

Presenting artificial intelligence, deep learning, and machine learning studies to clinicians and healthcare stakeholders: an introductory reference with a guideline and a Clinical AI Research (CAIR) checklist proposal
- PMID: 33988081
- PMCID: PMC8519529
- DOI: 10.1080/17453674.2021.1918389
Presenting artificial intelligence, deep learning, and machine learning studies to clinicians and healthcare stakeholders: an introductory reference with a guideline and a Clinical AI Research (CAIR) checklist proposal
Abstract
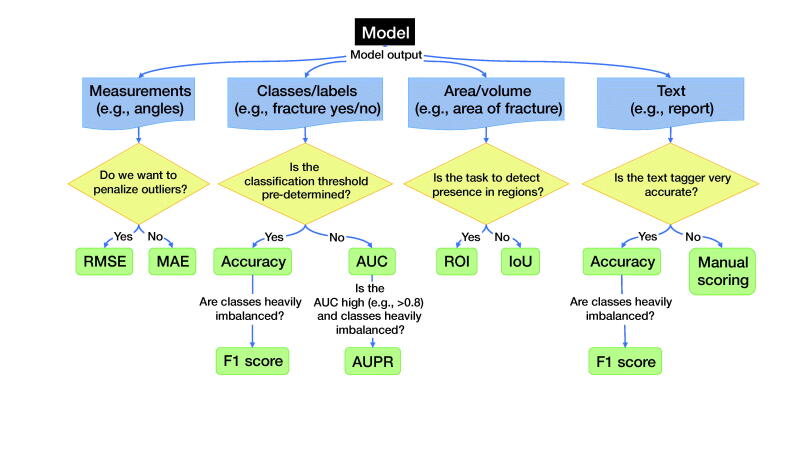
Background and purpose - Artificial intelligence (AI), deep learning (DL), and machine learning (ML) have become common research fields in orthopedics and medicine in general. Engineers perform much of the work. While they gear the results towards healthcare professionals, the difference in competencies and goals creates challenges for collaboration and knowledge exchange. We aim to provide clinicians with a context and understanding of AI research by facilitating communication between creators, researchers, clinicians, and readers of medical AI and ML research.Methods and results - We present the common tasks, considerations, and pitfalls (both methodological and ethical) that clinicians will encounter in AI research. We discuss the following topics: labeling, missing data, training, testing, and overfitting. Common performance and outcome measures for various AI and ML tasks are presented, including accuracy, precision, recall, F1 score, Dice score, the area under the curve, and ROC curves. We also discuss ethical considerations in terms of privacy, fairness, autonomy, safety, responsibility, and liability regarding data collecting or sharing.Interpretation - We have developed guidelines for reporting medical AI research to clinicians in the run-up to a broader consensus process. The proposed guidelines consist of a Clinical Artificial Intelligence Research (CAIR) checklist and specific performance metrics guidelines to present and evaluate research using AI components. Researchers, engineers, clinicians, and other stakeholders can use these proposal guidelines and the CAIR checklist to read, present, and evaluate AI research geared towards a healthcare setting.
Figures
Similar articles
-
Comprehensive reporting guidelines and checklist for studies developing and utilizing artificial intelligence models.Korean J Anesthesiol. 2025 Jun;78(3):199-214. doi: 10.4097/kja.25075. Epub 2025 Mar 26. Korean J Anesthesiol. 2025. PMID: 40468627 Free PMC article.
-
Ethical considerations on artificial intelligence in dentistry: A framework and checklist.J Dent. 2023 Aug;135:104593. doi: 10.1016/j.jdent.2023.104593. Epub 2023 Jun 22. J Dent. 2023. PMID: 37355089
-
Protocol for development of a reporting guideline (TRIPOD-AI) and risk of bias tool (PROBAST-AI) for diagnostic and prognostic prediction model studies based on artificial intelligence.BMJ Open. 2021 Jul 9;11(7):e048008. doi: 10.1136/bmjopen-2020-048008. BMJ Open. 2021. PMID: 34244270 Free PMC article.
-
Artificial intelligence terminology, methodology, and critical appraisal: A primer for headache clinicians and researchers.Headache. 2025 Jan;65(1):180-190. doi: 10.1111/head.14880. Epub 2024 Dec 10. Headache. 2025. PMID: 39658951 Review.
-
Review of study reporting guidelines for clinical studies using artificial intelligence in healthcare.BMJ Health Care Inform. 2021 Aug;28(1):e100385. doi: 10.1136/bmjhci-2021-100385. BMJ Health Care Inform. 2021. PMID: 34426417 Free PMC article. Review.
Cited by
-
Guidelines for Artificial Intelligence in Medicine: Literature Review and Content Analysis of Frameworks.J Med Internet Res. 2022 Aug 25;24(8):e36823. doi: 10.2196/36823. J Med Internet Res. 2022. PMID: 36006692 Free PMC article. Review.
-
Finding the Best Match - a Case Study on the (Text-)Feature and Model Choice in Digital Mental Health Interventions.J Healthc Inform Res. 2023 Sep 18;7(4):447-479. doi: 10.1007/s41666-023-00148-z. eCollection 2023 Dec. J Healthc Inform Res. 2023. PMID: 37927375 Free PMC article.
-
Artificial intelligence in the risk prediction models of cardiovascular disease and development of an independent validation screening tool: a systematic review.BMC Med. 2024 Feb 5;22(1):56. doi: 10.1186/s12916-024-03273-7. BMC Med. 2024. PMID: 38317226 Free PMC article.
-
Predicting maternal risk level using machine learning models.BMC Pregnancy Childbirth. 2024 Dec 18;24(1):820. doi: 10.1186/s12884-024-07030-9. BMC Pregnancy Childbirth. 2024. PMID: 39695398 Free PMC article.
-
TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods.BMJ. 2024 Apr 16;385:e078378. doi: 10.1136/bmj-2023-078378. BMJ. 2024. PMID: 38626948 Free PMC article.
References
-
- Adamson A S, Smith A.. Machine learning and health care disparities in dermatology. JAMA Dermatol 2018; 154(11): 1247. - PubMed
-
- Anderson P, Fernando B, Johnson M, Gould S. SPICE: Semantic Propositional Image Caption Evaluation. arXiv:160708822 [cs] [Internet] 2016. Jul 29 [cited 2020 Nov 30]. Available from: http://arxiv.org/abs/1607.08822
-
- Bandos A I, Obuchowski N A.. Evaluation of diagnostic accuracy in free-response detection-localization tasks using ROC tools. Stat Methods Med Res 2019; 28(6): 1808–25. - PubMed
-
- Banerjee S, Lavie A. METEOR: an automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization [Internet]. Ann Arbor, MI: Association for Computational Linguistics; 2005. [cited 2020 Nov 30]. p. 65–72. Available from: https://www.aclweb.org/anthology/W05-0909
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources