

Rapid genotype imputation from sequence with reference panels
- PMID: 34083788
- PMCID: PMC7611184
- DOI: 10.1038/s41588-021-00877-0
Rapid genotype imputation from sequence with reference panels
Abstract
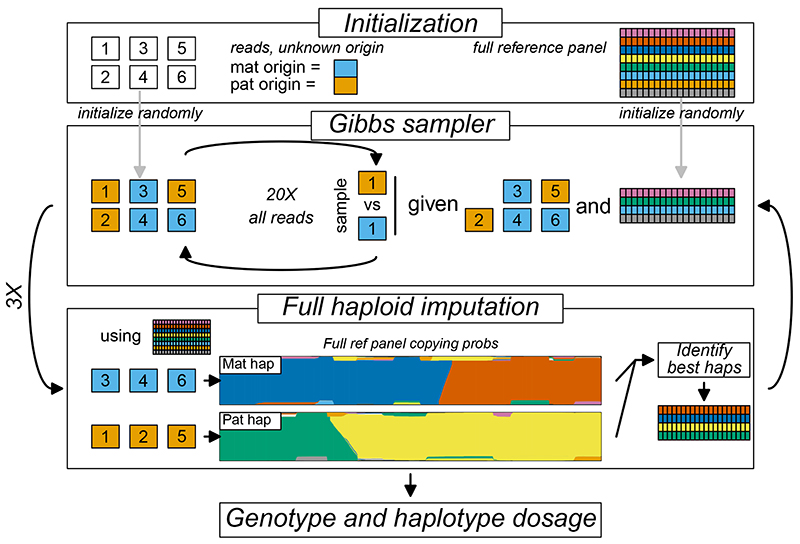
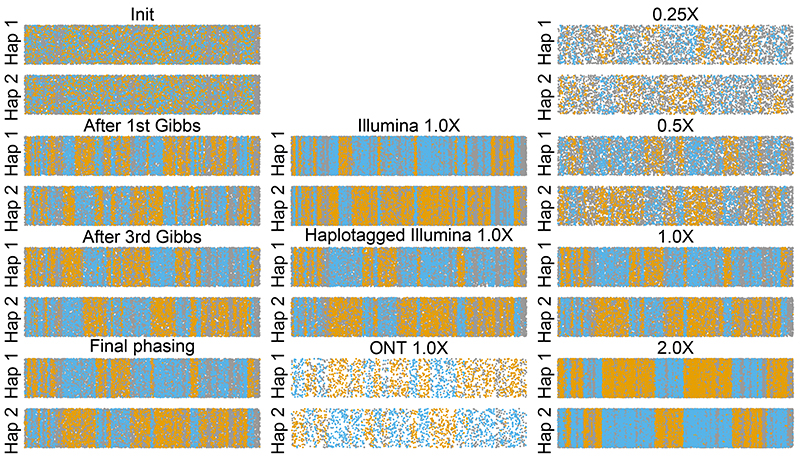
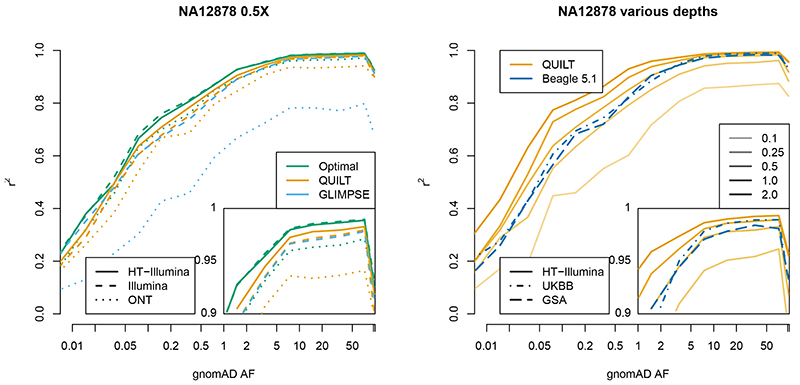
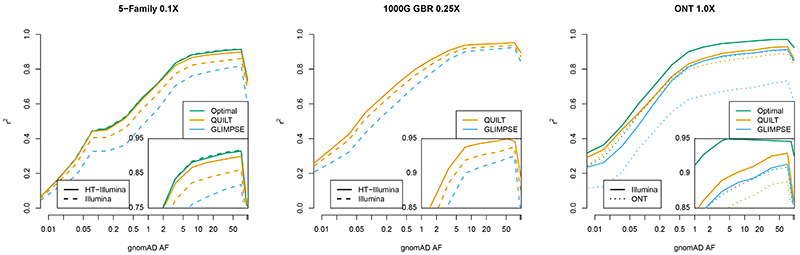
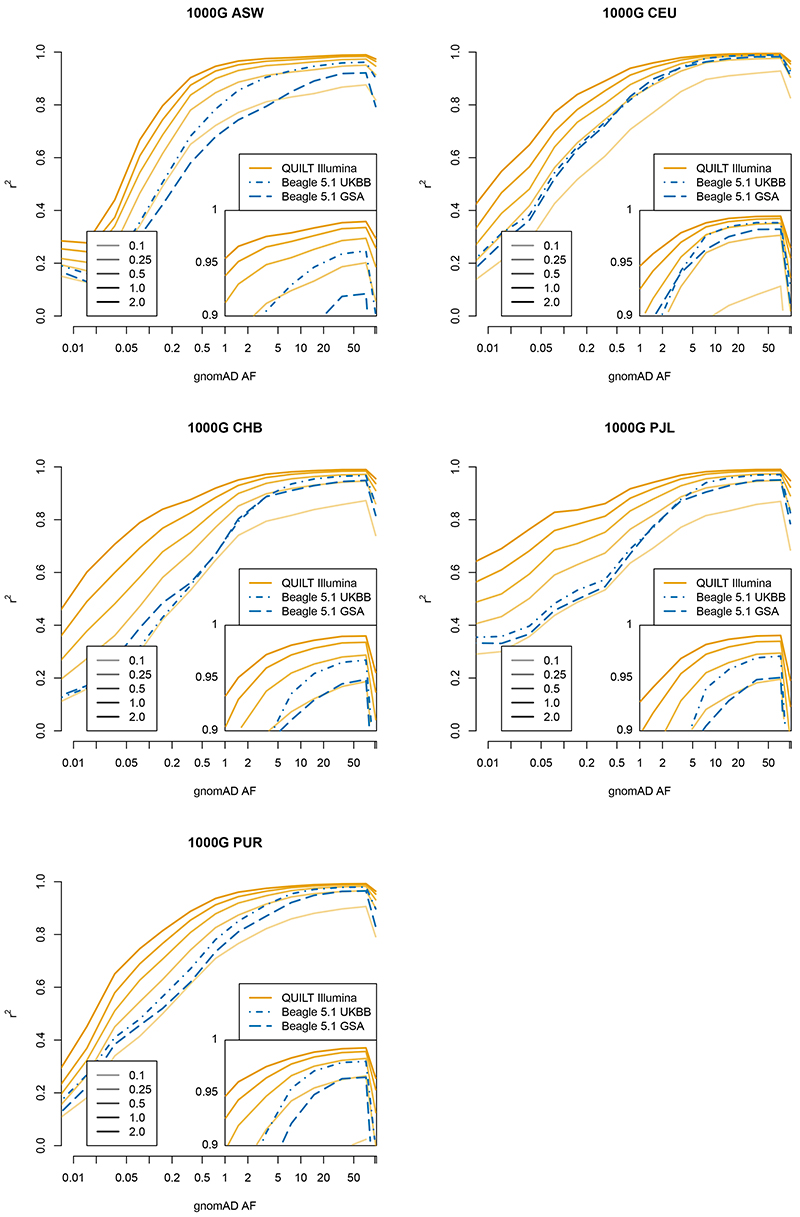
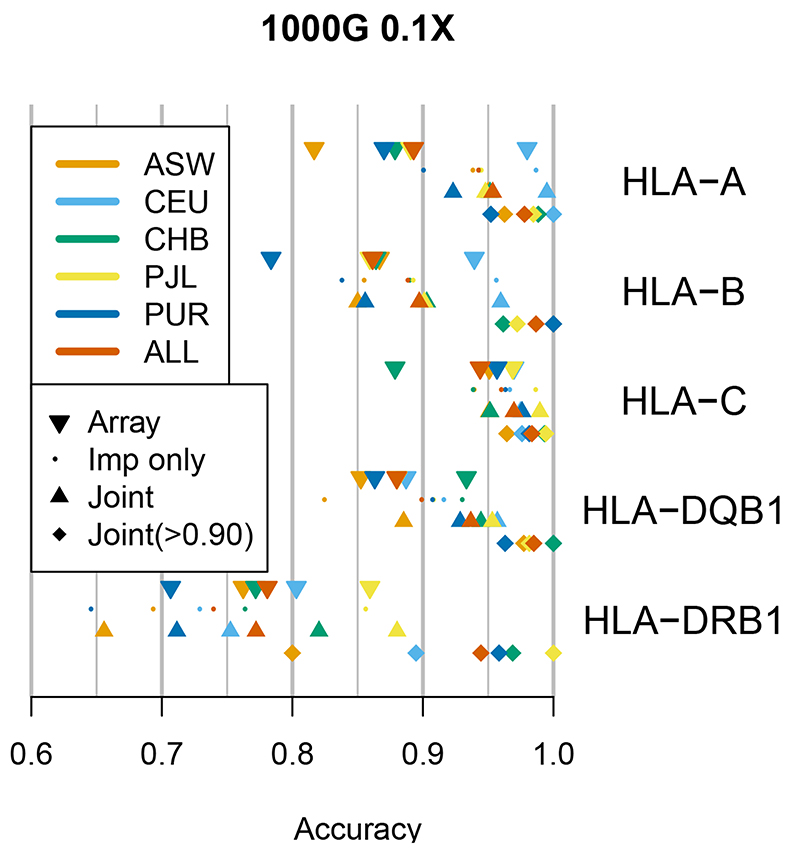
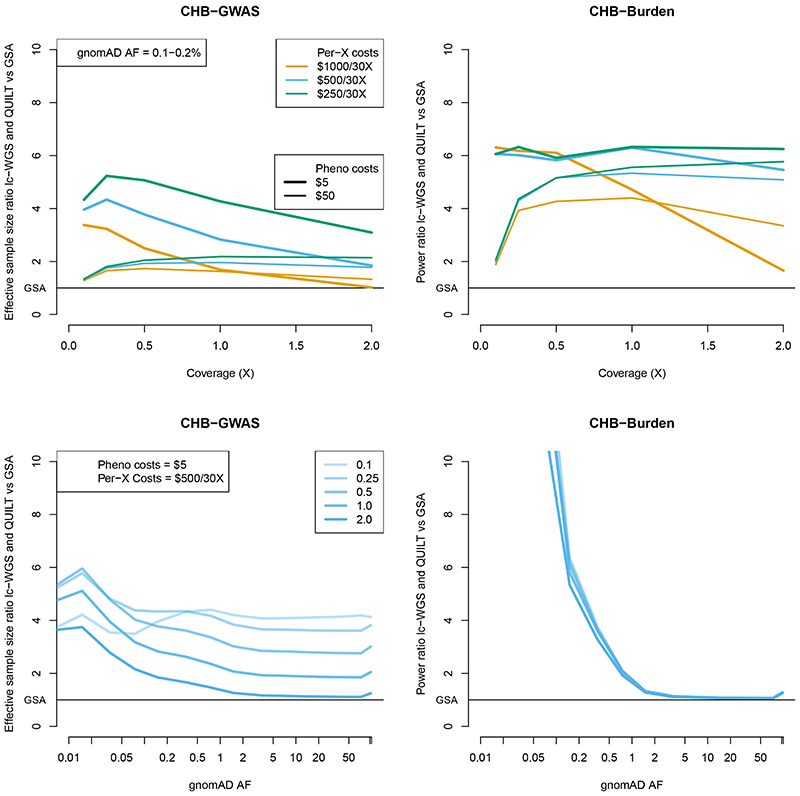
Inexpensive genotyping methods are essential to modern genomics. Here we present QUILT, which performs diploid genotype imputation using low-coverage whole-genome sequence data. QUILT employs Gibbs sampling to partition reads into maternal and paternal sets, facilitating rapid haploid imputation using large reference panels. We show this partitioning to be accurate over many megabases, enabling highly accurate imputation close to theoretical limits and outperforming existing methods. Moreover, QUILT can impute accurately using diverse technologies, including long reads from Oxford Nanopore Technologies, and a new form of low-cost barcoded Illumina sequencing called haplotagging, with the latter showing improved accuracy at low coverages. Relative to DNA genotyping microarrays, QUILT offers improved accuracy at reduced cost, particularly for diverse populations that are traditionally underserved in modern genomic analyses, with accuracy nearly doubling at rare SNPs. Finally, QUILT can accurately impute (four-digit) human leukocyte antigen types, the first such method from low-coverage sequence data.
© 2021. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
M.K. and Y.F.C. declare competing financial interests in the form of patent and employment by the Max Planck Society. The remaining authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
