

Comparison of six statistical methods for interrupted time series studies: empirical evaluation of 190 published series
- PMID: 34174809
- PMCID: PMC8235830
- DOI: 10.1186/s12874-021-01306-w
Comparison of six statistical methods for interrupted time series studies: empirical evaluation of 190 published series
Abstract
Background: The Interrupted Time Series (ITS) is a quasi-experimental design commonly used in public health to evaluate the impact of interventions or exposures. Multiple statistical methods are available to analyse data from ITS studies, but no empirical investigation has examined how the different methods compare when applied to real-world datasets.
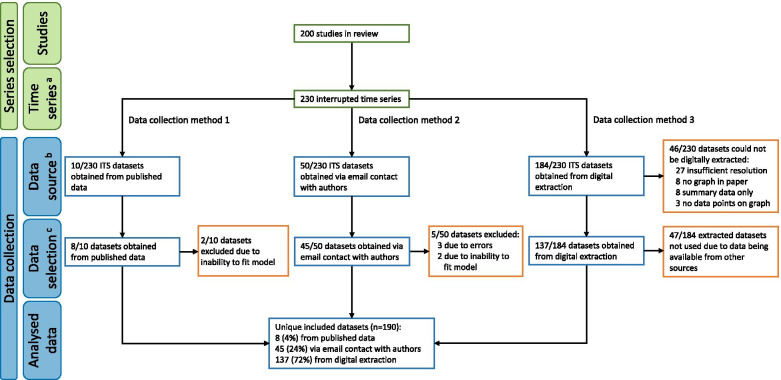
Methods: A random sample of 200 ITS studies identified in a previous methods review were included. Time series data from each of these studies was sought. Each dataset was re-analysed using six statistical methods. Point and confidence interval estimates for level and slope changes, standard errors, p-values and estimates of autocorrelation were compared between methods.
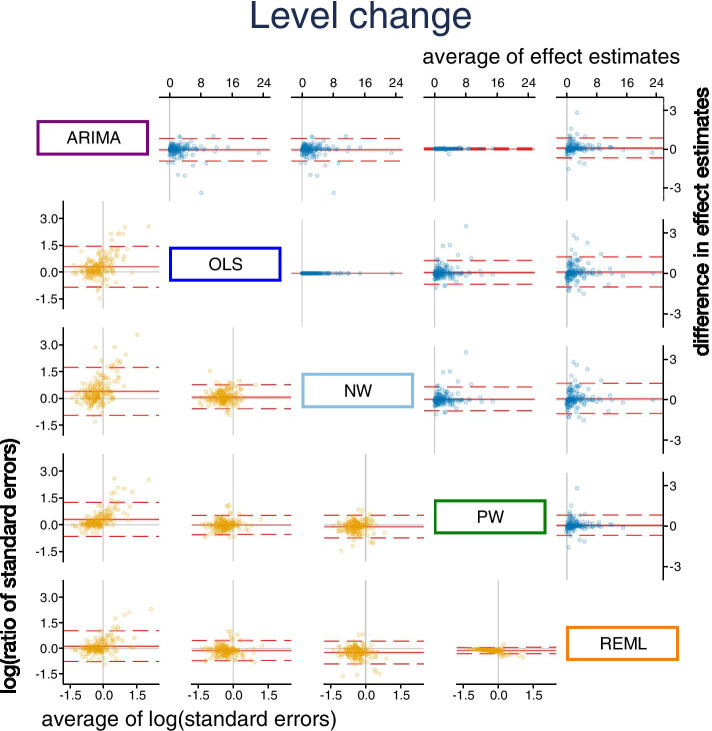
Results: From the 200 ITS studies, including 230 time series, 190 datasets were obtained. We found that the choice of statistical method can importantly affect the level and slope change point estimates, their standard errors, width of confidence intervals and p-values. Statistical significance (categorised at the 5% level) often differed across the pairwise comparisons of methods, ranging from 4 to 25% disagreement. Estimates of autocorrelation differed depending on the method used and the length of the series.
Conclusions: The choice of statistical method in ITS studies can lead to substantially different conclusions about the impact of the interruption. Pre-specification of the statistical method is encouraged, and naive conclusions based on statistical significance should be avoided.
Keywords: Autocorrelation; Empirical study; Interrupted Time Series; Public Health; Segmented Regression; Statistical Methods.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures








Similar articles
-
Evaluation of statistical methods used in the analysis of interrupted time series studies: a simulation study.BMC Med Res Methodol. 2021 Aug 28;21(1):181. doi: 10.1186/s12874-021-01364-0. BMC Med Res Methodol. 2021. PMID: 34454418 Free PMC article.
-
Evaluation of statistical methods used to meta-analyse results from interrupted time series studies: A simulation study.Res Synth Methods. 2023 Nov;14(6):882-902. doi: 10.1002/jrsm.1669. Epub 2023 Sep 20. Res Synth Methods. 2023. PMID: 37731166 Free PMC article.
-
Design characteristics and statistical methods used in interrupted time series studies evaluating public health interventions: a review.J Clin Epidemiol. 2020 Jun;122:1-11. doi: 10.1016/j.jclinepi.2020.02.006. Epub 2020 Feb 25. J Clin Epidemiol. 2020. PMID: 32109503 Review.
-
Design characteristics and statistical methods used in interrupted time series studies evaluating public health interventions: protocol for a review.BMJ Open. 2019 Jan 28;9(1):e024096. doi: 10.1136/bmjopen-2018-024096. BMJ Open. 2019. PMID: 30696676 Free PMC article.
-
Payment methods for healthcare providers working in outpatient healthcare settings.Cochrane Database Syst Rev. 2021 Jan 20;1(1):CD011865. doi: 10.1002/14651858.CD011865.pub2. Cochrane Database Syst Rev. 2021. PMID: 33469932 Free PMC article.
Cited by
-
Differences in Cesarean Rates for Nulliparous, Term, Singleton, Vertex Births Among Racial and Ethnic Groups and States Before and After Stay-at-Home Orders During the COVID-19 Pandemic, United States, 2017-2021.Public Health Rep. 2024 Sep-Oct;139(5):615-625. doi: 10.1177/00333549241236629. Epub 2024 Mar 19. Public Health Rep. 2024. PMID: 38504483 Free PMC article.
-
Incidence of mental health diagnoses during the COVID-19 pandemic: a multinational network study.Epidemiol Psychiatr Sci. 2024 Mar 4;33:e9. doi: 10.1017/S2045796024000088. Epidemiol Psychiatr Sci. 2024. PMID: 38433286 Free PMC article.
-
Global trends in antibiotic consumption during 2016-2023 and future projections through 2030.Proc Natl Acad Sci U S A. 2024 Dec 3;121(49):e2411919121. doi: 10.1073/pnas.2411919121. Epub 2024 Nov 18. Proc Natl Acad Sci U S A. 2024. PMID: 39556760 Free PMC article.
-
The Impact of the COVID-19 Pandemic on Suicide Attempts in Kerman Province: An Interrupted Time Series Analysis.Iran J Public Health. 2025 Jan;54(1):195-204. doi: 10.18502/ijph.v54i1.17591. Iran J Public Health. 2025. PMID: 39902363 Free PMC article.
-
The REPRISE project: protocol for an evaluation of REProducibility and Replicability In Syntheses of Evidence.Syst Rev. 2021 Apr 16;10(1):112. doi: 10.1186/s13643-021-01670-0. Syst Rev. 2021. PMID: 33863381 Free PMC article.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
