

Deep learning prediction of mild cognitive impairment conversion to Alzheimer's disease at 3 years after diagnosis using longitudinal and whole-brain 3D MRI
- PMID: 34141888
- PMCID: PMC8176545
- DOI: 10.7717/peerj-cs.560
Deep learning prediction of mild cognitive impairment conversion to Alzheimer's disease at 3 years after diagnosis using longitudinal and whole-brain 3D MRI
Abstract
Background: While there is no cure for Alzheimer's disease (AD), early diagnosis and accurate prognosis of AD may enable or encourage lifestyle changes, neurocognitive enrichment, and interventions to slow the rate of cognitive decline. The goal of our study was to develop and evaluate a novel deep learning algorithm to predict mild cognitive impairment (MCI) to AD conversion at three years after diagnosis using longitudinal and whole-brain 3D MRI.
Methods: This retrospective study consisted of 320 normal cognition (NC), 554 MCI, and 237 AD patients. Longitudinal data include T1-weighted 3D MRI obtained at initial presentation with diagnosis of MCI and at 12-month follow up. Whole-brain 3D MRI volumes were used without a priori segmentation of regional structural volumes or cortical thicknesses. MRIs of the AD and NC cohort were used to train a deep learning classification model to obtain weights to be applied via transfer learning for prediction of MCI patient conversion to AD at three years post-diagnosis. Two (zero-shot and fine tuning) transfer learning methods were evaluated. Three different convolutional neural network (CNN) architectures (sequential, residual bottleneck, and wide residual) were compared. Data were split into 75% and 25% for training and testing, respectively, with 4-fold cross validation. Prediction accuracy was evaluated using balanced accuracy. Heatmaps were generated.
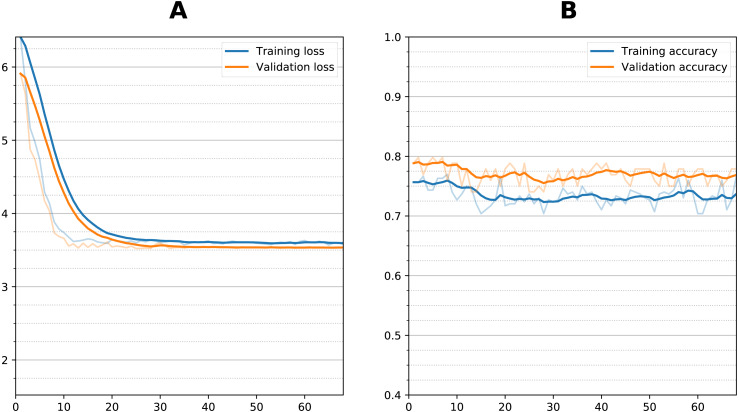
Results: The sequential convolutional approach yielded slightly better performance than the residual-based architecture, the zero-shot transfer learning approach yielded better performance than fine tuning, and CNN using longitudinal data performed better than CNN using a single timepoint MRI in predicting MCI conversion to AD. The best CNN model for predicting MCI conversion to AD at three years after diagnosis yielded a balanced accuracy of 0.793. Heatmaps of the prediction model showed regions most relevant to the network including the lateral ventricles, periventricular white matter and cortical gray matter.
Conclusions: This is the first convolutional neural network model using longitudinal and whole-brain 3D MRIs without extracting regional brain volumes or cortical thicknesses to predict future MCI to AD conversion at 3 years after diagnosis. This approach could lead to early prediction of patients who are likely to progress to AD and thus may lead to better management of the disease.
Keywords: Artificial intelligence; Convolutional neural networks; Dementia; Machine learning; Magnetic resonance imaging; Neuroimaging.
©2021 Ocasio and Duong.
Conflict of interest statement
The authors declare there are no competing interests.
Figures






Similar articles
-
Predicting Four-Year's Alzheimer's Disease Onset Using Longitudinal Neurocognitive Tests and MRI Data Using Explainable Deep Convolutional Neural Networks.J Alzheimers Dis. 2024;97(1):459-469. doi: 10.3233/JAD-230893. J Alzheimers Dis. 2024. PMID: 38143361
-
Early Detection of Alzheimer's Disease Using Magnetic Resonance Imaging: A Novel Approach Combining Convolutional Neural Networks and Ensemble Learning.Front Neurosci. 2020 May 13;14:259. doi: 10.3389/fnins.2020.00259. eCollection 2020. Front Neurosci. 2020. PMID: 32477040 Free PMC article.
-
A parameter-efficient deep learning approach to predict conversion from mild cognitive impairment to Alzheimer's disease.Neuroimage. 2019 Apr 1;189:276-287. doi: 10.1016/j.neuroimage.2019.01.031. Epub 2019 Jan 14. Neuroimage. 2019. PMID: 30654174
-
Deep Learning in Alzheimer's Disease: Diagnostic Classification and Prognostic Prediction Using Neuroimaging Data.Front Aging Neurosci. 2019 Aug 20;11:220. doi: 10.3389/fnagi.2019.00220. eCollection 2019. Front Aging Neurosci. 2019. PMID: 31481890 Free PMC article.
-
Conventional machine learning and deep learning in Alzheimer's disease diagnosis using neuroimaging: A review.Front Comput Neurosci. 2023 Feb 6;17:1038636. doi: 10.3389/fncom.2023.1038636. eCollection 2023. Front Comput Neurosci. 2023. PMID: 36814932 Free PMC article. Review.
Cited by
-
Machine learning based multi-modal prediction of future decline toward Alzheimer's disease: An empirical study.PLoS One. 2022 Nov 16;17(11):e0277322. doi: 10.1371/journal.pone.0277322. eCollection 2022. PLoS One. 2022. PMID: 36383528 Free PMC article.
-
Comparing a pre-defined versus deep learning approach for extracting brain atrophy patterns to predict cognitive decline due to Alzheimer's disease in patients with mild cognitive symptoms.Alzheimers Res Ther. 2024 Mar 19;16(1):61. doi: 10.1186/s13195-024-01428-5. Alzheimers Res Ther. 2024. PMID: 38504336 Free PMC article.
-
Longitudinal structural MRI-based deep learning and radiomics features for predicting Alzheimer's disease progression.Alzheimers Res Ther. 2025 Aug 7;17(1):182. doi: 10.1186/s13195-025-01827-2. Alzheimers Res Ther. 2025. PMID: 40775357 Free PMC article.
-
Deep learning improves utility of tau PET in the study of Alzheimer's disease.Alzheimers Dement (Amst). 2021 Dec 31;13(1):e12264. doi: 10.1002/dad2.12264. eCollection 2021. Alzheimers Dement (Amst). 2021. PMID: 35005197 Free PMC article.
-
Mind the Gap: Does Brain Age Improve Alzheimer's Disease Prediction?bioRxiv [Preprint]. 2025 Jun 1:2024.11.16.623903. doi: 10.1101/2024.11.16.623903. bioRxiv. 2025. Update in: Hum Brain Mapp. 2025 Aug 15;46(12):e70276. doi: 10.1002/hbm.70276. PMID: 39605400 Free PMC article. Updated. Preprint.
References
-
- Cheng D, Liu M, Fu J, Wang Y. Ninth international conference on digital image processing (ICDIP 2017) International Society for Optics and Photonics; 2017. Classification of MR brain images by combination of multi-CNNs for AD diagnosis.
LinkOut - more resources
Full Text Sources