

Predicting Semantic Similarity Between Clinical Sentence Pairs Using Transformer Models: Evaluation and Representational Analysis
- PMID: 34037527
- PMCID: PMC8190645
- DOI: 10.2196/23099
Predicting Semantic Similarity Between Clinical Sentence Pairs Using Transformer Models: Evaluation and Representational Analysis
Abstract
Background: Semantic textual similarity (STS) is a natural language processing (NLP) task that involves assigning a similarity score to 2 snippets of text based on their meaning. This task is particularly difficult in the domain of clinical text, which often features specialized language and the frequent use of abbreviations.
Objective: We created an NLP system to predict similarity scores for sentence pairs as part of the Clinical Semantic Textual Similarity track in the 2019 n2c2/OHNLP Shared Task on Challenges in Natural Language Processing for Clinical Data. We subsequently sought to analyze the intermediary token vectors extracted from our models while processing a pair of clinical sentences to identify where and how representations of semantic similarity are built in transformer models.
Methods: Given a clinical sentence pair, we take the average predicted similarity score across several independently fine-tuned transformers. In our model analysis we investigated the relationship between the final model's loss and surface features of the sentence pairs and assessed the decodability and representational similarity of the token vectors generated by each model.
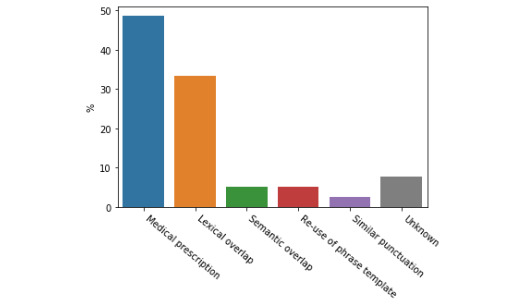
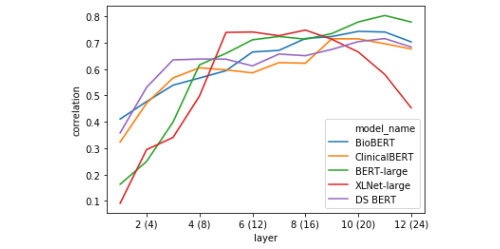
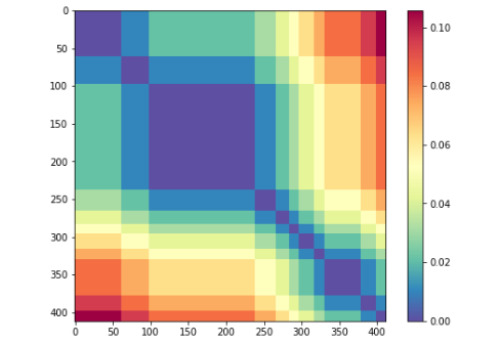
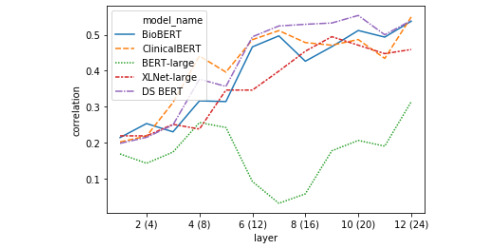
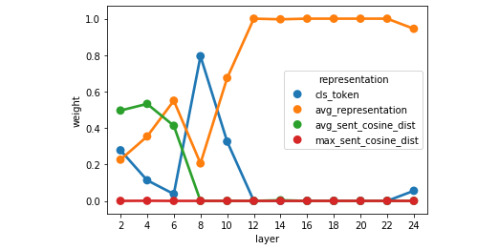
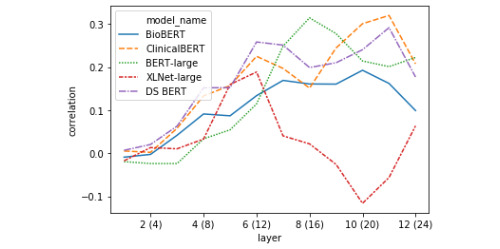
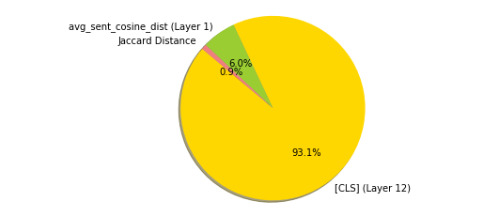
Results: Our model achieved a correlation of 0.87 with the ground-truth similarity score, reaching 6th place out of 33 teams (with a first-place score of 0.90). In detailed qualitative and quantitative analyses of the model's loss, we identified the system's failure to correctly model semantic similarity when both sentence pairs contain details of medical prescriptions, as well as its general tendency to overpredict semantic similarity given significant token overlap. The token vector analysis revealed divergent representational strategies for predicting textual similarity between bidirectional encoder representations from transformers (BERT)-style models and XLNet. We also found that a large amount information relevant to predicting STS can be captured using a combination of a classification token and the cosine distance between sentence-pair representations in the first layer of a transformer model that did not produce the best predictions on the test set.
Conclusions: We designed and trained a system that uses state-of-the-art NLP models to achieve very competitive results on a new clinical STS data set. As our approach uses no hand-crafted rules, it serves as a strong deep learning baseline for this task. Our key contribution is a detailed analysis of the model's outputs and an investigation of the heuristic biases learned by transformer models. We suggest future improvements based on these findings. In our representational analysis we explore how different transformer models converge or diverge in their representation of semantic signals as the tokens of the sentences are augmented by successive layers. This analysis sheds light on how these "black box" models integrate semantic similarity information in intermediate layers, and points to new research directions in model distillation and sentence embedding extraction for applications in clinical NLP.
Keywords: biomedical NLP; clinical text; natural language processing; representation learning; transformer models.
©Mark Ormerod, Jesús Martínez del Rincón, Barry Devereux. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 26.05.2021.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures




Similar articles
-
The 2019 n2c2/OHNLP Track on Clinical Semantic Textual Similarity: Overview.JMIR Med Inform. 2020 Nov 27;8(11):e23375. doi: 10.2196/23375. JMIR Med Inform. 2020. PMID: 33245291 Free PMC article.
-
Incorporating Domain Knowledge Into Language Models by Using Graph Convolutional Networks for Assessing Semantic Textual Similarity: Model Development and Performance Comparison.JMIR Med Inform. 2021 Nov 26;9(11):e23101. doi: 10.2196/23101. JMIR Med Inform. 2021. PMID: 34842531 Free PMC article.
-
Identification of Semantically Similar Sentences in Clinical Notes: Iterative Intermediate Training Using Multi-Task Learning.JMIR Med Inform. 2020 Nov 27;8(11):e22508. doi: 10.2196/22508. JMIR Med Inform. 2020. PMID: 33245284 Free PMC article.
-
AMMU: A survey of transformer-based biomedical pretrained language models.J Biomed Inform. 2022 Feb;126:103982. doi: 10.1016/j.jbi.2021.103982. Epub 2021 Dec 31. J Biomed Inform. 2022. PMID: 34974190 Review.
-
Natural Language Processing Applications in the Clinical Neurosciences: A Machine Learning Augmented Systematic Review.Acta Neurochir Suppl. 2022;134:277-289. doi: 10.1007/978-3-030-85292-4_32. Acta Neurochir Suppl. 2022. PMID: 34862552
Cited by
-
Time-frequency-space transformer EEG decoding for spinal cord injury.Cogn Neurodyn. 2024 Dec;18(6):3491-3506. doi: 10.1007/s11571-024-10135-8. Epub 2024 Jun 18. Cogn Neurodyn. 2024. PMID: 39712087
-
EMPT: a sparsity Transformer for EEG-based motor imagery recognition.Front Neurosci. 2024 Apr 18;18:1366294. doi: 10.3389/fnins.2024.1366294. eCollection 2024. Front Neurosci. 2024. PMID: 38721049 Free PMC article.
-
Augmenting Reddit Posts to Determine Wellness Dimensions impacting Mental Health.Proc Conf Assoc Comput Linguist Meet. 2023 Jul;2023:306-312. doi: 10.18653/v1/2023.bionlp-1.27. Proc Conf Assoc Comput Linguist Meet. 2023. PMID: 38384674 Free PMC article.
-
Detecting Tweets Containing Cannabidiol-Related COVID-19 Misinformation Using Transformer Language Models and Warning Letters From Food and Drug Administration: Content Analysis and Identification.JMIR Infodemiology. 2023 Jan 23;3:e38390. doi: 10.2196/38390. eCollection 2023. JMIR Infodemiology. 2023. PMID: 36844029 Free PMC article.
-
A Catalogue of Machine Learning Algorithms for Healthcare Risk Predictions.Sensors (Basel). 2022 Nov 8;22(22):8615. doi: 10.3390/s22228615. Sensors (Basel). 2022. PMID: 36433212 Free PMC article.
References
-
- Salton G. Automatic text processing: the transformation, analysis, and retrieval of information by computer. Choice Reviews Online. 1989 Sep 01;27(01):27-0351–27-0351. doi: 10.5860/choice.27-0351. - DOI
-
- Lee M, Pincombe B, Welsh M. An Empirical Evaluation of Models of Text Document Similarity. Proceedings of the Annual Meeting of the Cognitive Science Society; Annual Conference of the Cognitive Science Society; 21-23 July 2005; Stresa, Italy. 2005. Jul, pp. 1254–1259. https://escholarship.org/uc/item/48g155nq
-
- Agirre E, Cer D, Diab M, Gonzalez-Agirre A. SemEval-2012 Task 6: A Pilot on Semantic Textual Similarity (SemEval@NAACL-HLT). *SEM 2012: The First Joint Conference on Lexical and Computational Semantics; June 7-8, 2012; Montréal, QC, Canada. 2012. Jun, pp. 285–393. - DOI
-
- Agirre E, Cer D, Diab M, Gonzalez-Agirre A, Guo W. *SEM 2013 shared task: Semantic Textual Similarity (*SEM@NAACL-HLT). Second Joint Conference on Lexical and Computational Semantics (*SEM); June 2013; Atlanta, GA, USA. 2013. Jun, pp. 32–43.
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
