

AutoStepfinder: A fast and automated step detection method for single-molecule analysis
- PMID: 34036291
- PMCID: PMC8134948
- DOI: 10.1016/j.patter.2021.100256
AutoStepfinder: A fast and automated step detection method for single-molecule analysis
Abstract
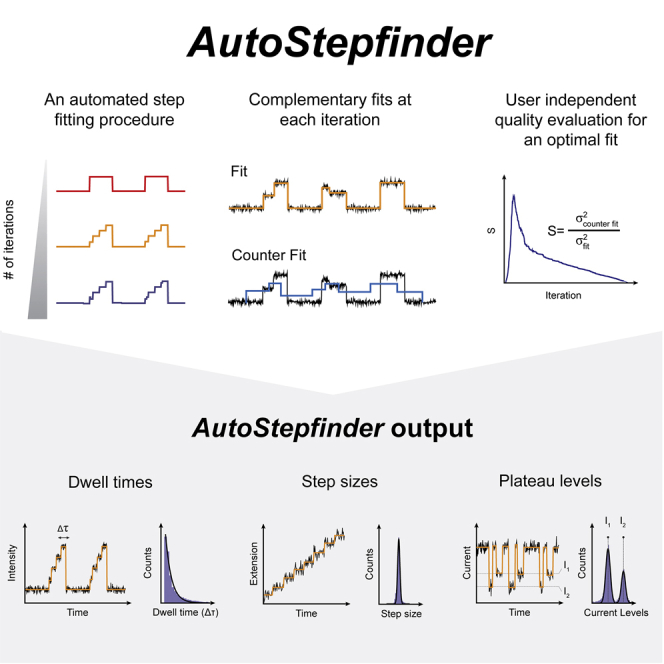
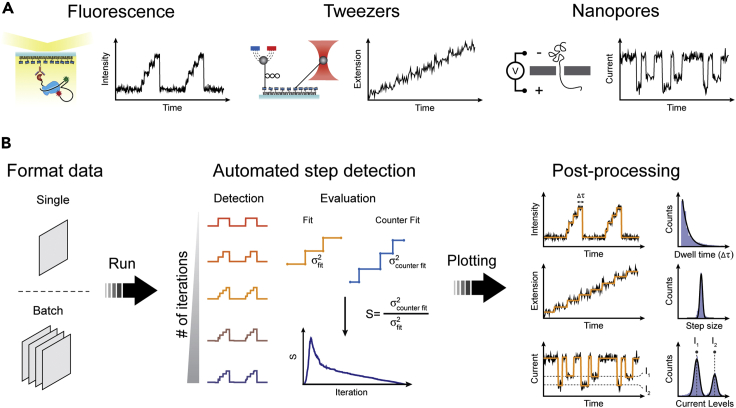
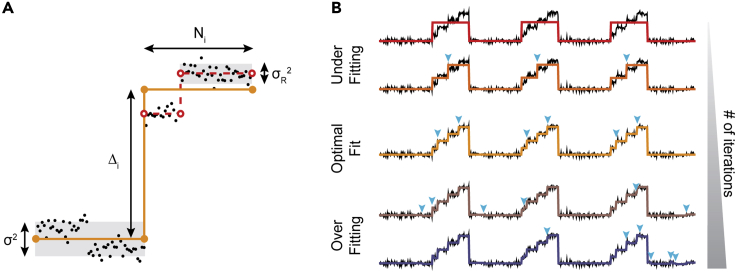
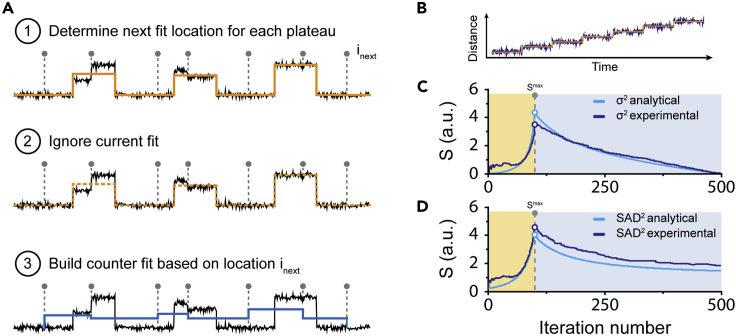
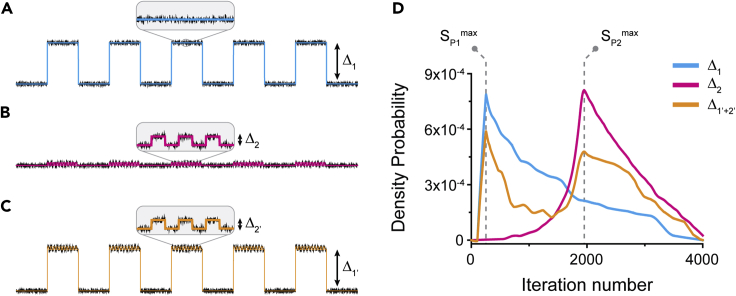
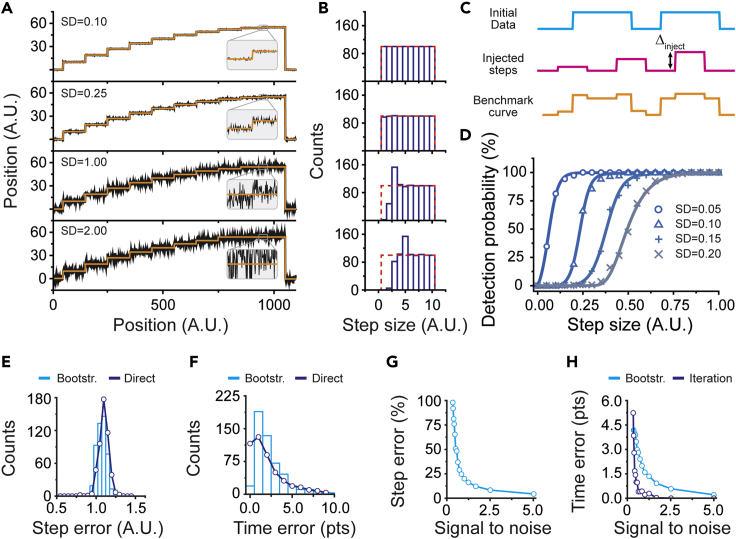
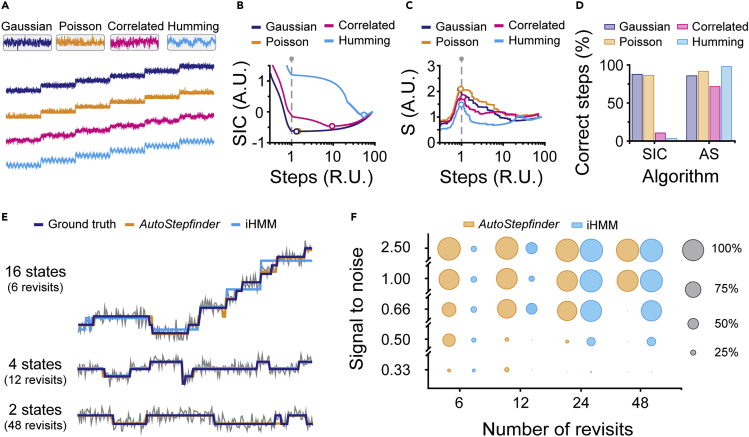
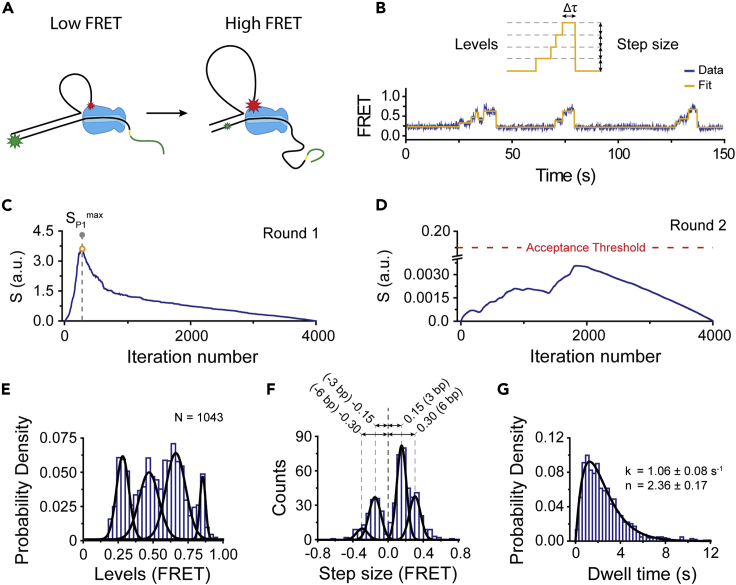
Single-molecule techniques allow the visualization of the molecular dynamics of nucleic acids and proteins with high spatiotemporal resolution. Valuable kinetic information of biomolecules can be obtained when the discrete states within single-molecule time trajectories are determined. Here, we present a fast, automated, and bias-free step detection method, AutoStepfinder, that determines steps in large datasets without requiring prior knowledge on the noise contributions and location of steps. The analysis is based on a series of partition events that minimize the difference between the data and the fit. A dual-pass strategy determines the optimal fit and allows AutoStepfinder to detect steps of a wide variety of sizes. We demonstrate step detection for a broad variety of experimental traces. The user-friendly interface and the automated detection of AutoStepfinder provides a robust analysis procedure that enables anyone without programming knowledge to generate step fits and informative plots in less than an hour.
Keywords: AutoStepfinder; Stepfinder; biophysics; data analysis; fluorescence; magnetic tweezer; nanopore; optical tweezer; single molecule; step detection.
© 2021 The Authors.
Conflict of interest statement
The authors declare no competing financial interests.
Figures
Similar articles
-
Step detection in single-molecule real time trajectories embedded in correlated noise.PLoS One. 2013;8(3):e59279. doi: 10.1371/journal.pone.0059279. Epub 2013 Mar 22. PLoS One. 2013. PMID: 23533612 Free PMC article.
-
Detection of Steps in Single Molecule Data.Cell Mol Bioeng. 2012;5(1):14-31. doi: 10.1007/s12195-011-0188-5. Cell Mol Bioeng. 2012. PMID: 23956798 Free PMC article.
-
Automated nonparametric method for detection of step-like features in biological data sets.Cytometry A. 2015 May;87(5):393-404. doi: 10.1002/cyto.a.22631. Epub 2015 Feb 4. Cytometry A. 2015. PMID: 25652364
-
Fluorescent Biosensors Based on Single-Molecule Counting.Acc Chem Res. 2016 Sep 20;49(9):1722-30. doi: 10.1021/acs.accounts.6b00237. Epub 2016 Sep 1. Acc Chem Res. 2016. PMID: 27583695 Review.
-
Plasmonic-Nanopore Biosensors for Superior Single-Molecule Detection.Adv Mater. 2019 Jun;31(23):e1900422. doi: 10.1002/adma.201900422. Epub 2019 Apr 3. Adv Mater. 2019. PMID: 30941823 Review.
Cited by
-
Tracking Single Kinesin in Live Cells Using MINFLUX.Methods Mol Biol. 2025;2881:119-131. doi: 10.1007/978-1-0716-4280-1_5. Methods Mol Biol. 2025. PMID: 39704940
-
CTCF is a DNA-tension-dependent barrier to cohesin-mediated loop extrusion.Nature. 2023 Apr;616(7958):822-827. doi: 10.1038/s41586-023-05961-5. Epub 2023 Apr 19. Nature. 2023. PMID: 37076620 Free PMC article.
-
Sequential requirements for distinct Polθ domains during theta-mediated end joining.Mol Cell. 2024 Apr 18;84(8):1460-1474.e6. doi: 10.1016/j.molcel.2024.03.010. Mol Cell. 2024. PMID: 38640894 Free PMC article.
-
Impact of Molecular Crowding on Accessibility of Telomeric Overhangs Forming Multiple G-quadruplexes.bioRxiv [Preprint]. 2025 May 30:2025.05.26.656241. doi: 10.1101/2025.05.26.656241. bioRxiv. 2025. Update in: Biomacromolecules. 2025 Jul 14;26(7):4380-4386. doi: 10.1021/acs.biomac.5c00360. PMID: 40502016 Free PMC article. Updated. Preprint.
-
Shelterin reduces the accessibility of telomeric overhangs.Nucleic Acids Res. 2022 Dec 9;50(22):12885-12895. doi: 10.1093/nar/gkac1176. Nucleic Acids Res. 2022. PMID: 36511858 Free PMC article.
References
-
- Ha T. Single-molecule methods leap ahead. Nat. Methods. 2014;11:1015–1018. - PubMed
-
- Forties R.A., Wang M.D. Minireview discovering the power of single molecules. Cell. 2014;157:4–7. - PubMed
-
- Svoboda K., Schmidt C.F., Schnapp B.J., Block S.M. Direct observation of kinesin stepping by optical trapping interferometry. Nature. 1993;365:721–727. - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources
