

Recent trends in biocatalysis
- PMID: 34142684
- PMCID: PMC8288269
- DOI: 10.1039/d0cs01575j
Recent trends in biocatalysis
Abstract
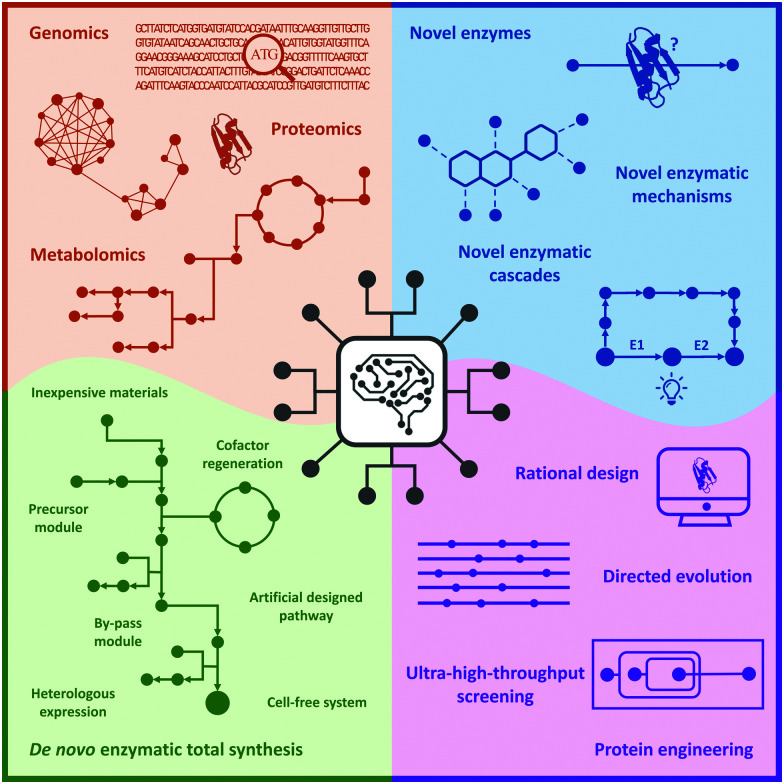
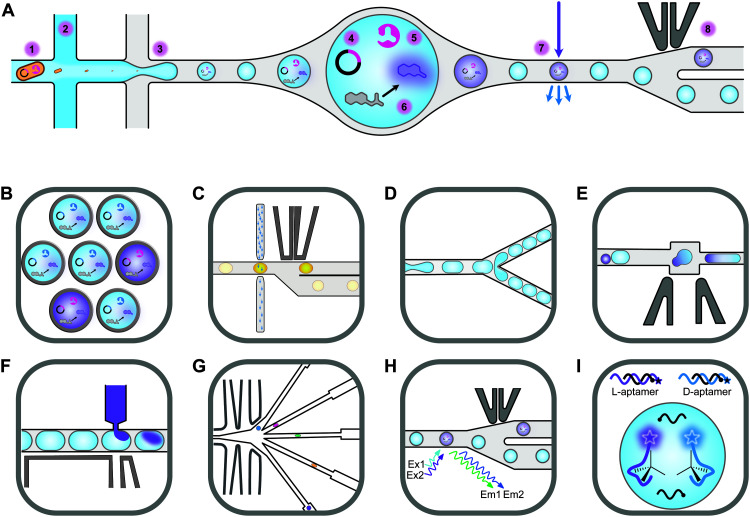
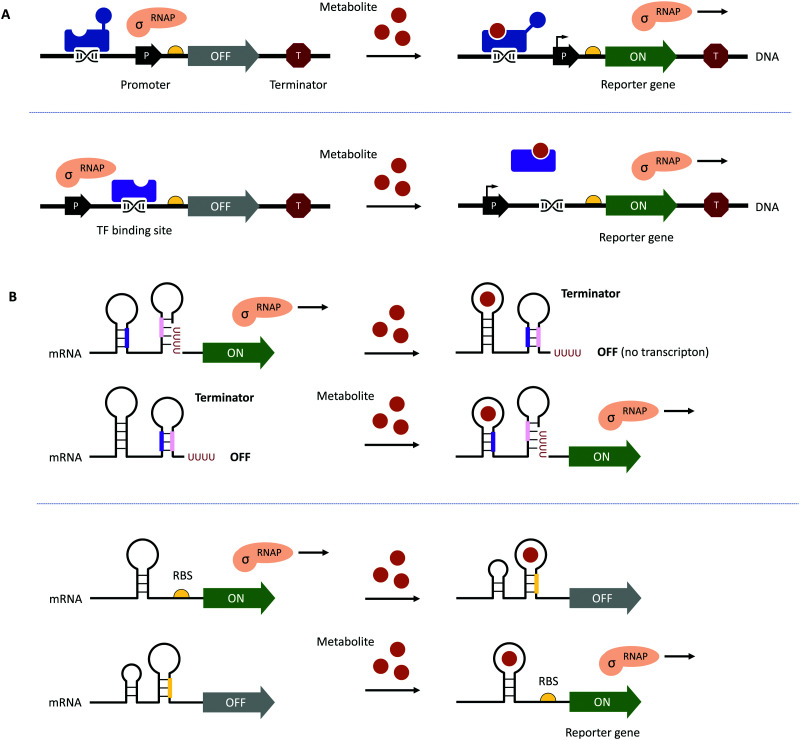
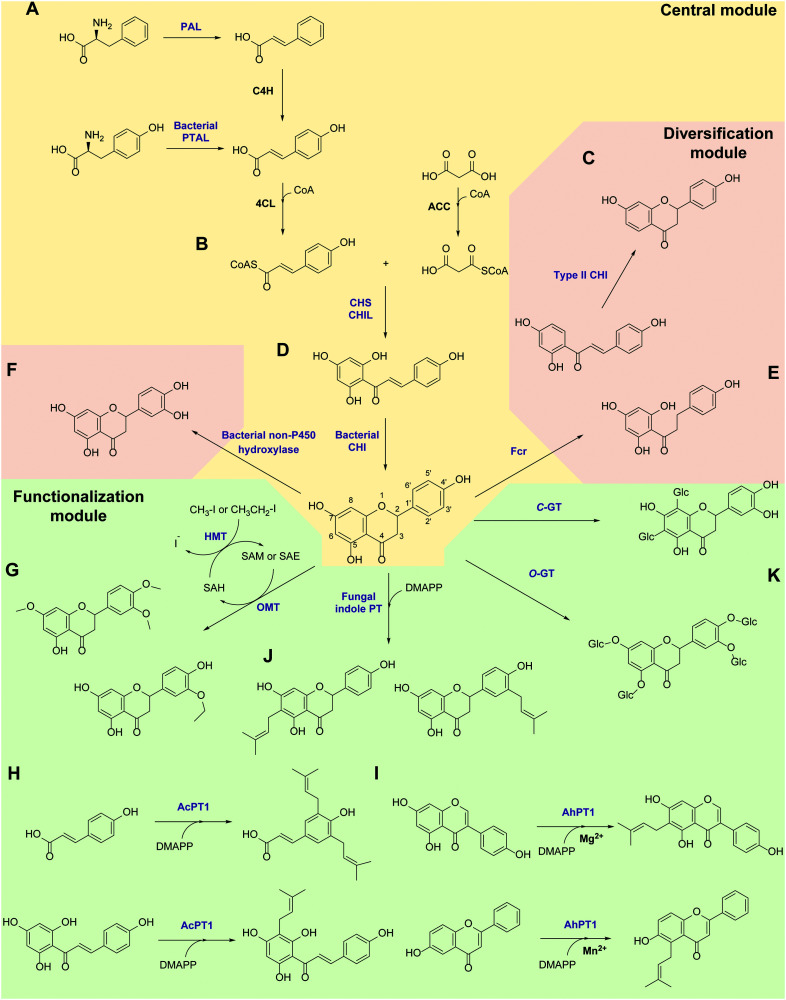
Biocatalysis has undergone revolutionary progress in the past century. Benefited by the integration of multidisciplinary technologies, natural enzymatic reactions are constantly being explored. Protein engineering gives birth to robust biocatalysts that are widely used in industrial production. These research achievements have gradually constructed a network containing natural enzymatic synthesis pathways and artificially designed enzymatic cascades. Nowadays, the development of artificial intelligence, automation, and ultra-high-throughput technology provides infinite possibilities for the discovery of novel enzymes, enzymatic mechanisms and enzymatic cascades, and gradually complements the lack of remaining key steps in the pathway design of enzymatic total synthesis. Therefore, the research of biocatalysis is gradually moving towards the era of novel technology integration, intelligent manufacturing and enzymatic total synthesis.
Conflict of interest statement
The authors declare no conflict of interests.
Figures
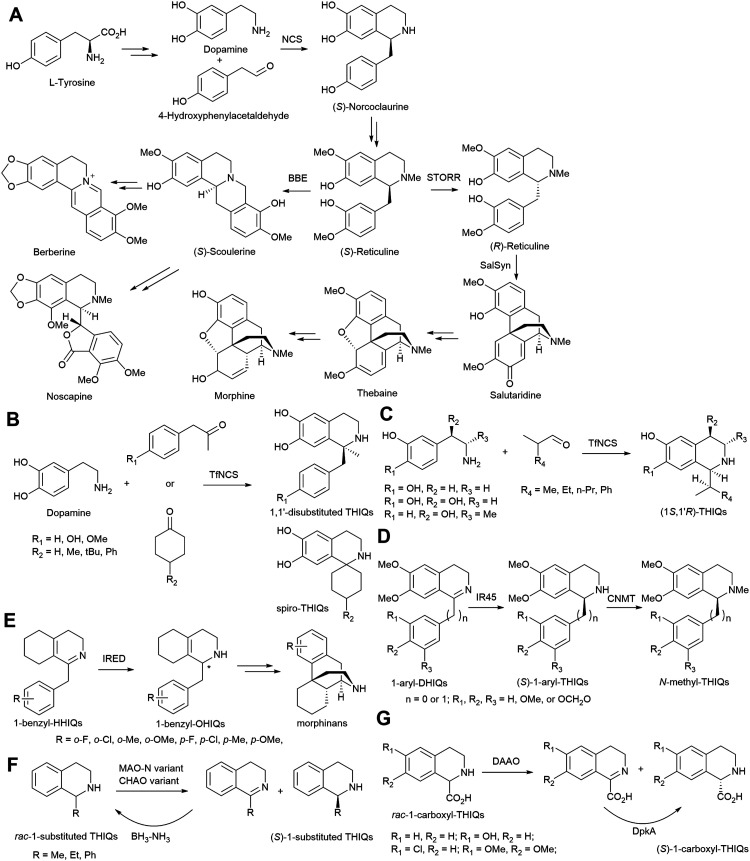
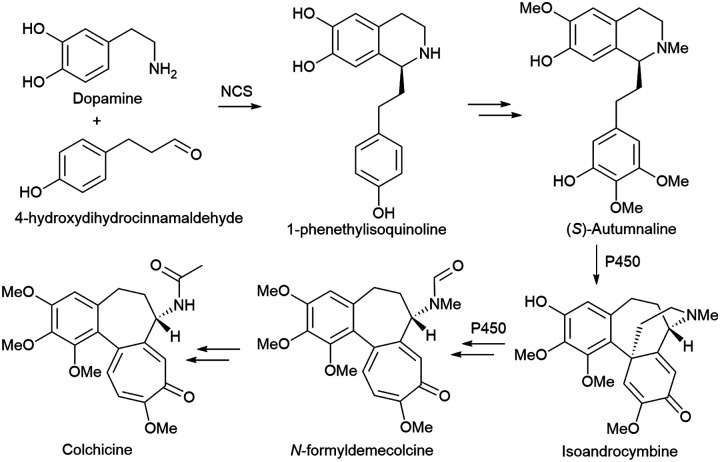
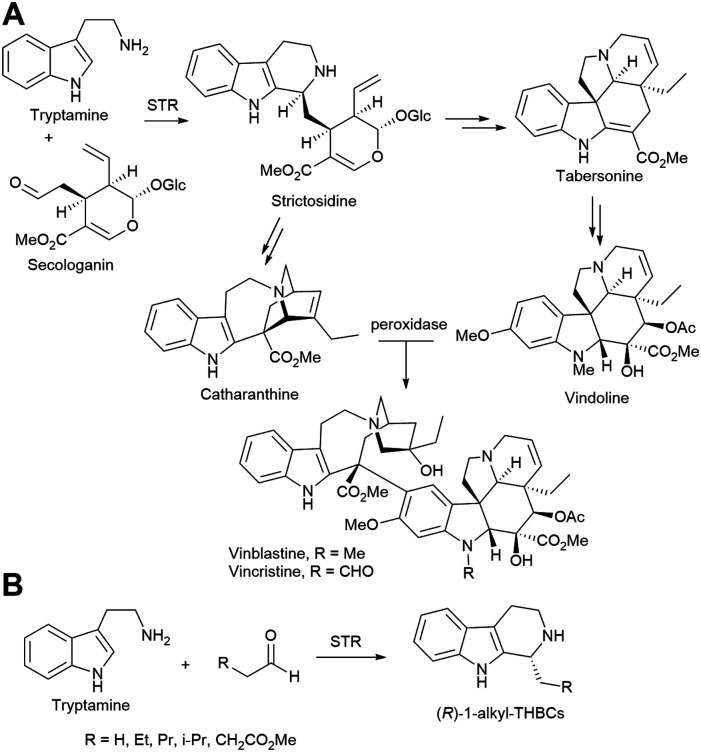
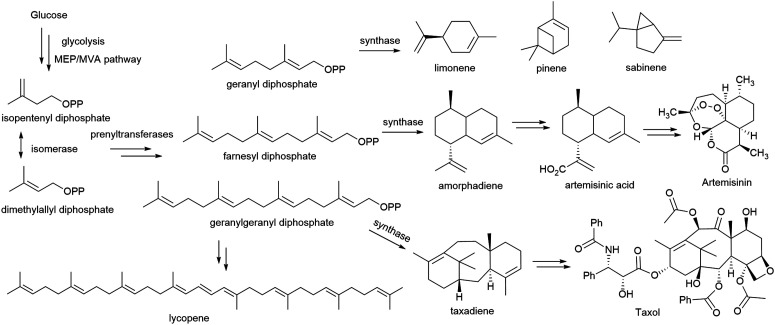
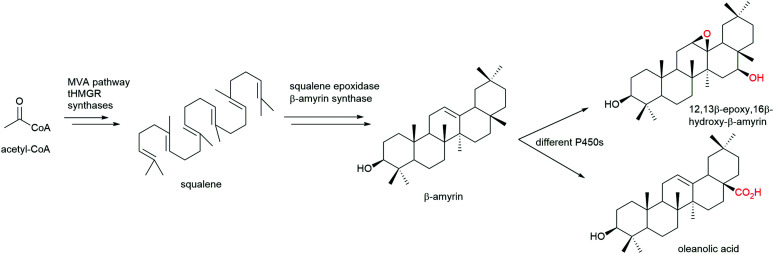
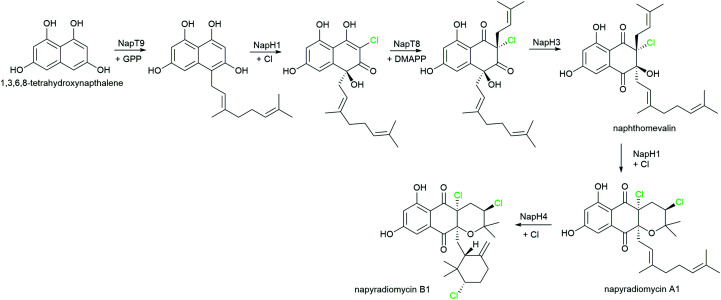
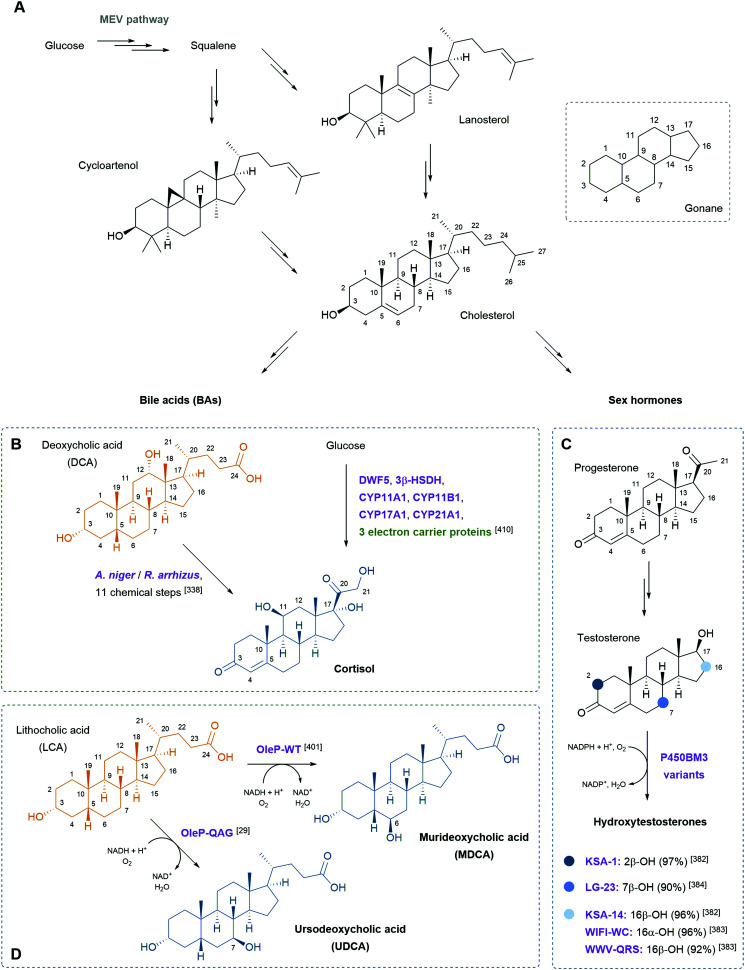
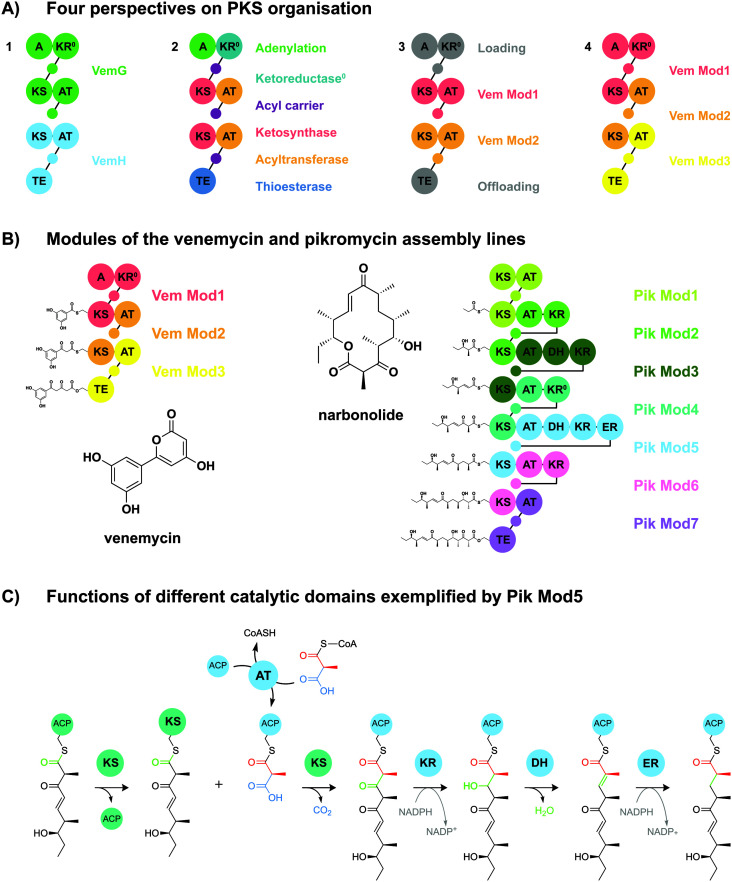
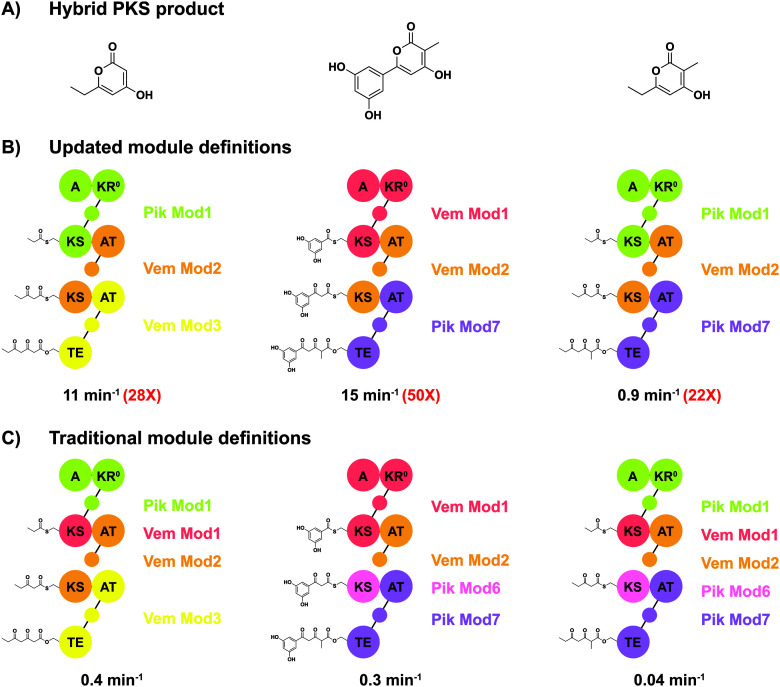
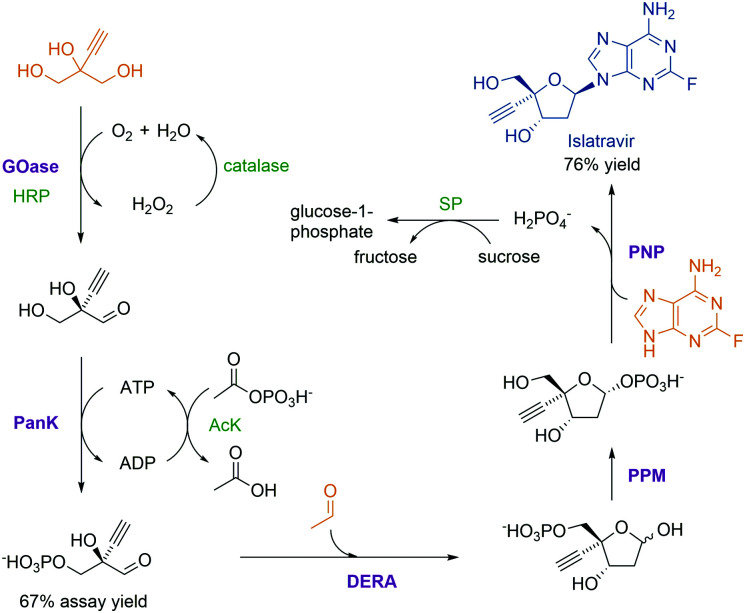
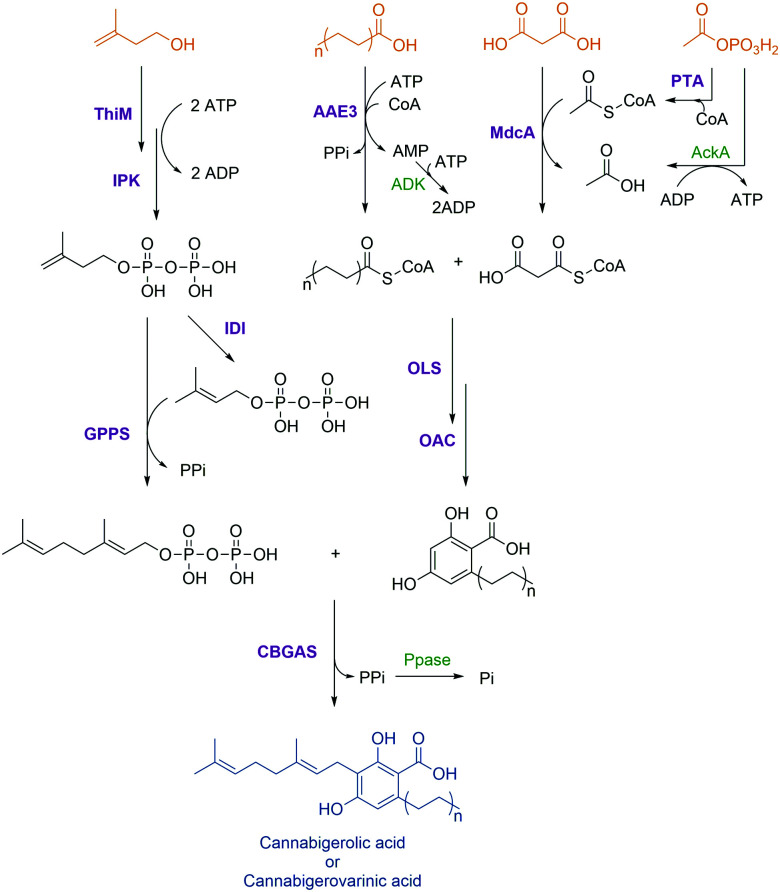

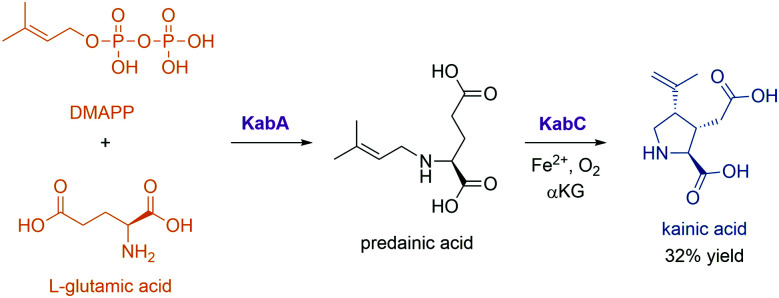
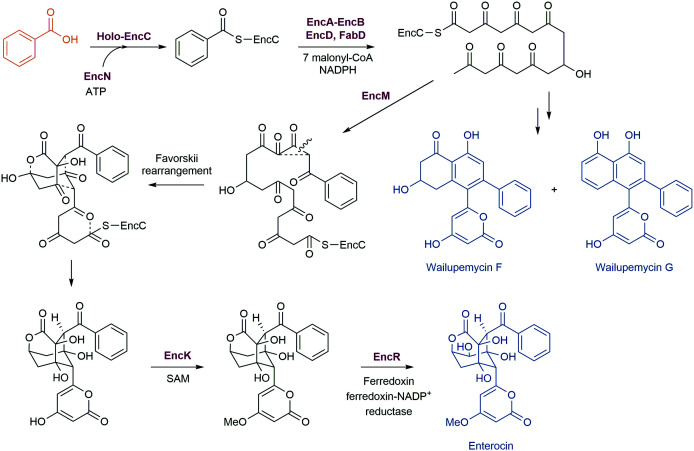
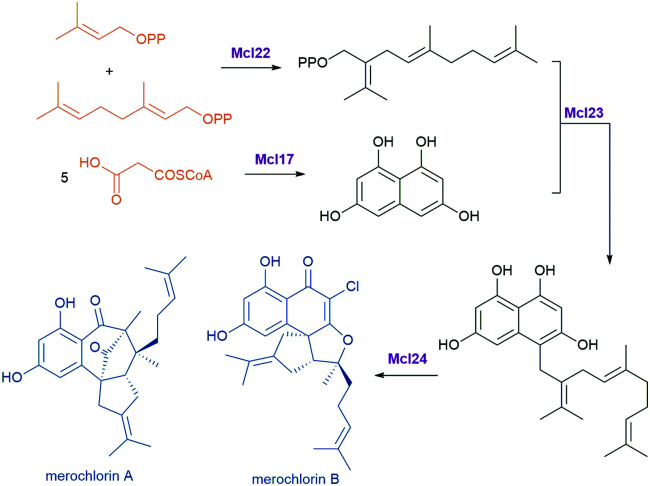
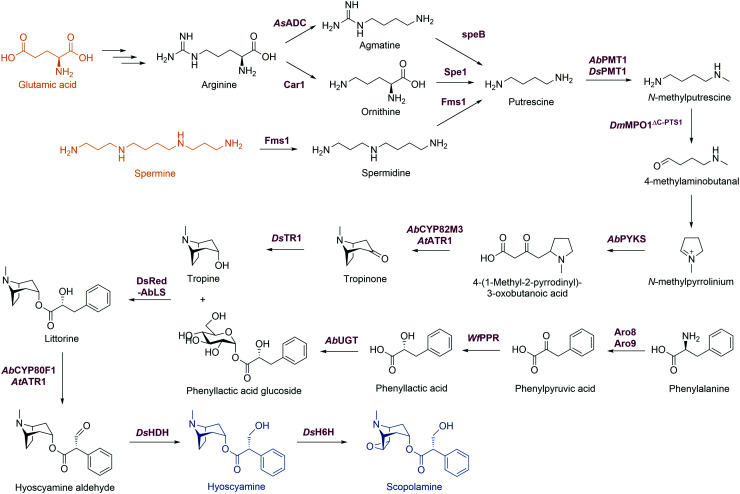

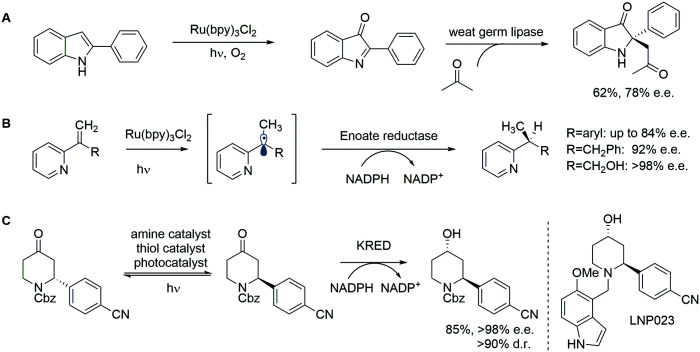






References
-
- Rosenthaler L. Biochem. Z. 1908;14:238–253.
-
- Moore G. E. Electronics. 1965;38:8.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous