

Understanding and improving the quality and reproducibility of Jupyter notebooks
- PMID: 33994841
- PMCID: PMC8106381
- DOI: 10.1007/s10664-021-09961-9
Understanding and improving the quality and reproducibility of Jupyter notebooks
Abstract
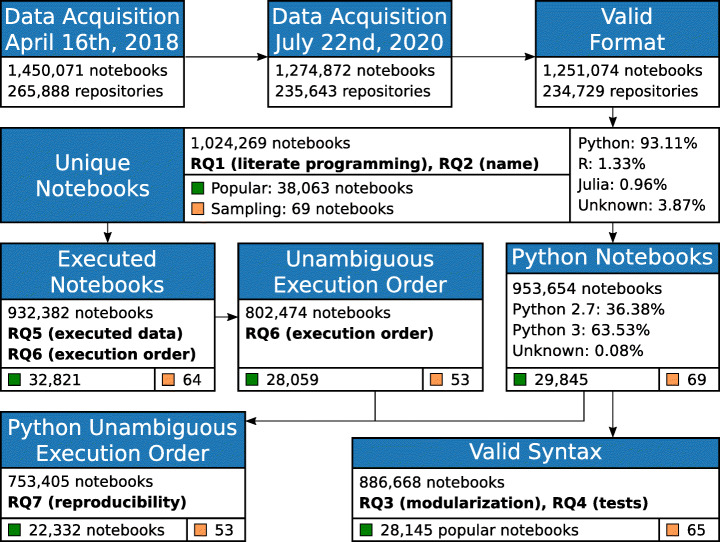
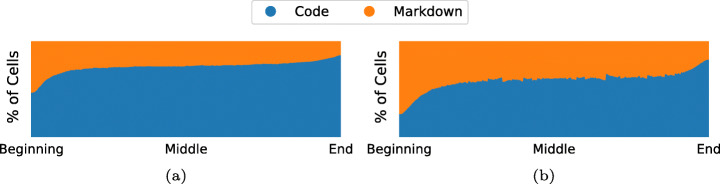
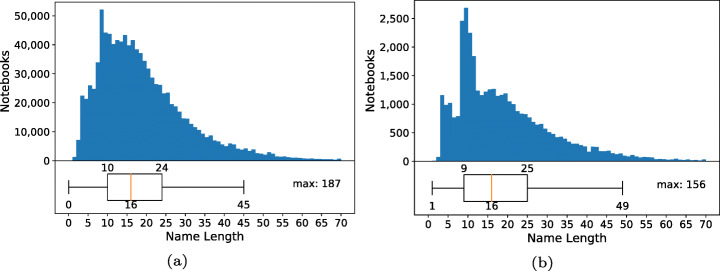
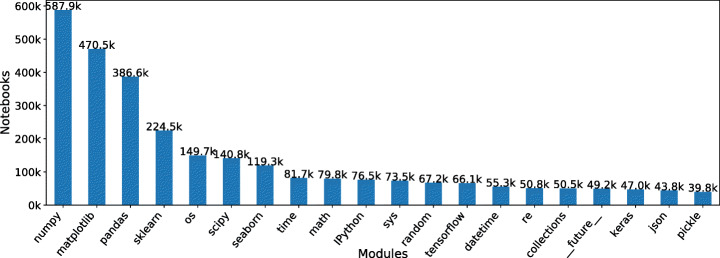
Jupyter Notebooks have been widely adopted by many different communities, both in science and industry. They support the creation of literate programming documents that combine code, text, and execution results with visualizations and other rich media. The self-documenting aspects and the ability to reproduce results have been touted as significant benefits of notebooks. At the same time, there has been growing criticism that the way in which notebooks are being used leads to unexpected behavior, encourages poor coding practices, and makes it hard to reproduce its results. To better understand good and bad practices used in the development of real notebooks, in prior work we studied 1.4 million notebooks from GitHub. We presented a detailed analysis of their characteristics that impact reproducibility, proposed best practices that can improve the reproducibility, and discussed open challenges that require further research and development. In this paper, we extended the analysis in four different ways to validate the hypothesis uncovered in our original study. First, we separated a group of popular notebooks to check whether notebooks that get more attention have more quality and reproducibility capabilities. Second, we sampled notebooks from the full dataset for an in-depth qualitative analysis of what constitutes the dataset and which features they have. Third, we conducted a more detailed analysis by isolating library dependencies and testing different execution orders. We report how these factors impact the reproducibility rates. Finally, we mined association rules from the notebooks. We discuss patterns we discovered, which provide additional insights into notebook reproducibility. Based on our findings and best practices we proposed, we designed Julynter, a Jupyter Lab extension that identifies potential issues in notebooks and suggests modifications that improve their reproducibility. We evaluate Julynter with a remote user experiment with the goal of assessing Julynter recommendations and usability.
Keywords: GitHub; Jupyter notebook; Lint; Quality; Reproducibility.
© The Author(s), under exclusive licence to Springer Science+Business Media, LLC, part of Springer Nature 2021.
Figures


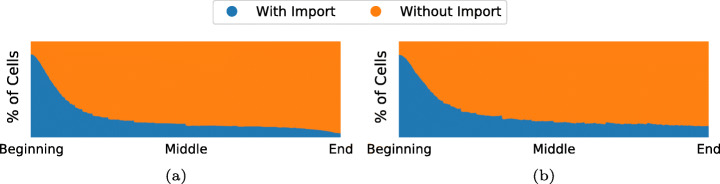
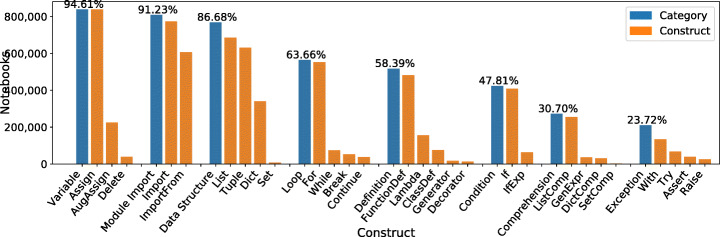
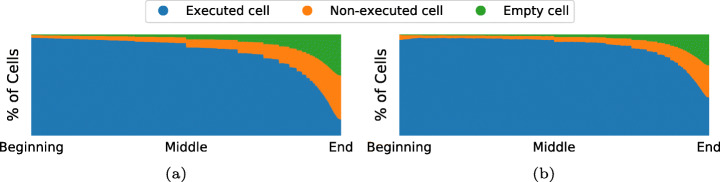
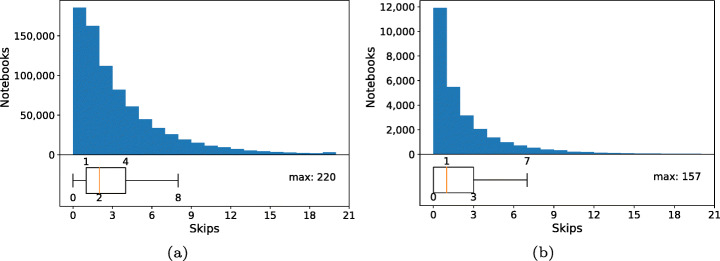
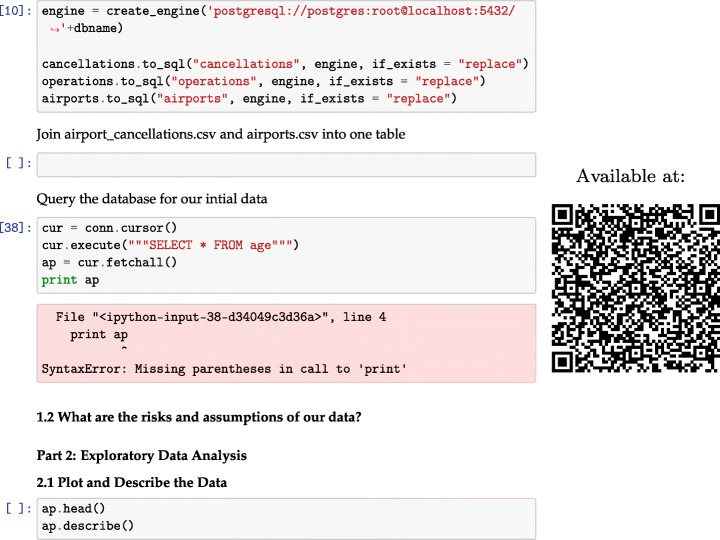
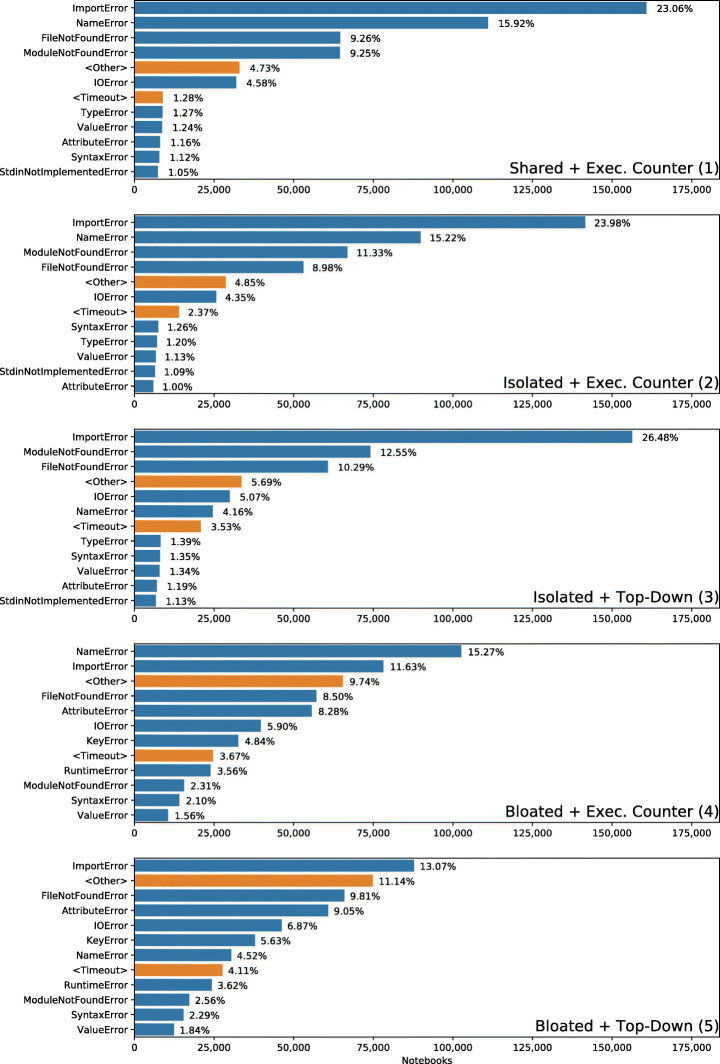


References
-
- Agrawal R, Srikant R, et al. (1994) Fast algorithms for mining association rules. In: VLDB conference, VLDB, vol 1215, pp 487–499
-
- Anaconda (2018) Anaconda software distribution. https://www.anaconda.com. Accessed: 2019-10-01
-
- Arnaoudova V, Di Penta M, Antoniol G. Linguistic antipatterns: what they are and how developers perceive them. Empir Softw Eng. 2016;21(1):104–158. doi: 10.1007/s10664-014-9350-8. - DOI
-
- Bangor A, Kortum PT, Miller JT. An empirical evaluation of the system usability scale. Int J Hum–Comput Interact. 2008;24(6):574–594. doi: 10.1080/10447310802205776. - DOI
-
- Benedek J, Miner T. Measuring desirability: new methods for evaluating desirability in a usability lab setting. Proc Usabil Prof Assoc. 2002;2003(8–12):57.
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous