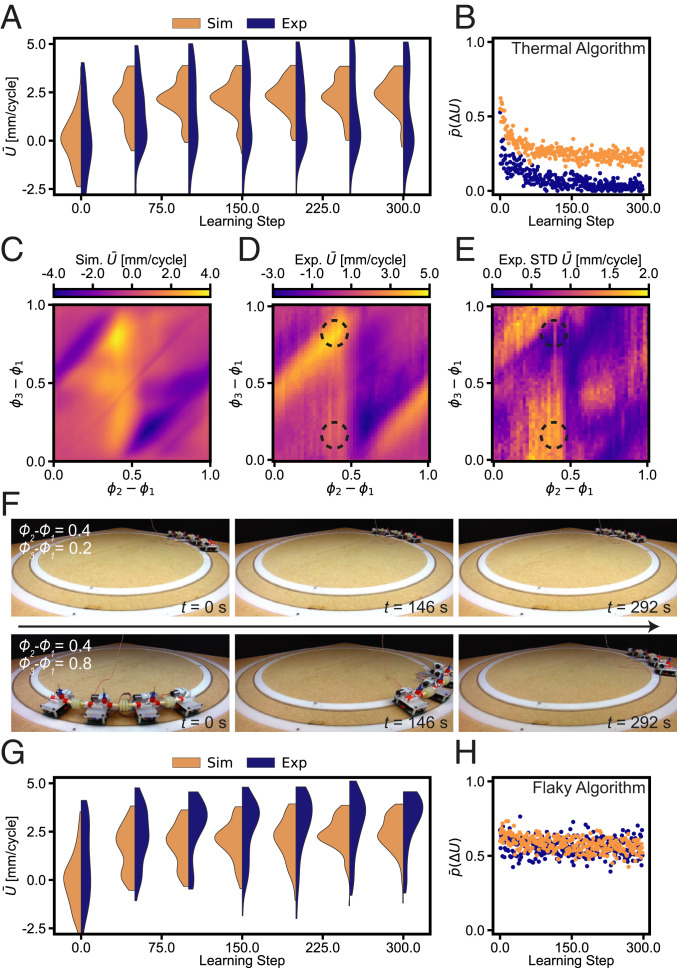
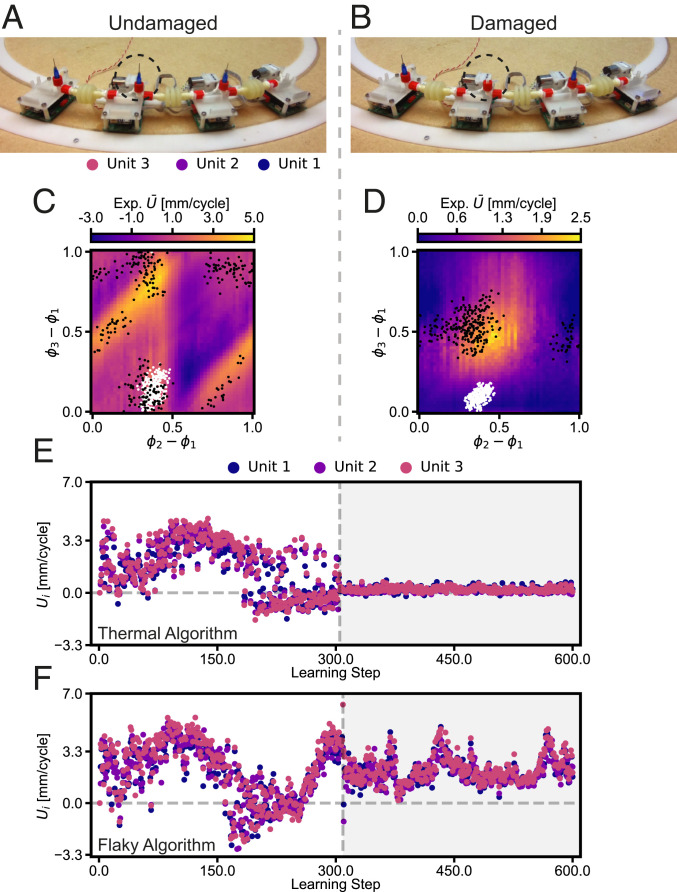
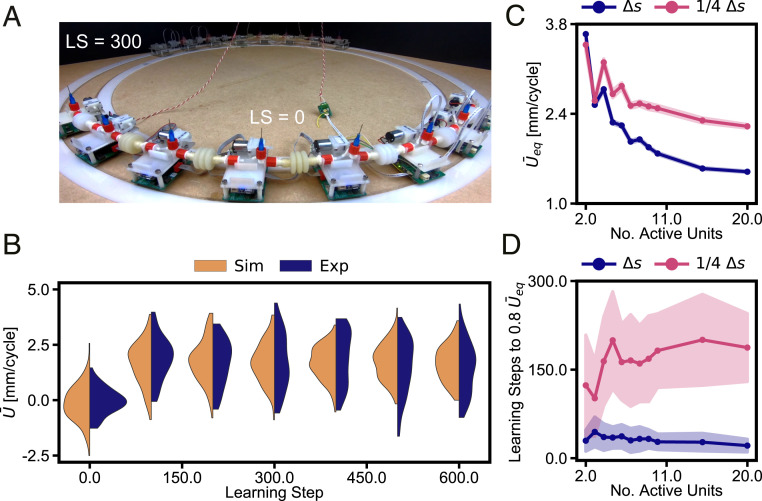
One of the main challenges in robotics is the development of systems that can adapt to their environment and achieve autonomous behavior. Current approaches typically aim to achieve this by increasing the complexity of the centralized controller by, e.g., direct modeling of their behavior, or implementing machine learning. In contrast, we simplify the controller using a decentralized and modular approach, with the aim of finding specific requirements needed for a robust and scalable learning strategy in robots. To achieve this, we conducted experiments and simulations on a specific robotic platform assembled from identical autonomous units that continuously sense their environment and react to it. By letting each unit adapt its behavior independently using a basic Monte Carlo scheme, the assembled system is able to learn and maintain optimal behavior in a dynamic environment as long as its memory is representative of the current environment, even when incurring damage. We show that the physical connection between the units is enough to achieve learning, and no additional communication or centralized information is required. As a result, such a distributed learning approach can be easily scaled to larger assemblies, blurring the boundaries between materials and robots, paving the way for a new class of modular "robotic matter" that can autonomously learn to thrive in dynamic or unfamiliar situations, for example, encountered by soft robots or self-assembled (micro)robots in various environments spanning from the medical realm to space explorations.
Keywords: dynamic environment; emergent behavior; modular robot; reinforced learning.
Copyright © 2021 the Author(s). Published by PNAS.
Conflict of interest statement
The authors declare no competing interest.
Figures
References
-
- Hwangbo J., et al. , Learning agile and dynamic motor skills for legged robots. Sci. Robot. 4, eaau5872 (2019). - PubMed
-
- Kwiatkowski R., Lipson H., Task-agnostic self-modeling machines. Sci. Robot. 4, eaau9354 (2019). - PubMed
-
- Rus D., Tolley M. T., Design, fabrication and control of soft robots. Nature 521, 467–475 (2015). - PubMed
-
- Cully A., Clune J., Tarapore D., Mouret J.-B., Robots that can adapt like animals. Nature 521, 503–507 (2015). - PubMed
-
- Haarnoja T., et al. ., Learning to walk via deep reinforcement learning. arXiv [Preprint] (2018). https://arxiv.org/abs/1812.11103v3 (Accessed 1 May 2020).
Publication types
Associated data
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
