

Swarm Learning for decentralized and confidential clinical machine learning
- PMID: 34040261
- PMCID: PMC8189907
- DOI: 10.1038/s41586-021-03583-3
Swarm Learning for decentralized and confidential clinical machine learning
Abstract
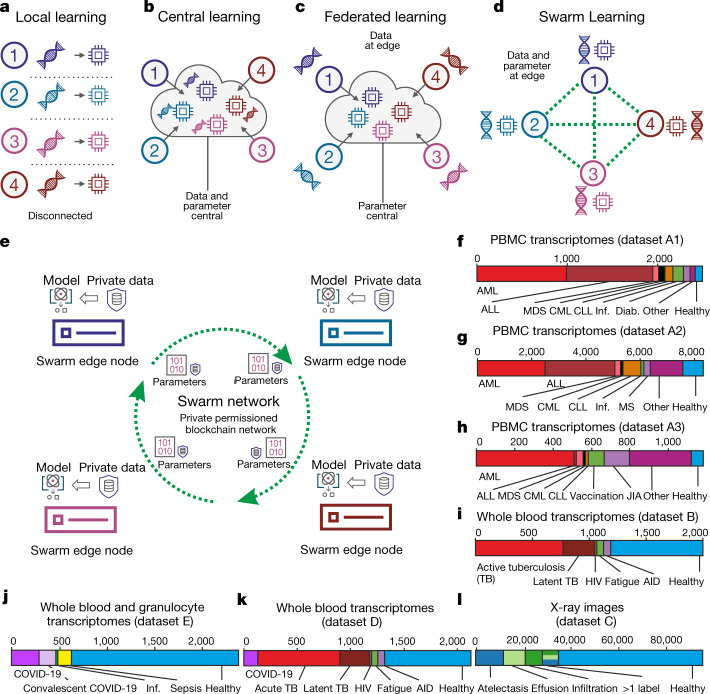
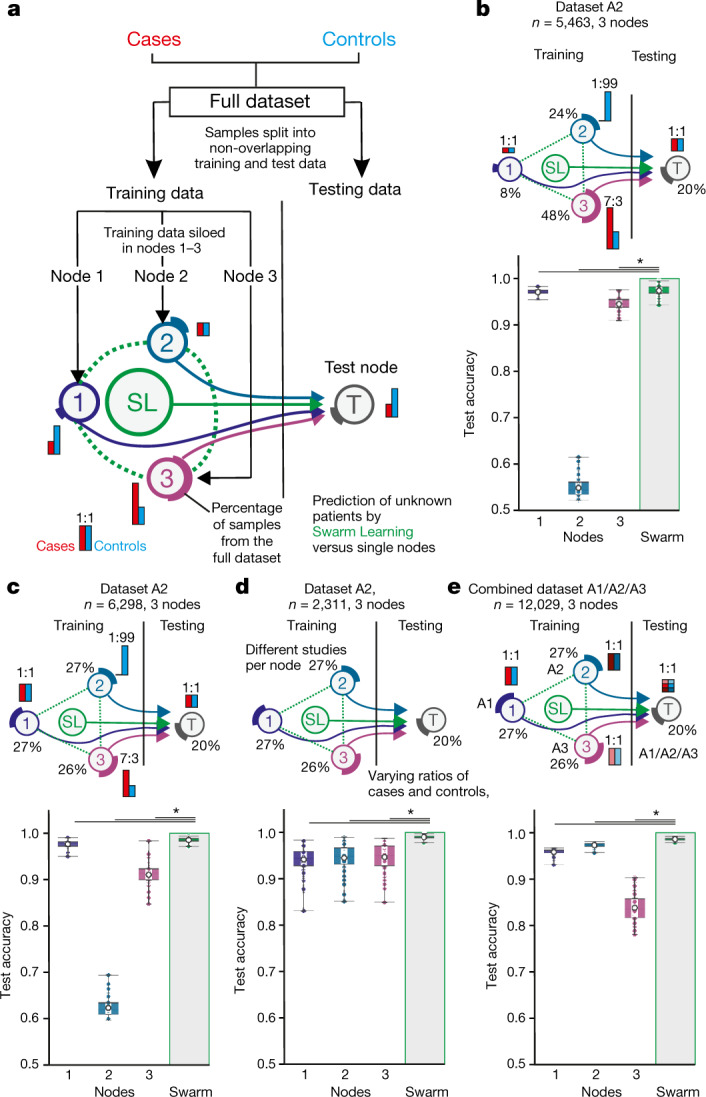
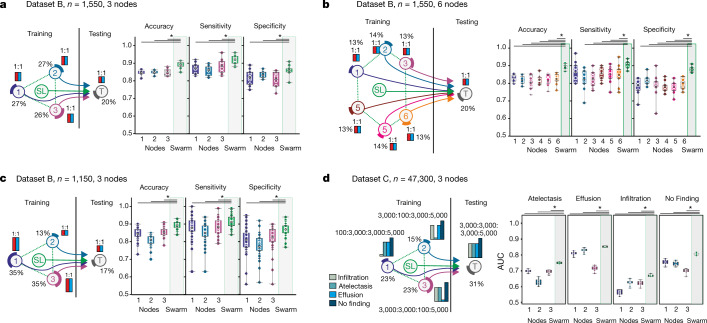
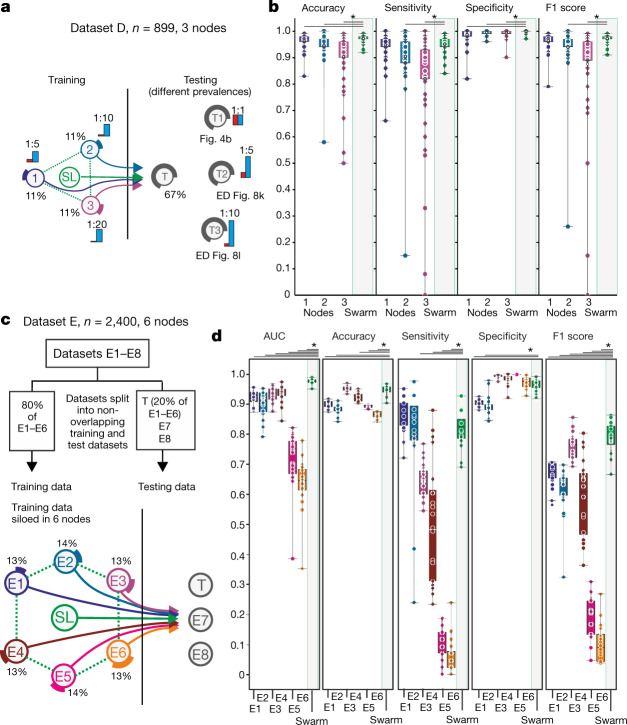
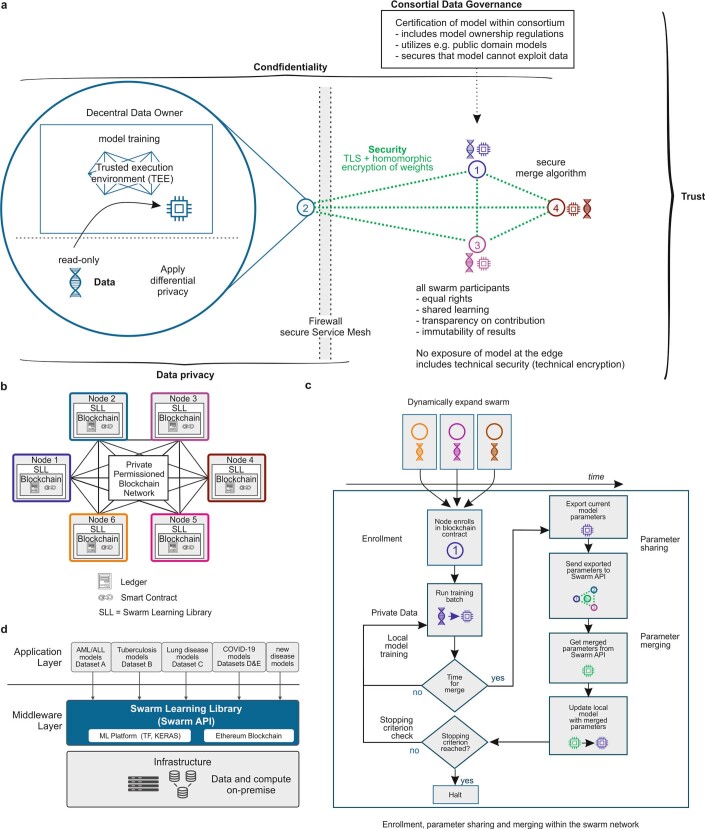
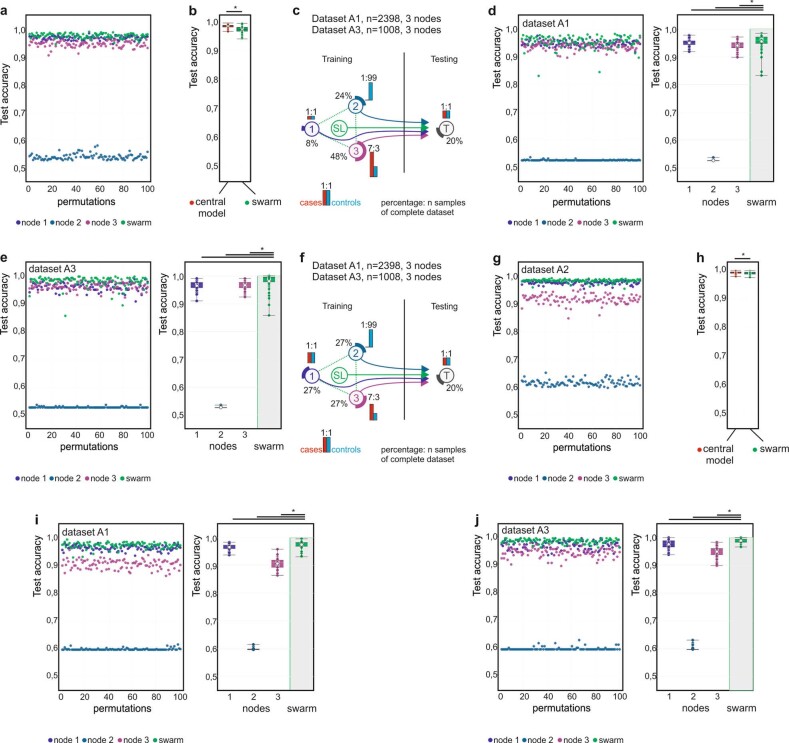
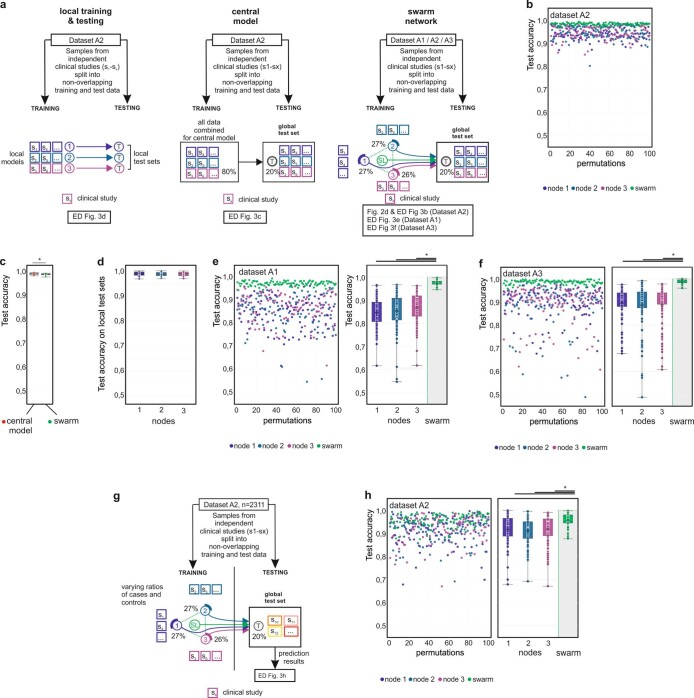
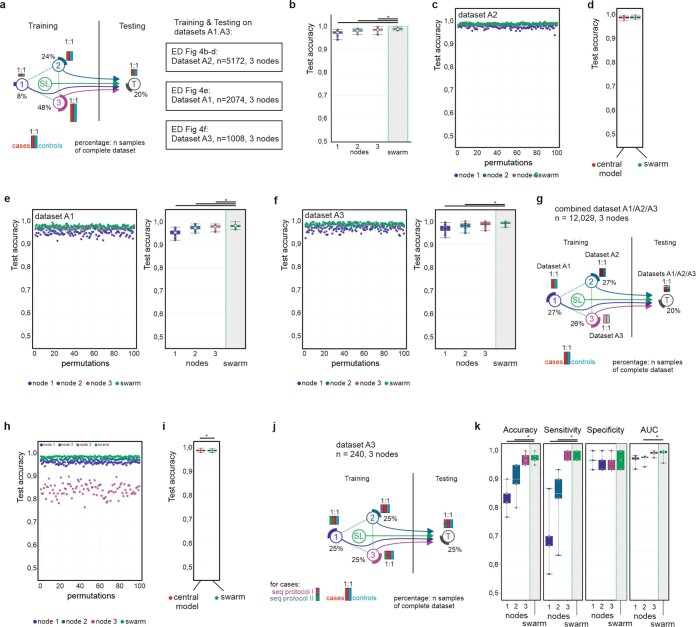
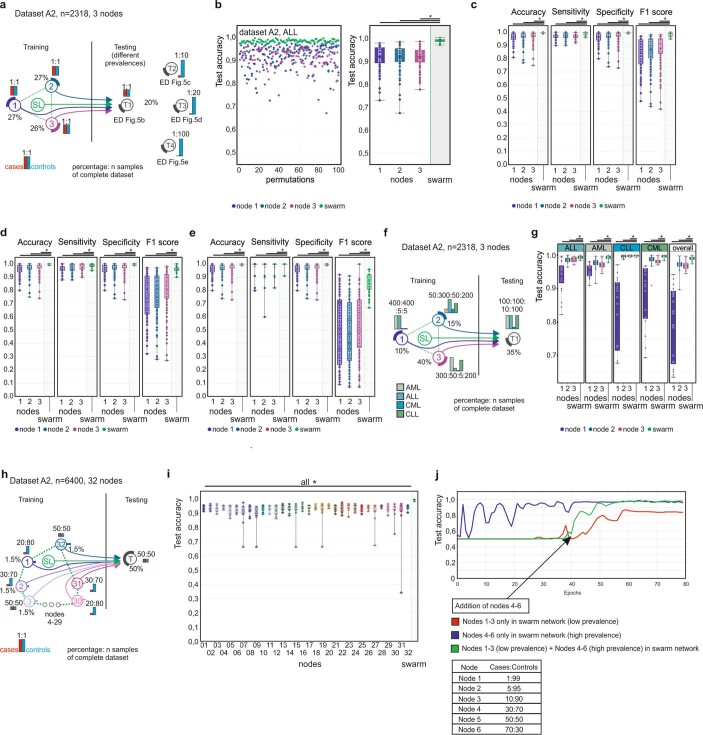
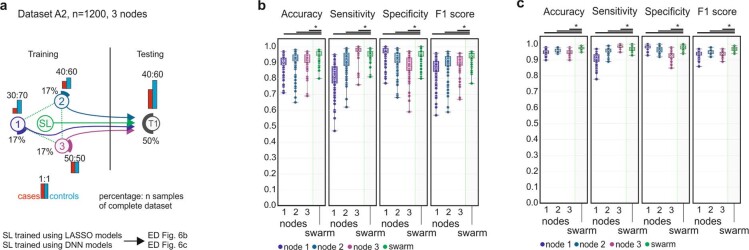
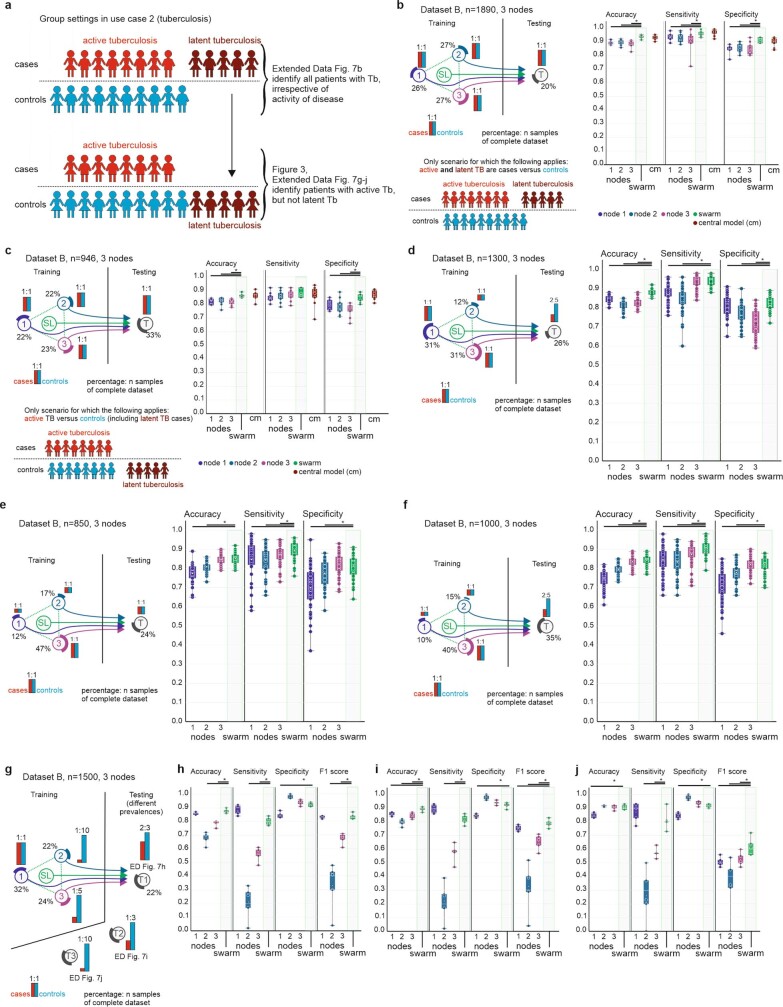
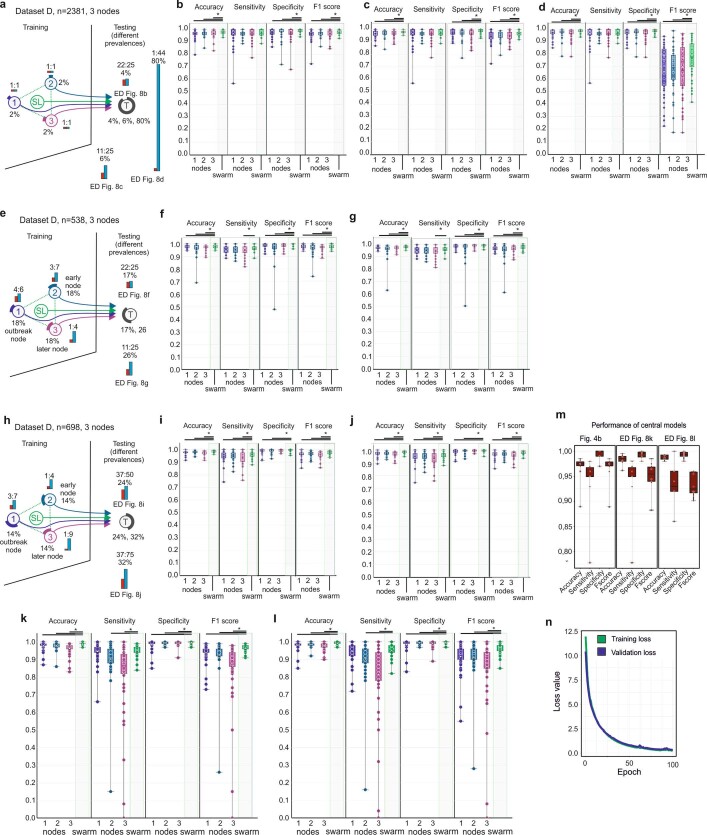
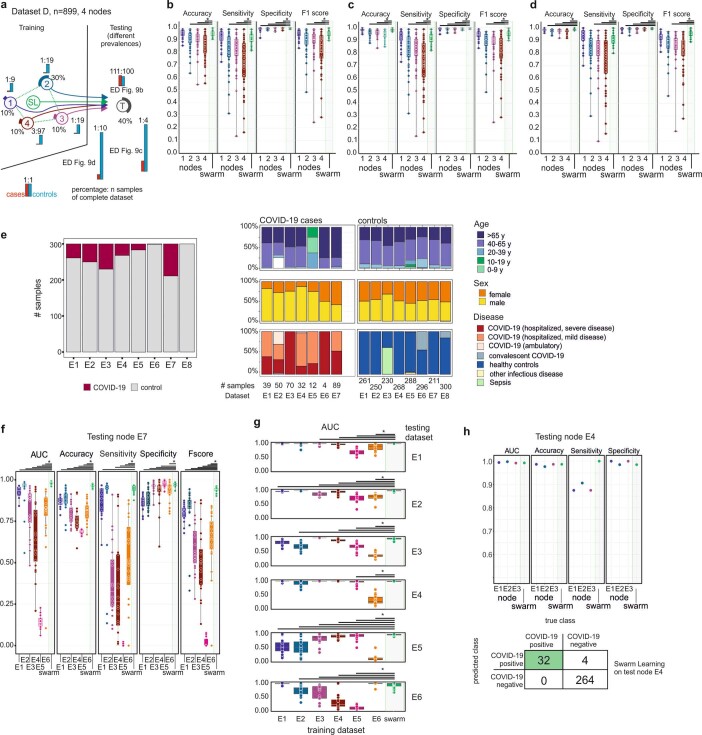
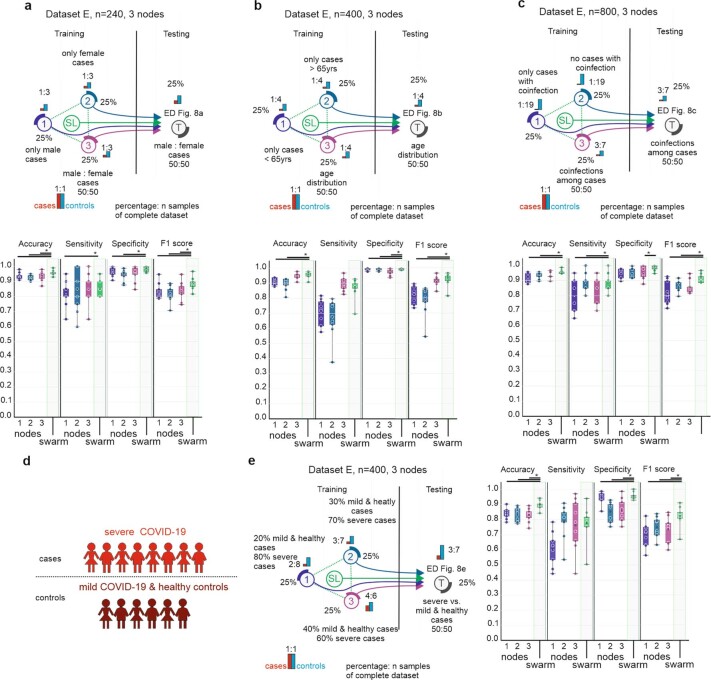
Fast and reliable detection of patients with severe and heterogeneous illnesses is a major goal of precision medicine1,2. Patients with leukaemia can be identified using machine learning on the basis of their blood transcriptomes3. However, there is an increasing divide between what is technically possible and what is allowed, because of privacy legislation4,5. Here, to facilitate the integration of any medical data from any data owner worldwide without violating privacy laws, we introduce Swarm Learning-a decentralized machine-learning approach that unites edge computing, blockchain-based peer-to-peer networking and coordination while maintaining confidentiality without the need for a central coordinator, thereby going beyond federated learning. To illustrate the feasibility of using Swarm Learning to develop disease classifiers using distributed data, we chose four use cases of heterogeneous diseases (COVID-19, tuberculosis, leukaemia and lung pathologies). With more than 16,400 blood transcriptomes derived from 127 clinical studies with non-uniform distributions of cases and controls and substantial study biases, as well as more than 95,000 chest X-ray images, we show that Swarm Learning classifiers outperform those developed at individual sites. In addition, Swarm Learning completely fulfils local confidentiality regulations by design. We believe that this approach will notably accelerate the introduction of precision medicine.
Conflict of interest statement
H.S., K.L.S., S. Manamohan, Saikat Mukherjee, V.G., R.S., C.S., M.D., B.M, C.M.S., S.C., M.S.W. and E.L.G. are employees of Hewlett Packard Enterprise. Hewlett Packard Enterprise developed the SLL in its entirety as described in this work and has submitted multiple associated patent applications. E.J.G.-B. received honoraria from AbbVie USA, Abbott CH, InflaRx GmbH, MSD Greece, XBiotech Inc. and Angelini Italy and independent educational grants from AbbVie, Abbott, Astellas Pharma Europe, AxisShield, bioMérieux Inc, InflaRx GmbH, and XBiotech Inc. All other authors declare no competing interests.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Molecular Biology Databases
