

Pan-genomic matching statistics for targeted nanopore sequencing
- PMID: 34195571
- PMCID: PMC8237286
- DOI: 10.1016/j.isci.2021.102696
Pan-genomic matching statistics for targeted nanopore sequencing
Abstract
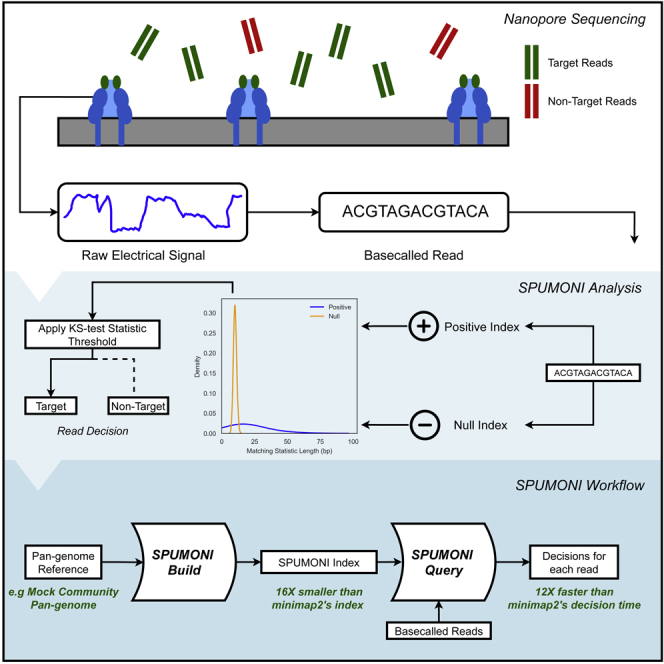
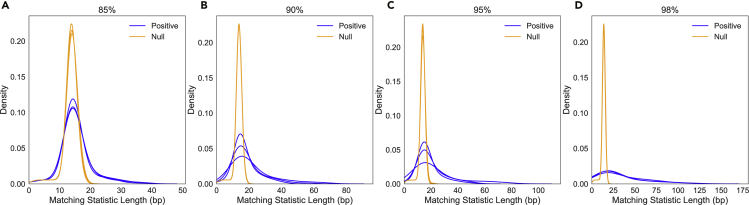
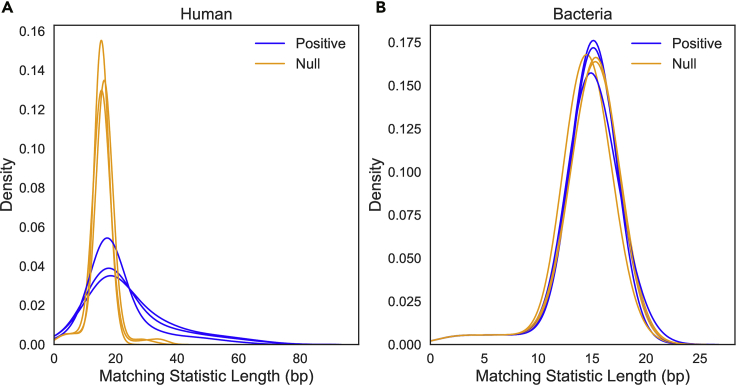
Nanopore sequencing is an increasingly powerful tool for genomics. Recently, computational advances have allowed nanopores to sequence in a targeted fashion; as the sequencer emits data, software can analyze the data in real time and signal the sequencer to eject "nontarget" DNA molecules. We present a novel method called SPUMONI, which enables rapid and accurate targeted sequencing using efficient pan-genome indexes. SPUMONI uses a compressed index to rapidly generate exact or approximate matching statistics in a streaming fashion. When used to target a specific strain in a mock community, SPUMONI has similar accuracy as minimap2 when both are run against an index containing many strains per species. However SPUMONI is 12 times faster than minimap2. SPUMONI's index and peak memory footprint are also 16 to 4 times smaller than those of minimap2, respectively. This could enable accurate targeted sequencing even when the targeted strains have not necessarily been sequenced or assembled previously.
Keywords: Biocomputational Method; Bioinformatics; Biotechnology; Genomics.
© 2021 The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Bannai H., Gagie T., Tomohiro I. Refining the r-index. Theor. Comput. Sci. 2020;812:96–108. doi: 10.1016/j.tcs.2019.08.005. - DOI
-
- Burrows M., Wheeler D. A block-sorting lossless data compression algorithm. Technical Report 124. 1994;Digital SRC Research Report
-
- Gagie T., Tomohiro I., Manzini G., Navarro G., Sakamoto H., Takabatake Y. Rpair: Rescaling RePair with Rsync. Proc. SPIRE. 2019 doi: 10.1007/978-3-030-32686-9_3. - DOI
-
- Gagie T., Navarro G., Prezza N. Fully functional suffix trees and optimal text searching in BWT-runs bounded space. J. ACM. 2020;67:2:1–2:54. doi: 10.1145/3375890. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
