

Incorporating support vector machine with sequential minimal optimization to identify anticancer peptides
- PMID: 34051755
- PMCID: PMC8164238
- DOI: 10.1186/s12859-021-03965-4
Incorporating support vector machine with sequential minimal optimization to identify anticancer peptides
Abstract
Background: Cancer is one of the major causes of death worldwide. To treat cancer, the use of anticancer peptides (ACPs) has attracted increased attention in recent years. ACPs are a unique group of small molecules that can target and kill cancer cells fast and directly. However, identifying ACPs by wet-lab experiments is time-consuming and labor-intensive. Therefore, it is significant to develop computational tools for ACPs prediction. Though some ACP prediction tools have been developed recently, their performances are not well enough and most of them do not offer a function to distinguish ACPs from antimicrobial peptides (AMPs). Considering the fact that a growing number of studies have shown that some AMPs exhibit anticancer function, this work tries to build a model for distinguishing AMPs from ACPs in addition to a model that predicts ACPs from whole peptides.
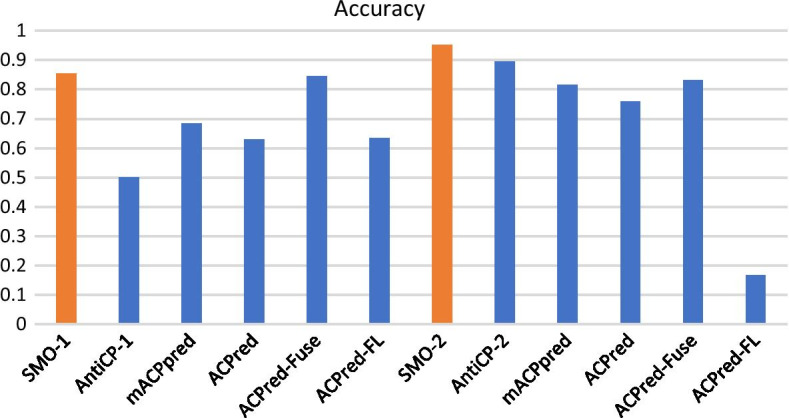
Results: This study chooses amino acid composition, N5C5, k-space, position-specific scoring matrix (PSSM) as features, and analyzes them by machine learning methods, including support vector machine (SVM) and sequential minimal optimization (SMO) to build a model (model 2) for distinguishing ACPs from whole peptides. Another model (model 1) that distinguishes ACPs from AMPs is also developed. Comparing to previous models, models developed in this research show better performance (accuracy: 85.5% for model 1 and 95.2% for model 2).
Conclusions: This work utilizes a new feature, PSSM, which contributes to better performance than other features. In addition to SVM, SMO is used in this research for optimizing SVM and the SMO-optimized models show better performance than non-optimized models. Last but not least, this work provides two different functions, including distinguishing ACPs from AMPs and distinguishing ACPs from all peptides. The second SMO-optimized model, which utilizes PSSM as a feature, performs better than all other existing tools.
Keywords: Anticancer peptides; PSSM; SMO; SVM.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures





References
-
- Gatti L, Zunino F. Overview of tumor cell chemoresistance mechanisms. Methods Mol Med. 2005;111:127–148. - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
