

High-performance brain-to-text communication via handwriting
- PMID: 33981047
- PMCID: PMC8163299
- DOI: 10.1038/s41586-021-03506-2
High-performance brain-to-text communication via handwriting
Abstract
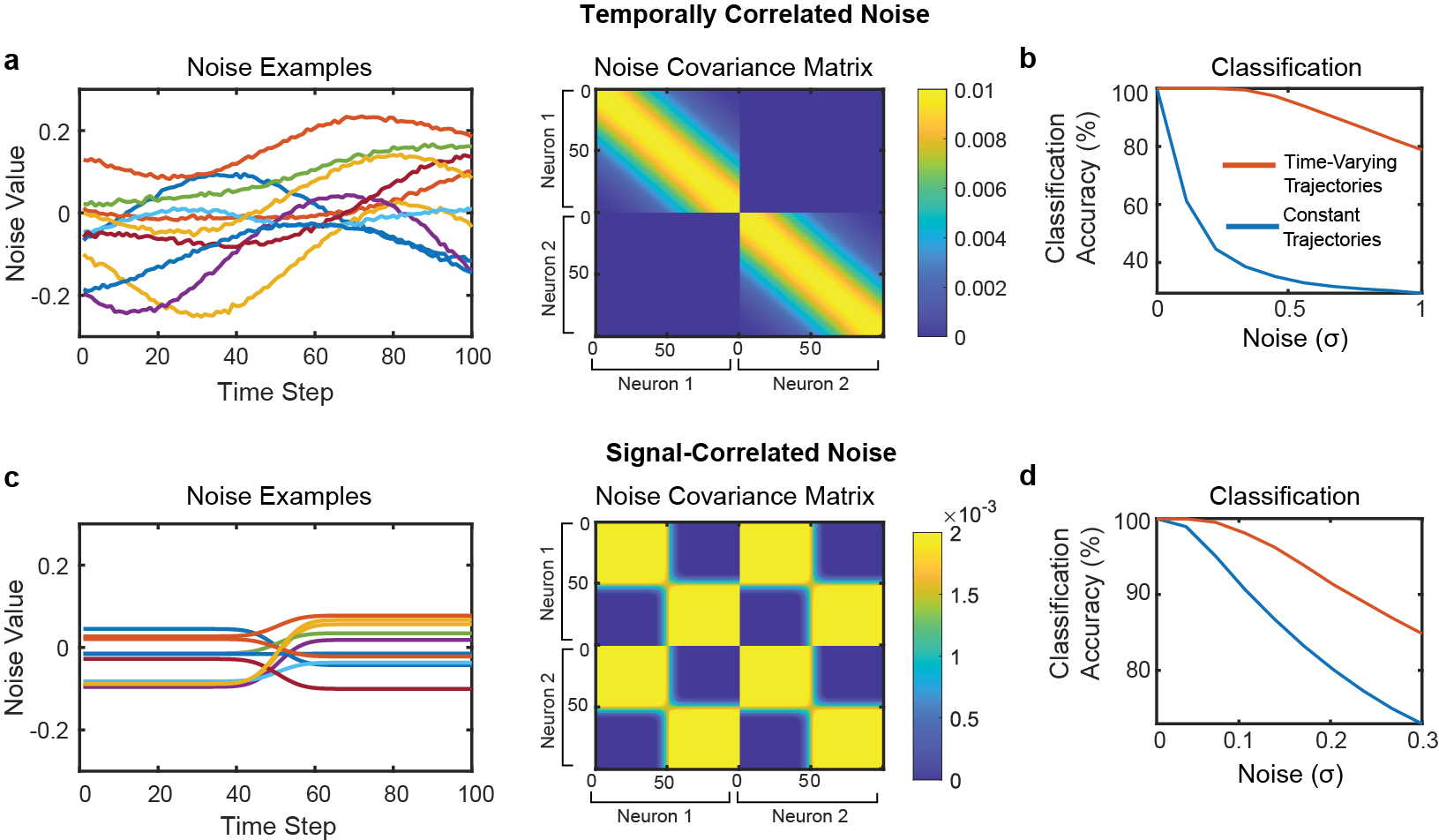
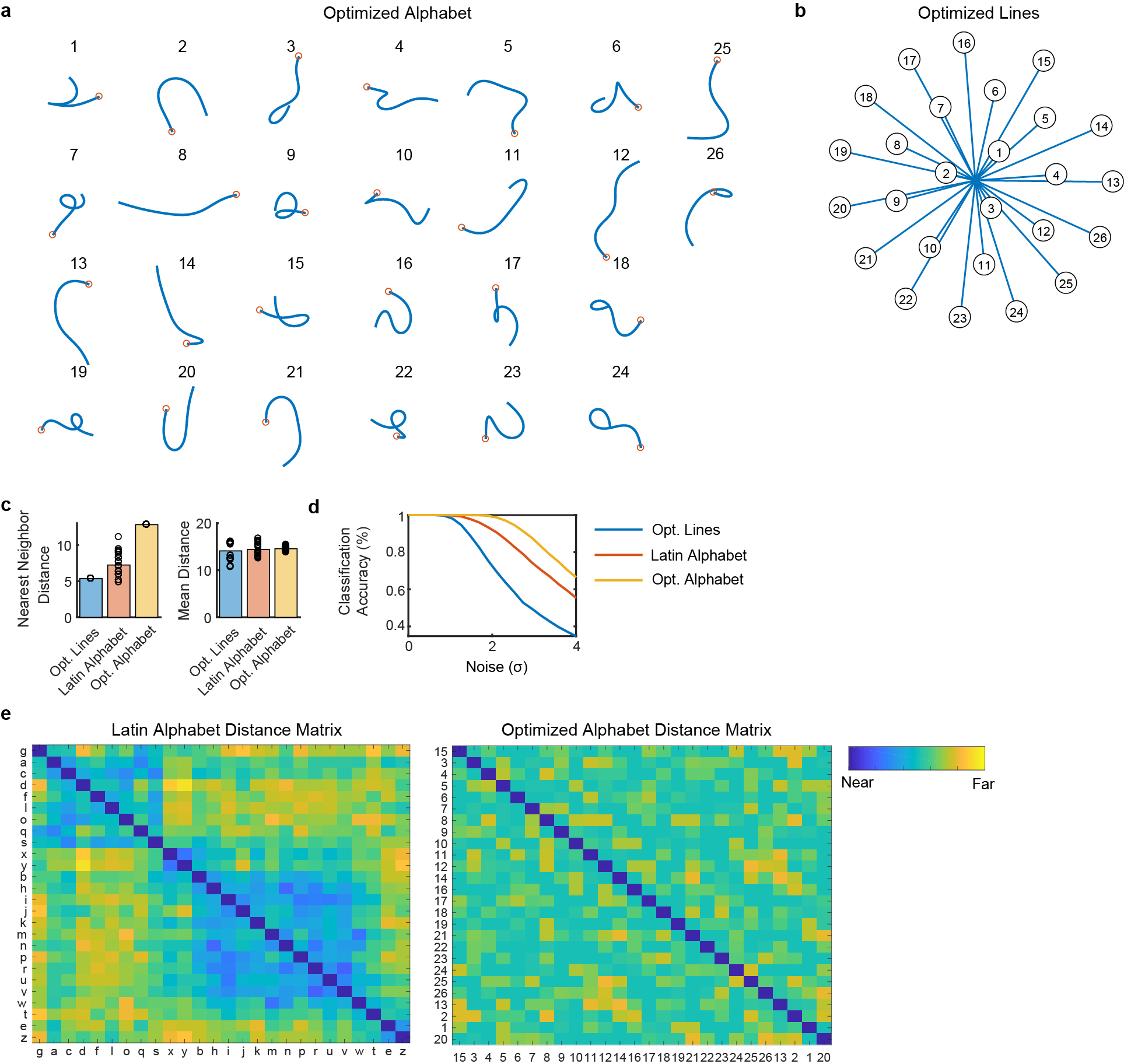
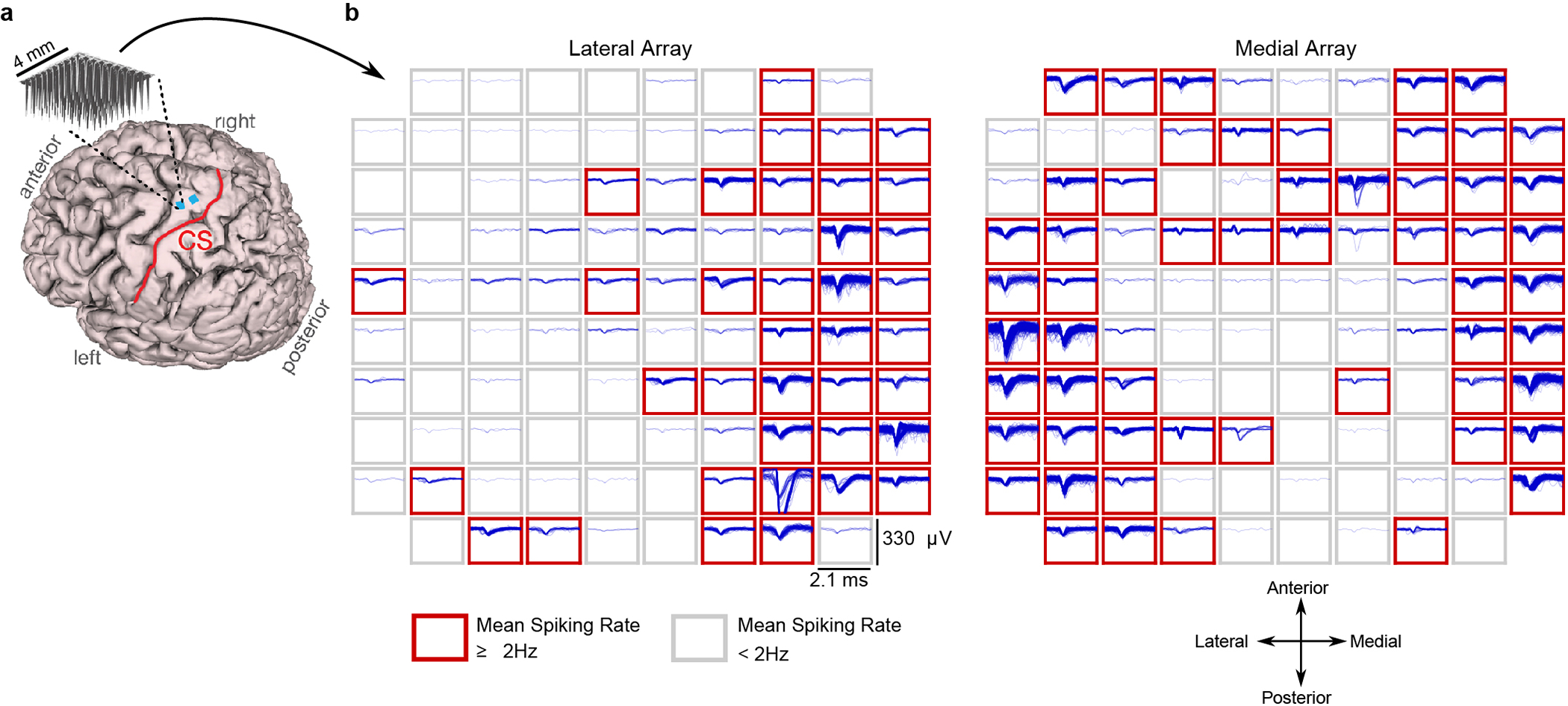
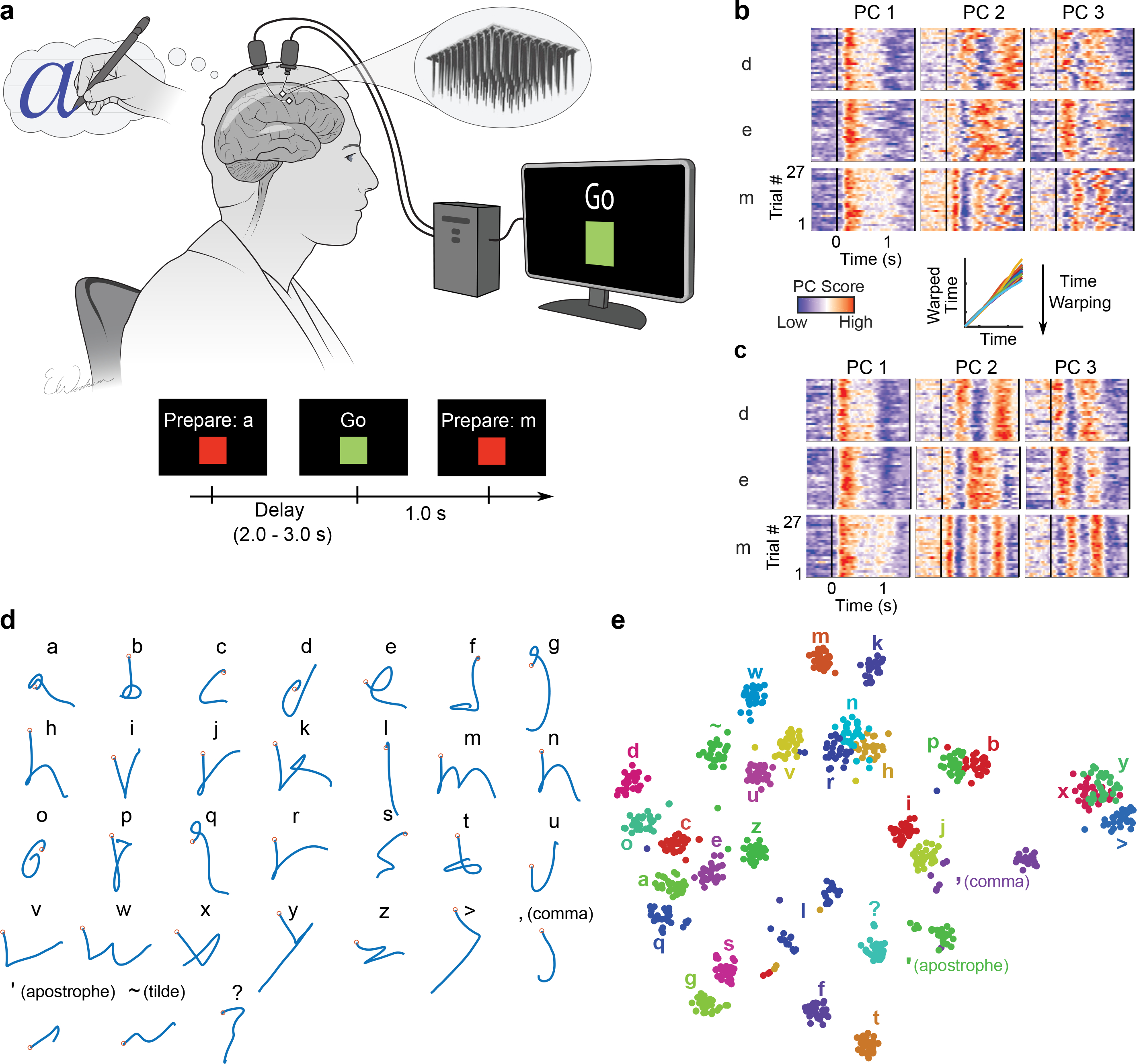
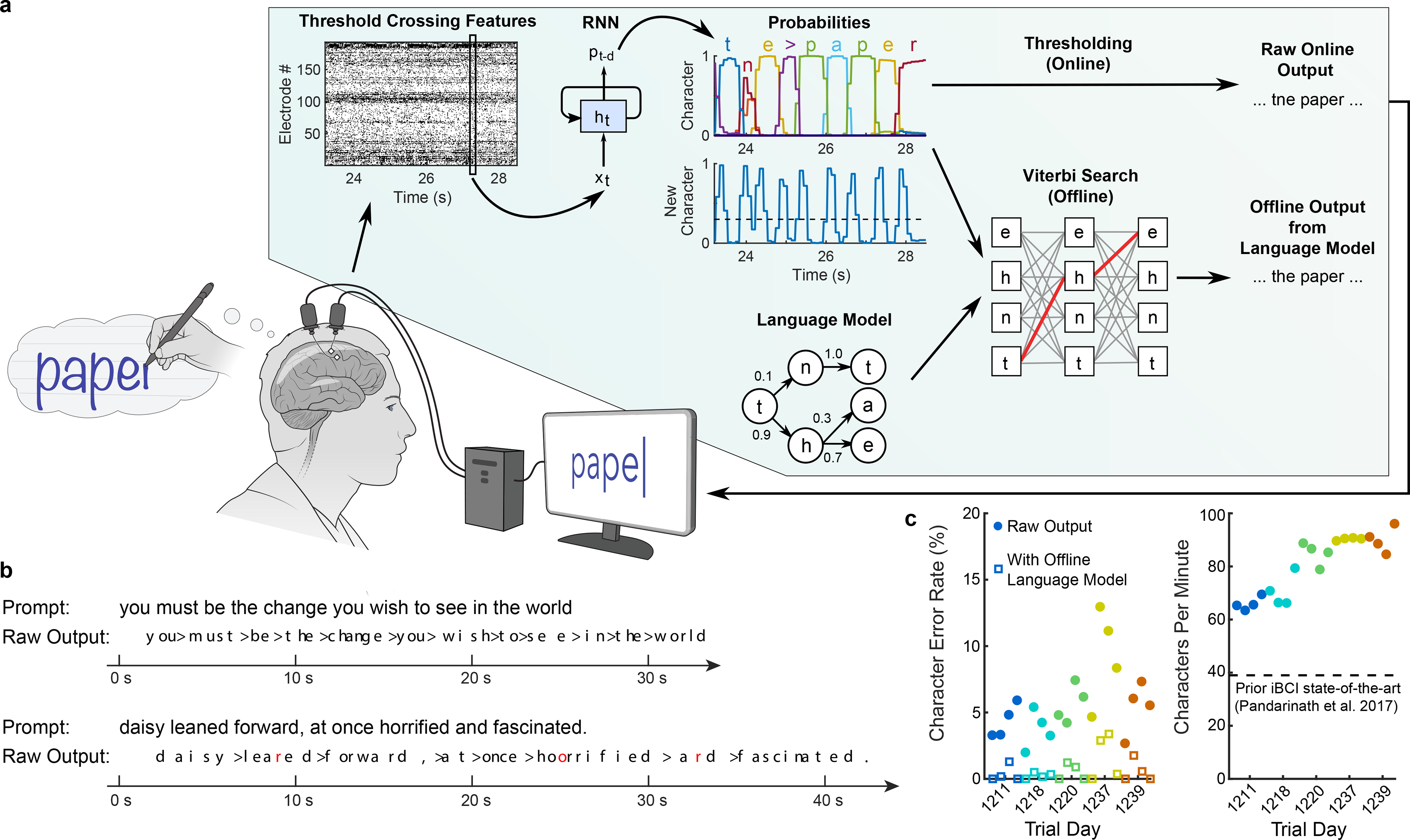
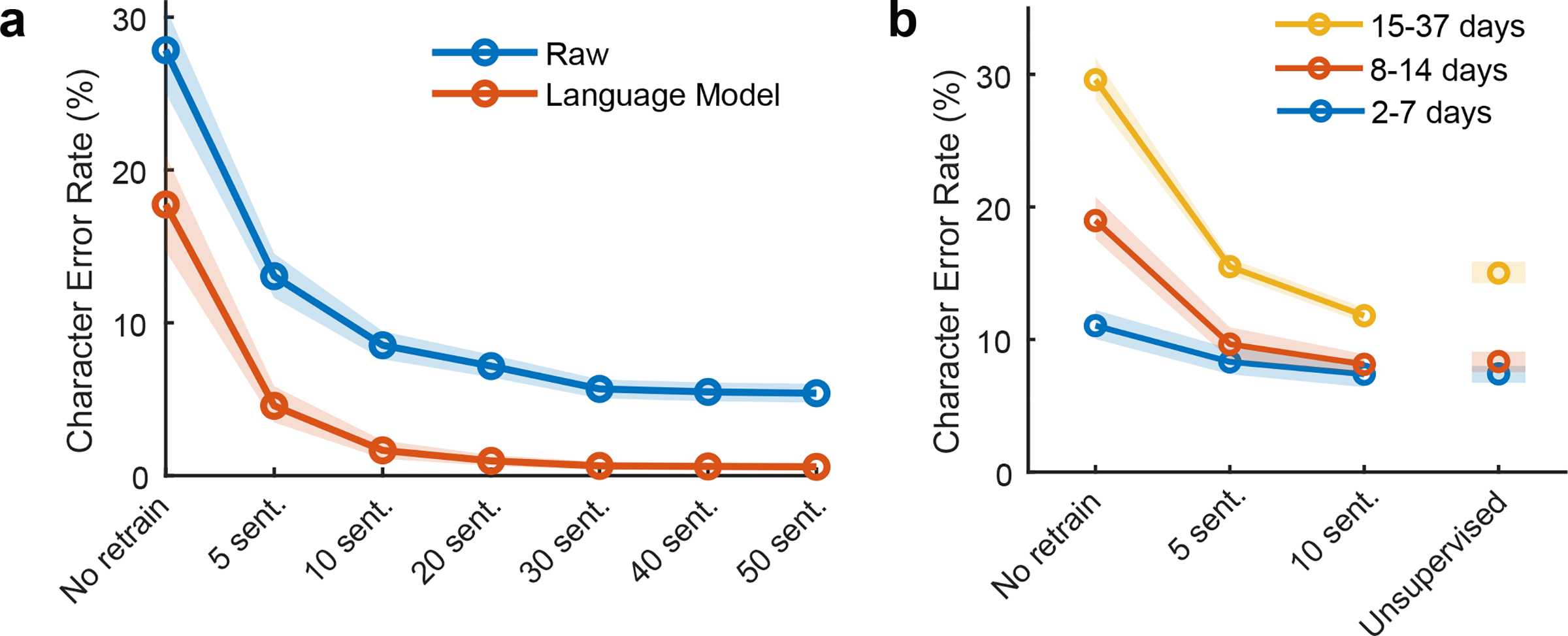
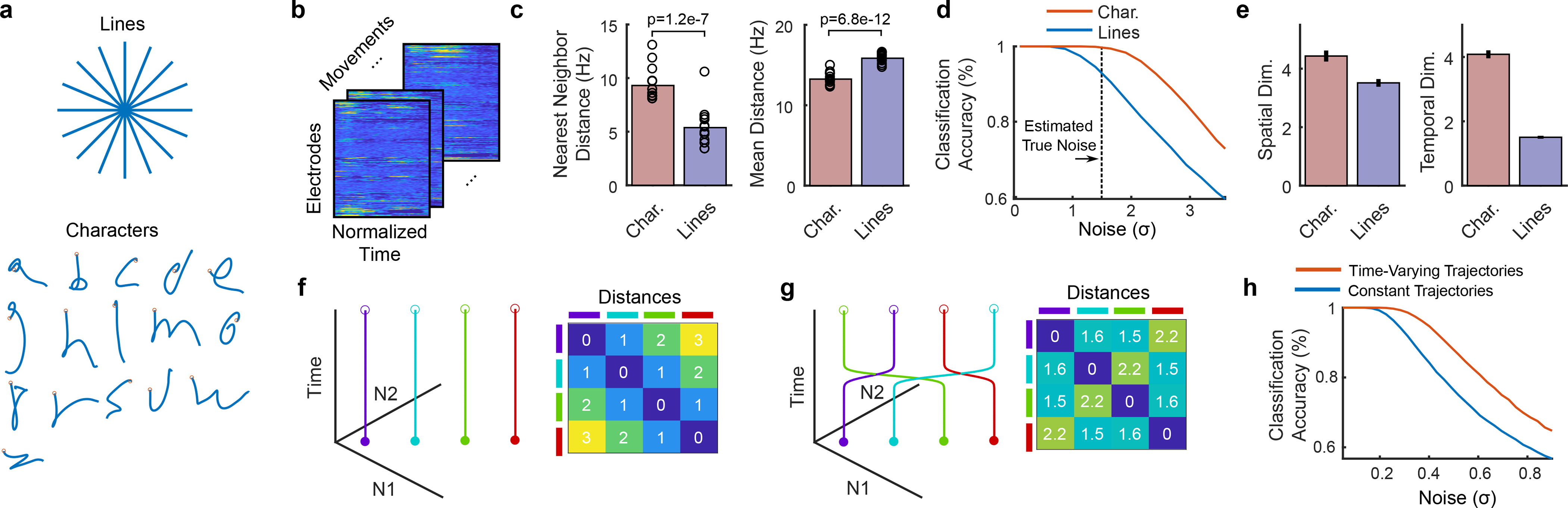
Brain-computer interfaces (BCIs) can restore communication to people who have lost the ability to move or speak. So far, a major focus of BCI research has been on restoring gross motor skills, such as reaching and grasping1-5 or point-and-click typing with a computer cursor6,7. However, rapid sequences of highly dexterous behaviours, such as handwriting or touch typing, might enable faster rates of communication. Here we developed an intracortical BCI that decodes attempted handwriting movements from neural activity in the motor cortex and translates it to text in real time, using a recurrent neural network decoding approach. With this BCI, our study participant, whose hand was paralysed from spinal cord injury, achieved typing speeds of 90 characters per minute with 94.1% raw accuracy online, and greater than 99% accuracy offline with a general-purpose autocorrect. To our knowledge, these typing speeds exceed those reported for any other BCI, and are comparable to typical smartphone typing speeds of individuals in the age group of our participant (115 characters per minute)8. Finally, theoretical considerations explain why temporally complex movements, such as handwriting, may be fundamentally easier to decode than point-to-point movements. Our results open a new approach for BCIs and demonstrate the feasibility of accurately decoding rapid, dexterous movements years after paralysis.
Figures
Comment in
-
Neural interface translates thoughts into type.Nature. 2021 May;593(7858):197-198. doi: 10.1038/d41586-021-00776-8. Nature. 2021. PMID: 33981045 No abstract available.
References
-
- Bouton CE et al. Restoring cortical control of functional movement in a human with quadriplegia. Nature 533, 247–250 (2016). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
