

Embedding optimization reveals long-lasting history dependence in neural spiking activity
- PMID: 34061837
- PMCID: PMC8205186
- DOI: 10.1371/journal.pcbi.1008927
Embedding optimization reveals long-lasting history dependence in neural spiking activity
Abstract
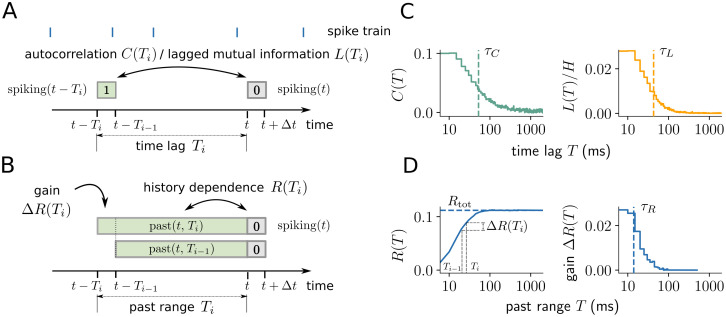
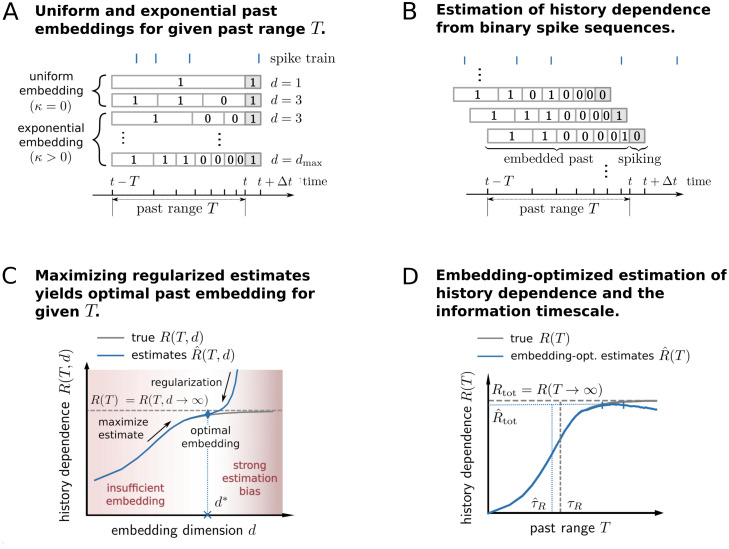
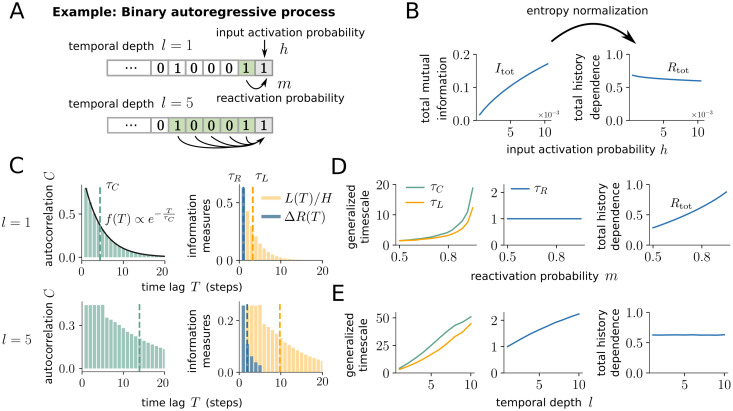
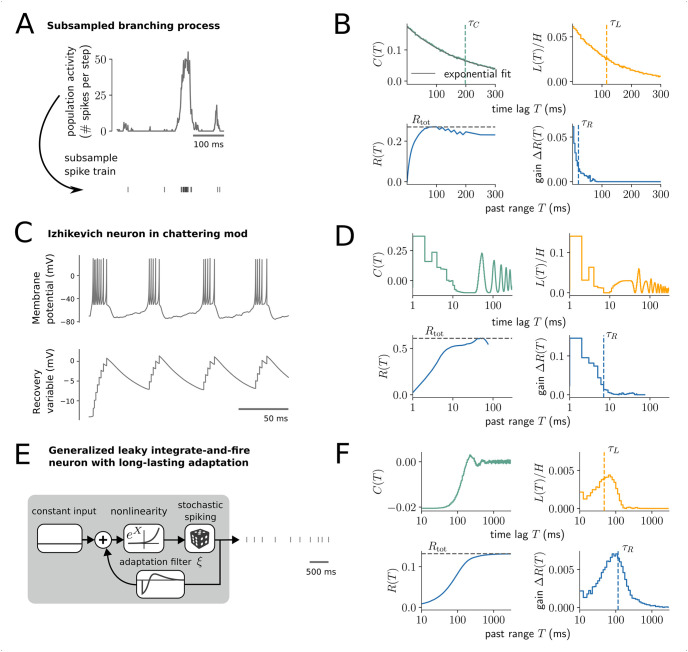
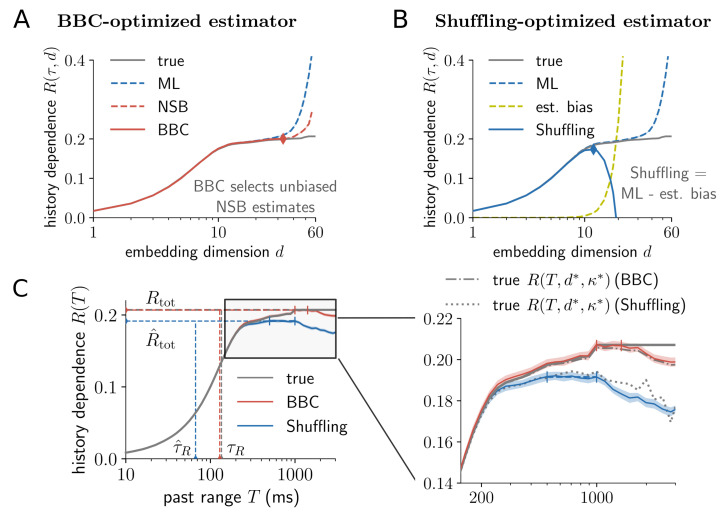
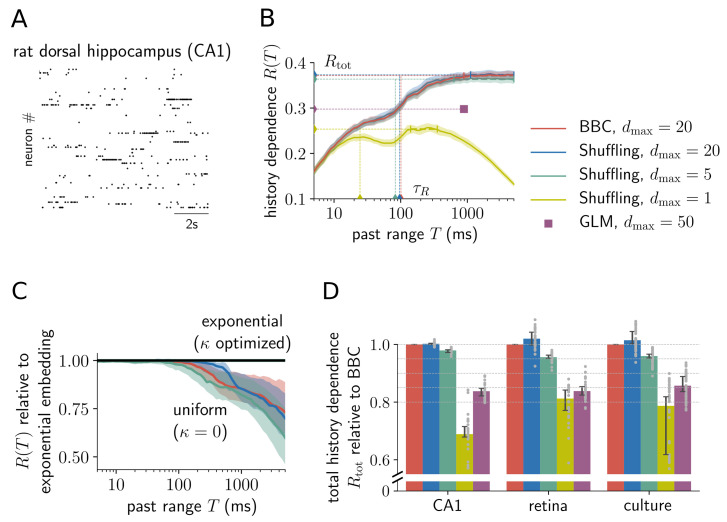
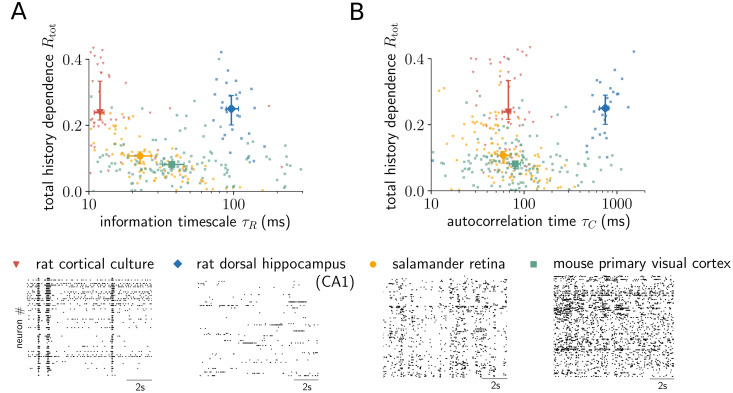
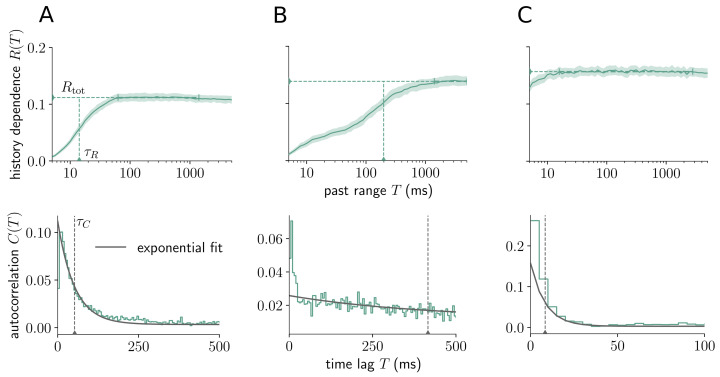
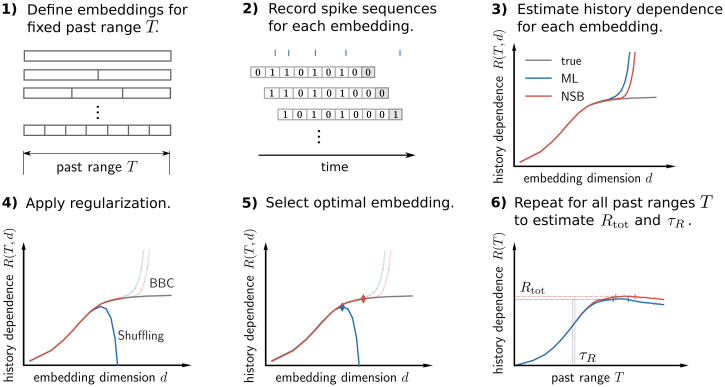
Information processing can leave distinct footprints on the statistics of neural spiking. For example, efficient coding minimizes the statistical dependencies on the spiking history, while temporal integration of information may require the maintenance of information over different timescales. To investigate these footprints, we developed a novel approach to quantify history dependence within the spiking of a single neuron, using the mutual information between the entire past and current spiking. This measure captures how much past information is necessary to predict current spiking. In contrast, classical time-lagged measures of temporal dependence like the autocorrelation capture how long-potentially redundant-past information can still be read out. Strikingly, we find for model neurons that our method disentangles the strength and timescale of history dependence, whereas the two are mixed in classical approaches. When applying the method to experimental data, which are necessarily of limited size, a reliable estimation of mutual information is only possible for a coarse temporal binning of past spiking, a so-called past embedding. To still account for the vastly different spiking statistics and potentially long history dependence of living neurons, we developed an embedding-optimization approach that does not only vary the number and size, but also an exponential stretching of past bins. For extra-cellular spike recordings, we found that the strength and timescale of history dependence indeed can vary independently across experimental preparations. While hippocampus indicated strong and long history dependence, in visual cortex it was weak and short, while in vitro the history dependence was strong but short. This work enables an information-theoretic characterization of history dependence in recorded spike trains, which captures a footprint of information processing that is beyond time-lagged measures of temporal dependence. To facilitate the application of the method, we provide practical guidelines and a toolbox.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures

Similar articles
-
The possible role of spike patterns in cortical information processing.J Comput Neurosci. 2005 Jun;18(3):275-86. doi: 10.1007/s10827-005-0330-2. J Comput Neurosci. 2005. PMID: 15830164
-
Spiking Noise and Information Density of Neurons in Visual Area V2 of Infant Monkeys.J Neurosci. 2019 Jul 17;39(29):5673-5684. doi: 10.1523/JNEUROSCI.2023-18.2019. Epub 2019 May 30. J Neurosci. 2019. PMID: 31147523 Free PMC article.
-
Construction and analysis of non-Poisson stimulus-response models of neural spiking activity.J Neurosci Methods. 2001 Jan 30;105(1):25-37. doi: 10.1016/s0165-0270(00)00344-7. J Neurosci Methods. 2001. PMID: 11166363
-
Neuronal coding and spiking randomness.Eur J Neurosci. 2007 Nov;26(10):2693-701. doi: 10.1111/j.1460-9568.2007.05880.x. Eur J Neurosci. 2007. PMID: 18001270 Review.
-
From artificial neural networks to spiking neuron populations and back again.Neural Netw. 2001 Jul-Sep;14(6-7):941-53. doi: 10.1016/s0893-6080(01)00068-5. Neural Netw. 2001. PMID: 11665784 Review.
Cited by
-
Early lock-in of structured and specialised information flows during neural development.Elife. 2022 Mar 14;11:e74651. doi: 10.7554/eLife.74651. Elife. 2022. PMID: 35286256 Free PMC article.
-
Bias-free estimation of information content in temporally sparse neuronal activity.PLoS Comput Biol. 2022 Feb 11;18(2):e1009832. doi: 10.1371/journal.pcbi.1009832. eCollection 2022 Feb. PLoS Comput Biol. 2022. PMID: 35148310 Free PMC article.
-
Information-theoretic analyses of neural data to minimize the effect of researchers' assumptions in predictive coding studies.PLoS Comput Biol. 2023 Nov 17;19(11):e1011567. doi: 10.1371/journal.pcbi.1011567. eCollection 2023 Nov. PLoS Comput Biol. 2023. PMID: 37976328 Free PMC article.
-
An information theoretic method to resolve millisecond-scale spike timing precision in a comprehensive motor program.PLoS Comput Biol. 2023 Jun 12;19(6):e1011170. doi: 10.1371/journal.pcbi.1011170. eCollection 2023 Jun. PLoS Comput Biol. 2023. PMID: 37307288 Free PMC article.
-
Signatures of hierarchical temporal processing in the mouse visual system.PLoS Comput Biol. 2024 Aug 22;20(8):e1012355. doi: 10.1371/journal.pcbi.1012355. eCollection 2024 Aug. PLoS Comput Biol. 2024. PMID: 39173067 Free PMC article.
References
-
- Barlow HB, et al.. Possible principles underlying the transformation of sensory messages. Sensory communication. 1961;1(01).
-
- Rieke F. Spikes: exploring the neural code. MIT press; 1999.
-
- Lizier JT. Computation in Complex Systems. In: Lizier JT, editor. The Local Information Dynamics of Distributed Computation in Complex Systems. Springer Theses. Berlin, Heidelberg: Springer Berlin Heidelberg; 2013. p. 13–52. Available from: 10.1007/978-3-642-32952-4_2. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
