

Determinants of penetrance and variable expressivity in monogenic metabolic conditions across 77,184 exomes
- PMID: 34108472
- PMCID: PMC8190084
- DOI: 10.1038/s41467-021-23556-4
Determinants of penetrance and variable expressivity in monogenic metabolic conditions across 77,184 exomes
Abstract
Hundreds of thousands of genetic variants have been reported to cause severe monogenic diseases, but the probability that a variant carrier develops the disease (termed penetrance) is unknown for virtually all of them. Additionally, the clinical utility of common polygenetic variation remains uncertain. Using exome sequencing from 77,184 adult individuals (38,618 multi-ancestral individuals from a type 2 diabetes case-control study and 38,566 participants from the UK Biobank, for whom genotype array data were also available), we apply clinical standard-of-care gene variant curation for eight monogenic metabolic conditions. Rare variants causing monogenic diabetes and dyslipidemias display effect sizes significantly larger than the top 1% of the corresponding polygenic scores. Nevertheless, penetrance estimates for monogenic variant carriers average 60% or lower for most conditions. We assess epidemiologic and genetic factors contributing to risk prediction in monogenic variant carriers, demonstrating that inclusion of polygenic variation significantly improves biomarker estimation for two monogenic dyslipidemias.
Conflict of interest statement
M.I.M. has served on advisory panels for Pfizer, Novo Nordisk, and Zoe Global; has received honoraria from Merck, Pfizer, Novo Nordisk, and Eli Lilly; has stock options in Zoe Global; and has received research funding from Abbvie, Astra Zeneca, Boehringer Ingelheim, Eli Lilly, Janssen, Merck, Novo Nordisk, Pfizer, Roche, Sanofi Aventis, and Servier & Takeda. M.I.M. is an employee of Genentech and holds stock in Roche. Psaty serves on the Steering Committee of the Yale Open Data Access Project funded by Johnson & Johnson. C.J.O’D. is an employee of the Novartis Institute for Biomedical Research. All other authors reported no relevant competing interests.
Figures
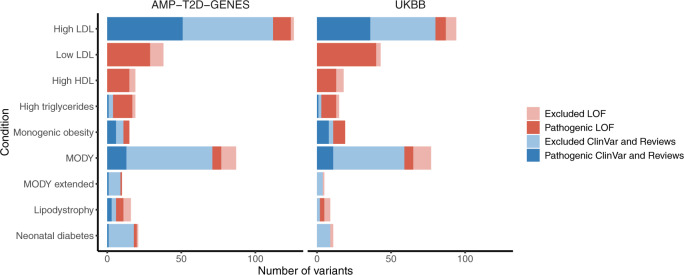
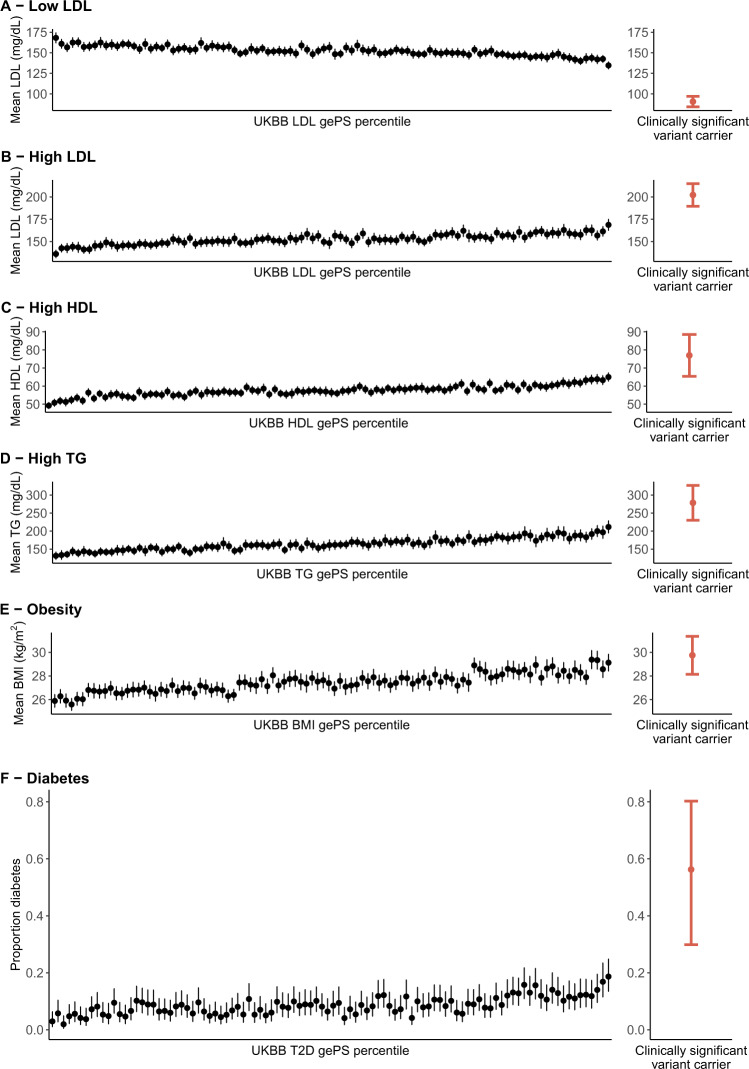
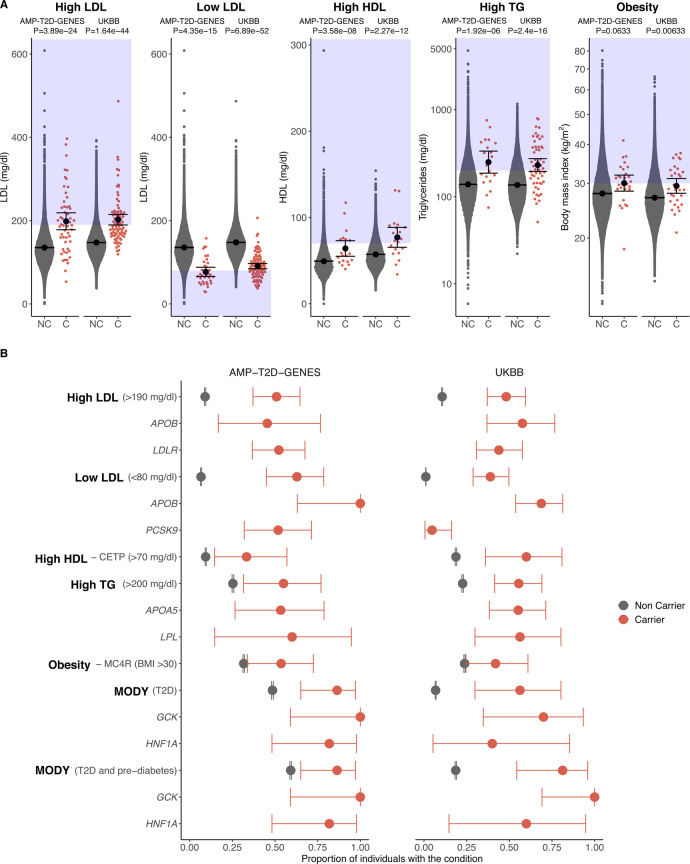
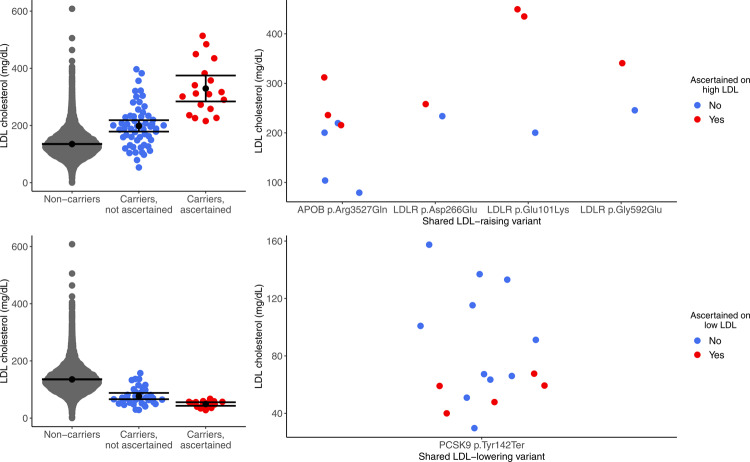
References
Publication types
MeSH terms
Substances
Grants and funding
- R01 DK093757/DK/NIDDK NIH HHS/United States
- R56 DK062370/DK/NIDDK NIH HHS/United States
- K12 HD052896/HD/NICHD NIH HHS/United States
- P30 DK020541/DK/NIDDK NIH HHS/United States
- MC_PC_13040/MRC_/Medical Research Council/United Kingdom
- MR/M501633/1/MRC_/Medical Research Council/United Kingdom
- R01 DK125490/DK/NIDDK NIH HHS/United States
- K24 DK110550/DK/NIDDK NIH HHS/United States
- MC_QA137853/MRC_/Medical Research Council/United Kingdom
- K23 DK114551/DK/NIDDK NIH HHS/United States
- 212945/Z/18/Z/WT_/Wellcome Trust/United Kingdom
- R01 DK072193/DK/NIDDK NIH HHS/United States
- R01 HG006399/HG/NHGRI NIH HHS/United States
- K99 DK127196/DK/NIDDK NIH HHS/United States
- R01 DK062370/DK/NIDDK NIH HHS/United States
- R01 HL105756/HL/NHLBI NIH HHS/United States
- U01 DK062370/DK/NIDDK NIH HHS/United States
- U01 DK105554/DK/NIDDK NIH HHS/United States
- P30 DK020572/DK/NIDDK NIH HHS/United States
- MR/K007017/1/MRC_/Medical Research Council/United Kingdom
- P60 DK020541/DK/NIDDK NIH HHS/United States
- MC_PC_17228/MRC_/Medical Research Council/United Kingdom
- UM1 DK078616/DK/NIDDK NIH HHS/United States
