

Text mining to support abstract screening for knowledge syntheses: a semi-automated workflow
- PMID: 34039433
- PMCID: PMC8152711
- DOI: 10.1186/s13643-021-01700-x
Text mining to support abstract screening for knowledge syntheses: a semi-automated workflow
Abstract
Background: Current text mining tools supporting abstract screening in systematic reviews are not widely used, in part because they lack sensitivity and precision. We set out to develop an accessible, semi-automated "workflow" to conduct abstract screening for systematic reviews and other knowledge synthesis methods.
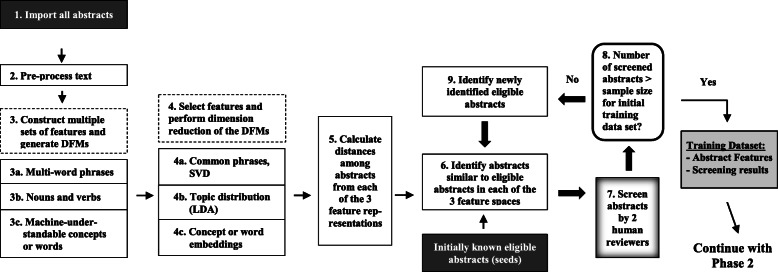
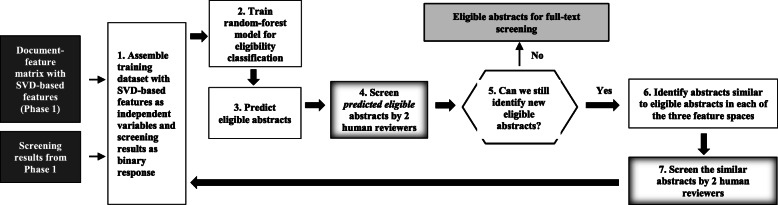
Methods: We adopt widely recommended text-mining and machine-learning methods to (1) process title-abstracts into numerical training data; and (2) train a classification model to predict eligible abstracts. The predicted abstracts are screened by human reviewers for ("true") eligibility, and the newly eligible abstracts are used to identify similar abstracts, using near-neighbor methods, which are also screened. These abstracts, as well as their eligibility results, are used to update the classification model, and the above steps are iterated until no new eligible abstracts are identified. The workflow was implemented in R and evaluated using a systematic review of insulin formulations for type-1 diabetes (14,314 abstracts) and a scoping review of knowledge-synthesis methods (17,200 abstracts). Workflow performance was evaluated against the recommended practice of screening abstracts by 2 reviewers, independently. Standard measures were examined: sensitivity (inclusion of all truly eligible abstracts), specificity (exclusion of all truly ineligible abstracts), precision (inclusion of all truly eligible abstracts among all abstracts screened as eligible), F1-score (harmonic average of sensitivity and precision), and accuracy (correctly predicted eligible or ineligible abstracts). Workload reduction was measured as the hours the workflow saved, given only a subset of abstracts needed human screening.
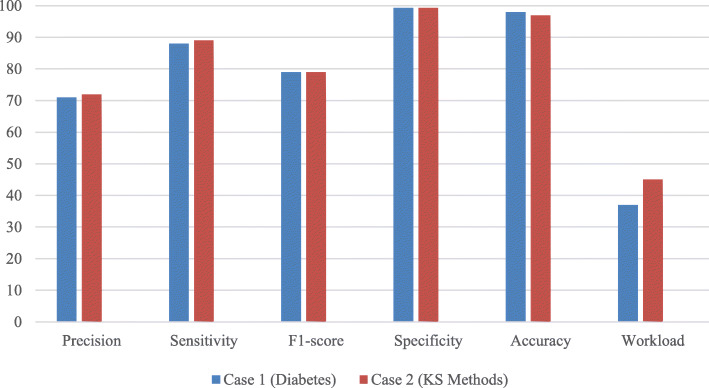
Results: With respect to the systematic and scoping reviews respectively, the workflow attained 88%/89% sensitivity, 99%/99% specificity, 71%/72% precision, an F1-score of 79%/79%, 98%/97% accuracy, 63%/55% workload reduction, with 12%/11% fewer abstracts for full-text retrieval and screening, and 0%/1.5% missed studies in the completed reviews.
Conclusion: The workflow was a sensitive, precise, and efficient alternative to the recommended practice of screening abstracts with 2 reviewers. All eligible studies were identified in the first case, while 6 studies (1.5%) were missed in the second that would likely not impact the review's conclusions. We have described the workflow in language accessible to reviewers with limited exposure to natural language processing and machine learning, and have made the code available to reviewers.
Keywords: Abstract screening; Automation; Classification model; Machine learning; Natural language processing; Scoping review; Systematic review; Text mining.
Conflict of interest statement
ACT is an associate editor for Systematic Reviews and is not involved in the editorial board’s decision to accept or reject this paper
Figures
References
-
- Higgins J, Green S. Cochrane handbook for systematic reviews of interventions Version 5.1.0. The Cochrane Collaboration. 2011.
-
- Petticrew M, Roberts H. Systematic reviews in the social sciences: A practical guide. Malden: Blackwell Publishing Co.; 2006.
-
- O'Connor AM, Tsafnat G, Gilbert SB, Thayer KA, Wolfe MS. Moving toward the automation of the systematic review process: a summary of discussions at the second meeting of International Collaboration for the Automation of Systematic Reviews (ICASR) Syst Rev. 2018;7(1):3. doi: 10.1186/s13643-017-0667-4. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
