

A survey on deep multimodal learning for computer vision: advances, trends, applications, and datasets
- PMID: 34131356
- PMCID: PMC8192112
- DOI: 10.1007/s00371-021-02166-7
A survey on deep multimodal learning for computer vision: advances, trends, applications, and datasets
Abstract
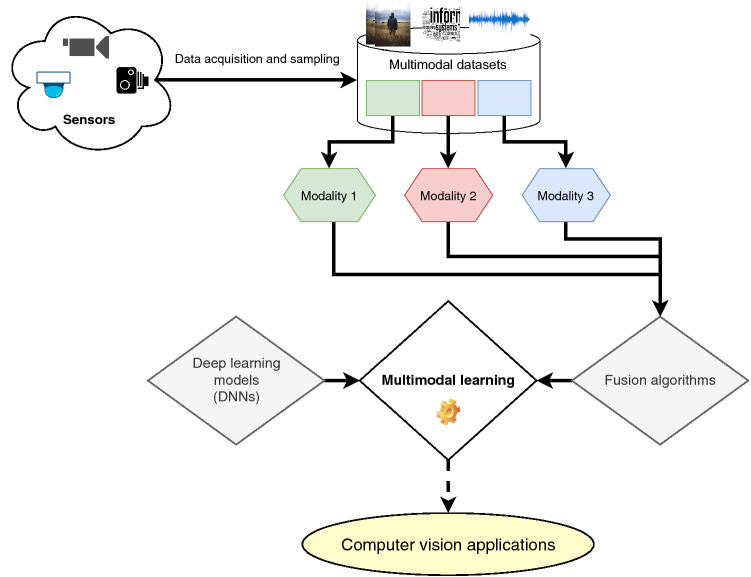
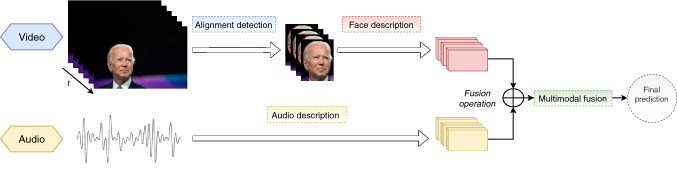
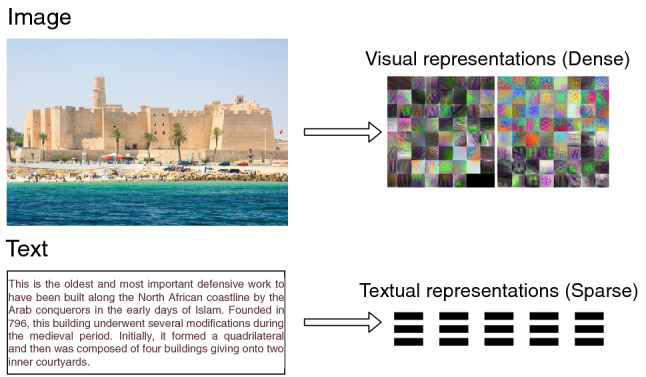
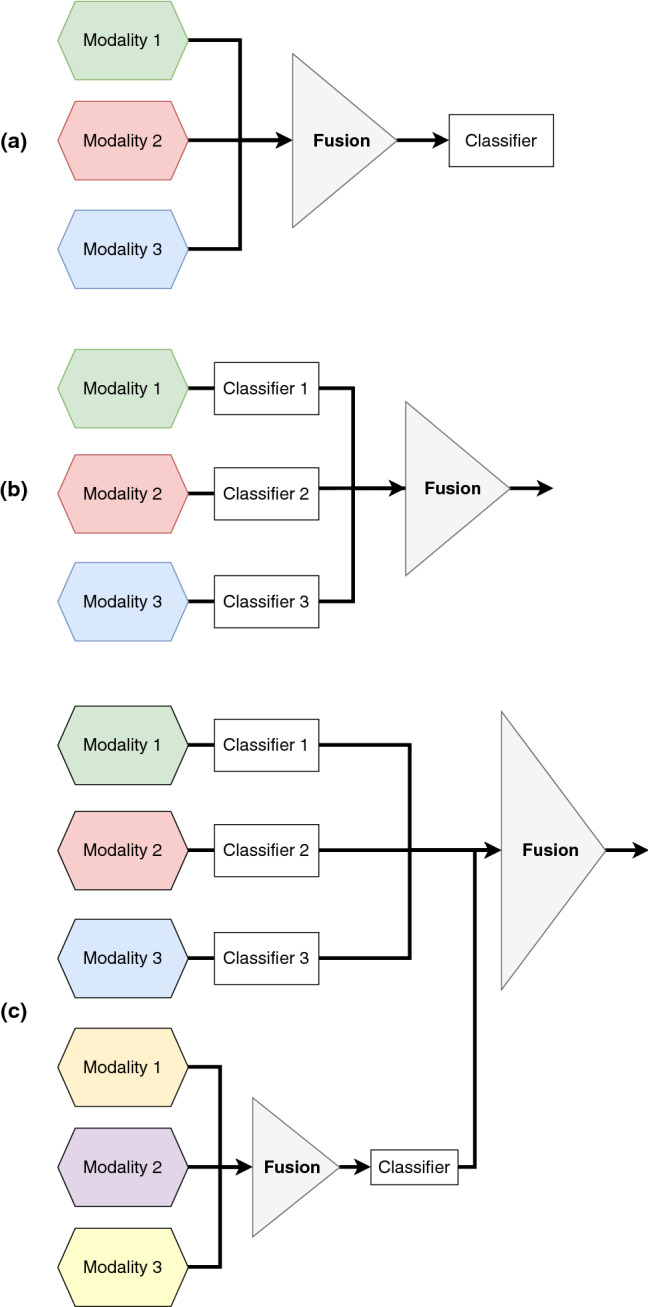
The research progress in multimodal learning has grown rapidly over the last decade in several areas, especially in computer vision. The growing potential of multimodal data streams and deep learning algorithms has contributed to the increasing universality of deep multimodal learning. This involves the development of models capable of processing and analyzing the multimodal information uniformly. Unstructured real-world data can inherently take many forms, also known as modalities, often including visual and textual content. Extracting relevant patterns from this kind of data is still a motivating goal for researchers in deep learning. In this paper, we seek to improve the understanding of key concepts and algorithms of deep multimodal learning for the computer vision community by exploring how to generate deep models that consider the integration and combination of heterogeneous visual cues across sensory modalities. In particular, we summarize six perspectives from the current literature on deep multimodal learning, namely: multimodal data representation, multimodal fusion (i.e., both traditional and deep learning-based schemes), multitask learning, multimodal alignment, multimodal transfer learning, and zero-shot learning. We also survey current multimodal applications and present a collection of benchmark datasets for solving problems in various vision domains. Finally, we highlight the limitations and challenges of deep multimodal learning and provide insights and directions for future research.
Keywords: Applications; Computer vision; Datasets; Deep learning; Multimodal learning; Sensory modalities.
© The Author(s), under exclusive licence to Springer-Verlag GmbH Germany, part of Springer Nature 2021.
Conflict of interest statement
Conflict of interestThe authors declare that they have no conflict of interest.
Figures

References
-
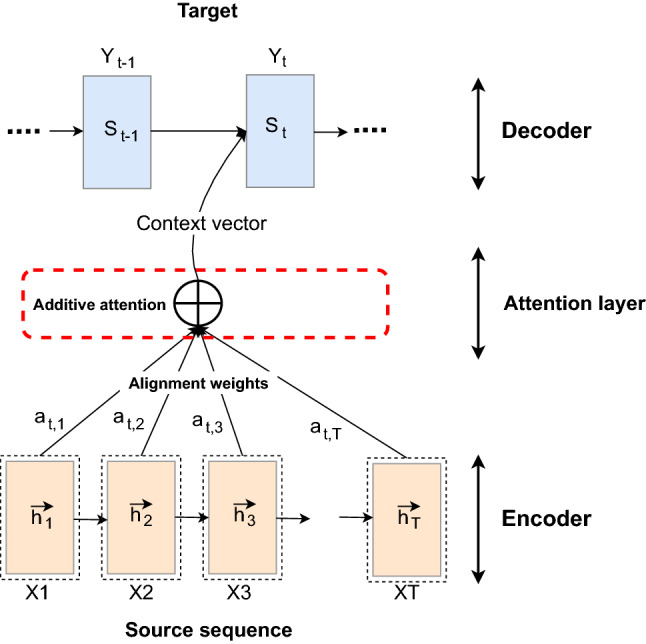
- Bahdanau, D., Cho, K., Bengio, Y.: Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473 (2016)
-
- Bayoudh, K.: From machine learning to deep learning, (1st ed.), Ebook, ISBN: 9781387465606 (2017)
-
- Lawrence, S., Giles, C.L.: Overfitting and neural networks: conjugate gradient and backpropagation. In: Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, pp. 114–119 (2000)
LinkOut - more resources
Full Text Sources
Other Literature Sources