

A Guide for Sparse PCA: Model Comparison and Applications
- PMID: 34185214
- PMCID: PMC8636462
- DOI: 10.1007/s11336-021-09773-2
A Guide for Sparse PCA: Model Comparison and Applications
Abstract
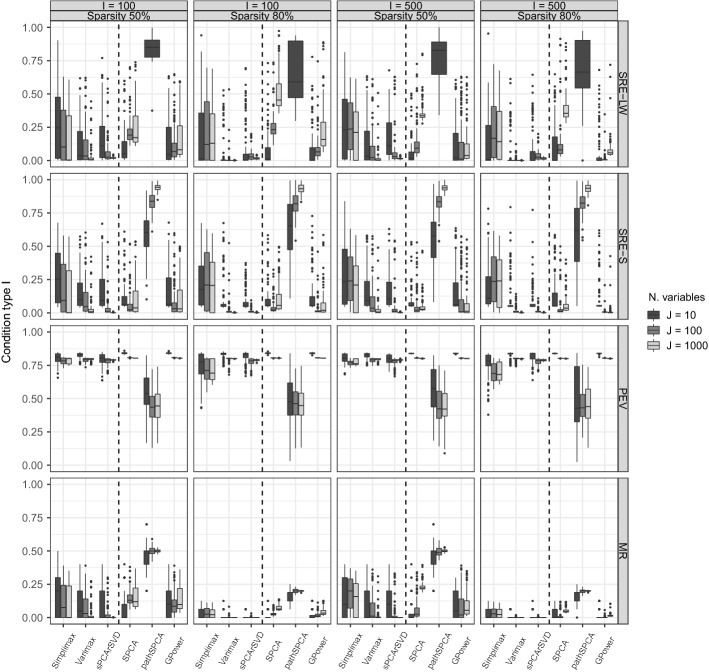
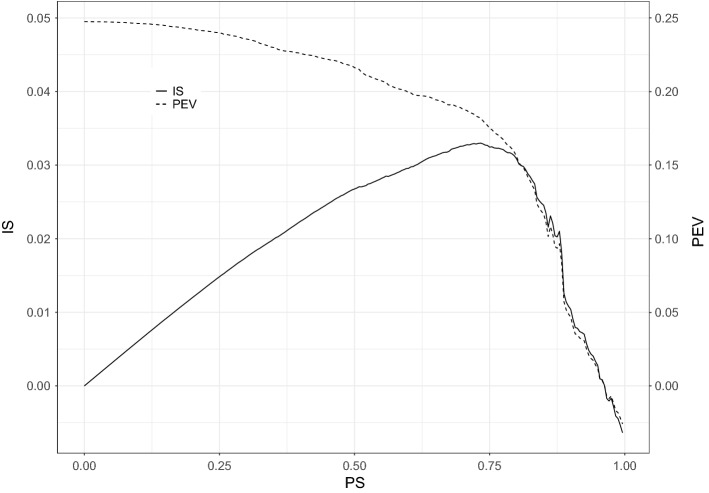
PCA is a popular tool for exploring and summarizing multivariate data, especially those consisting of many variables. PCA, however, is often not simple to interpret, as the components are a linear combination of the variables. To address this issue, numerous methods have been proposed to sparsify the nonzero coefficients in the components, including rotation-thresholding methods and, more recently, PCA methods subject to sparsity inducing penalties or constraints. Here, we offer guidelines on how to choose among the different sparse PCA methods. Current literature misses clear guidance on the properties and performance of the different sparse PCA methods, often relying on the misconception that the equivalence of the formulations for ordinary PCA also holds for sparse PCA. To guide potential users of sparse PCA methods, we first discuss several popular sparse PCA methods in terms of where the sparseness is imposed on the loadings or on the weights, assumed model, and optimization criterion used to impose sparseness. Second, using an extensive simulation study, we assess each of these methods by means of performance measures such as squared relative error, misidentification rate, and percentage of explained variance for several data generating models and conditions for the population model. Finally, two examples using empirical data are considered.
Keywords: dimension reduction; exploratory data analysis; high dimension-low sample size; regularization; sparse principal components analysis.
© 2021. The Author(s).
Figures







References
-
- Adachi K, Trendafilov NT. Sparse principal component analysis subject to prespecified cardinality of loadings. Computational Statistics. 2016;314(4):1403–1427. doi: 10.1007/s00180-015-0608-4. - DOI
-
- Baik J, Silverstein JW. Eigenvalues of large sample covariance matrices of spiked population models. Journal of Multivariate Analysis. 2006;97(6):1382–1408. doi: 10.1016/j.jmva.2005.08.003. - DOI
-
- Beck A, Teboulle M. A fast iterative Shrinkage–Thresholding algorithm for linear inverse problems. SIAM Journal of Imaging Sciences. 2009;2(1):183–202. doi: 10.1137/080716542. - DOI
-
- Bertsimas, D., King, A., & Mazumder, R. (2016). Best subset selection via a modern optimization lens (Vol. 44) (No. 2). 10.1214/15-AOS1388
-
- Cadima J, Jolliffe IT. Loadings and correlations in the interpretation of principal components. Journal of Applied Statistics. 1995;22(2):203–214. doi: 10.1080/757584614. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
