

Transfer Learning Based Semantic Segmentation for 3D Object Detection from Point Cloud
- PMID: 34201390
- PMCID: PMC8230345
- DOI: 10.3390/s21123964
Transfer Learning Based Semantic Segmentation for 3D Object Detection from Point Cloud
Abstract
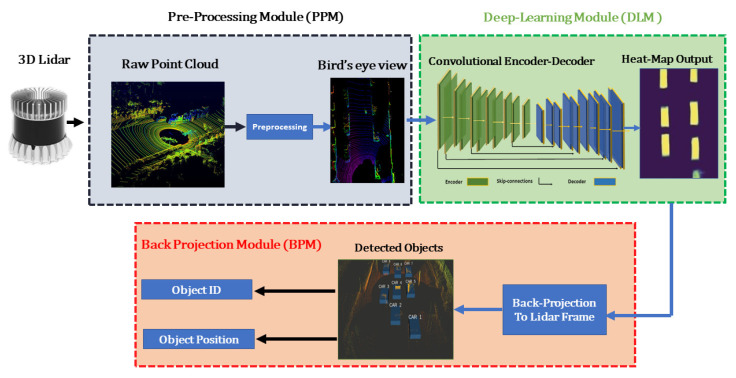
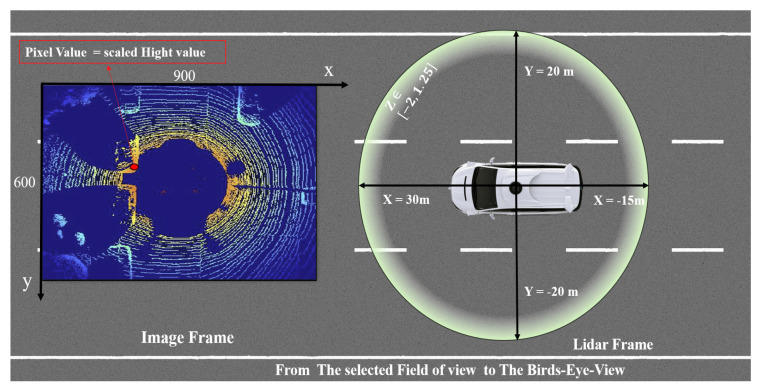
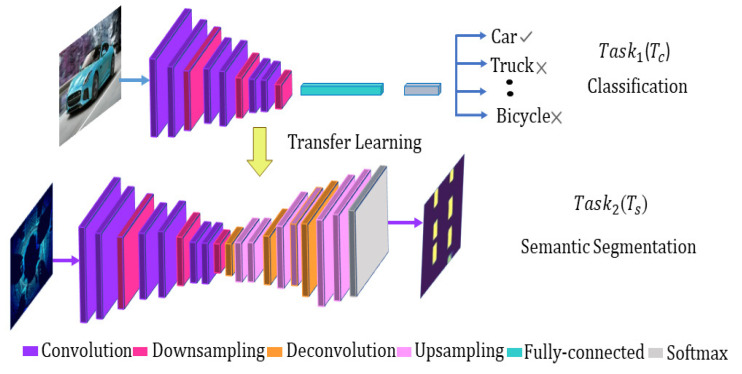
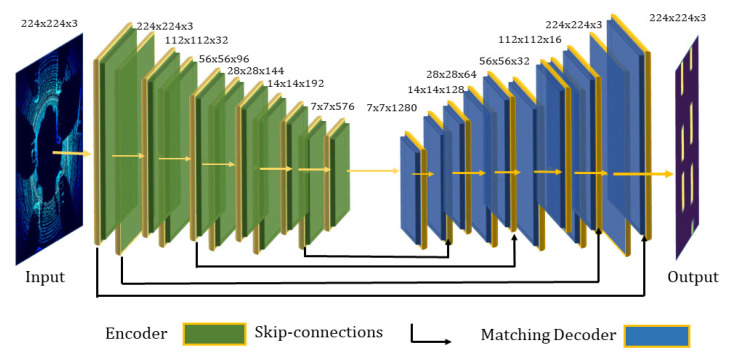
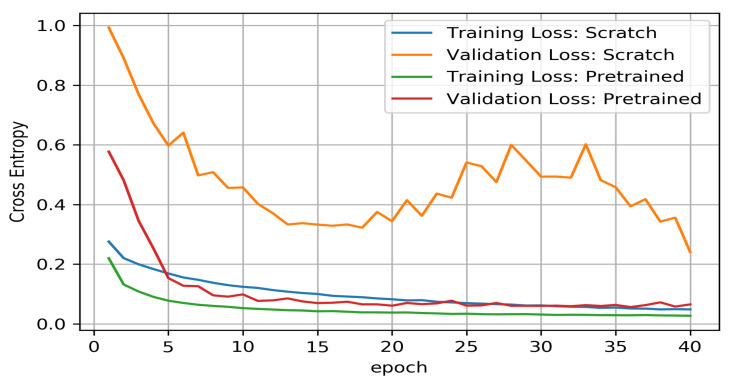
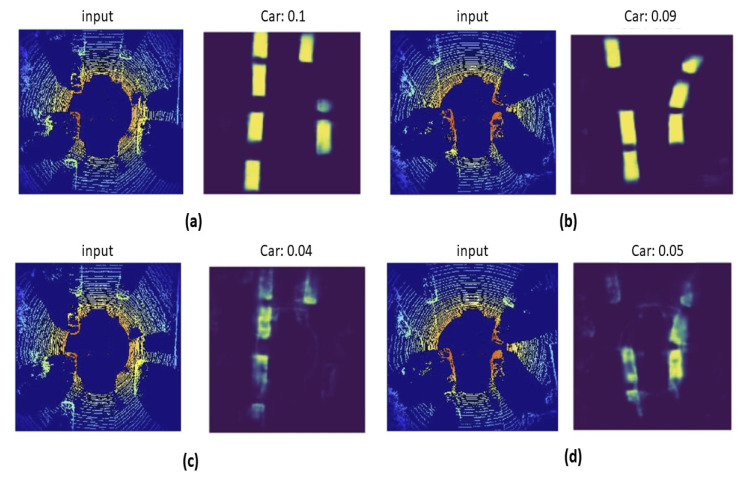
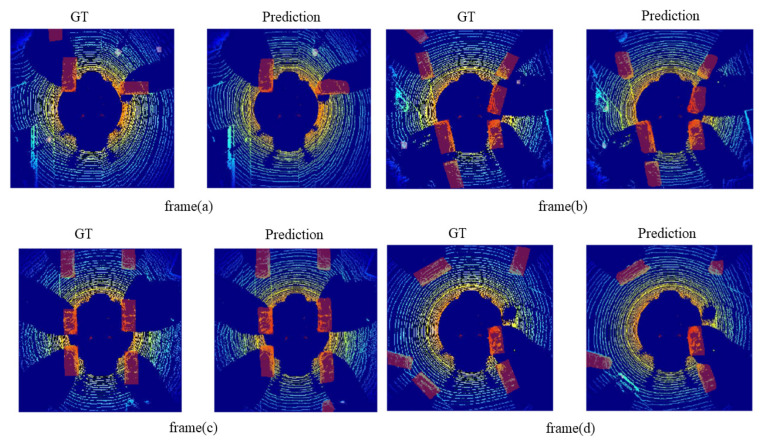
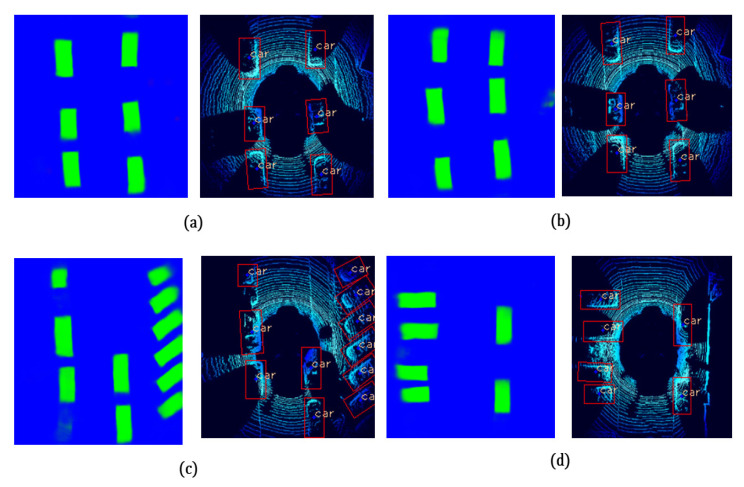
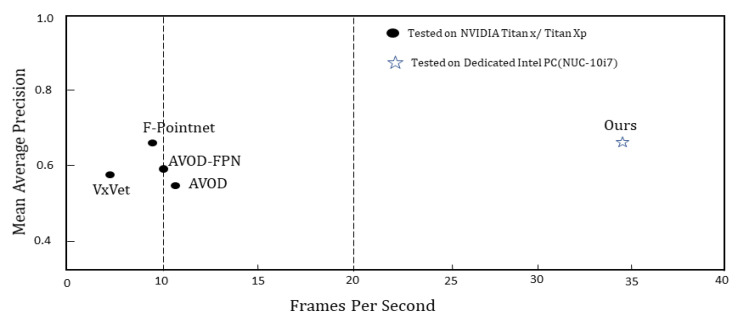
Three-dimensional object detection utilizing LiDAR point cloud data is an indispensable part of autonomous driving perception systems. Point cloud-based 3D object detection has been a better replacement for higher accuracy than cameras during nighttime. However, most LiDAR-based 3D object methods work in a supervised manner, which means their state-of-the-art performance relies heavily on a large-scale and well-labeled dataset, while these annotated datasets could be expensive to obtain and only accessible in the limited scenario. Transfer learning is a promising approach to reduce the large-scale training datasets requirement, but existing transfer learning object detectors are primarily for 2D object detection rather than 3D. In this work, we utilize the 3D point cloud data more effectively by representing the birds-eye-view (BEV) scene and propose a transfer learning based point cloud semantic segmentation for 3D object detection. The proposed model minimizes the need for large-scale training datasets and consequently reduces the training time. First, a preprocessing stage filters the raw point cloud data to a BEV map within a specific field of view. Second, the transfer learning stage uses knowledge from the previously learned classification task (with more data for training) and generalizes the semantic segmentation-based 2D object detection task. Finally, 2D detection results from the BEV image have been back-projected into 3D in the postprocessing stage. We verify results on two datasets: the KITTI 3D object detection dataset and the Ouster LiDAR-64 dataset, thus demonstrating that the proposed method is highly competitive in terms of mean average precision (mAP up to 70%) while still running at more than 30 frames per second (FPS).
Keywords: 3D object detection; point cloud processing; semantic segmentation; transfer learning.
Conflict of interest statement
The authors declare no conflict of interest.
Figures


Similar articles
-
Up-Sampling Method for Low-Resolution LiDAR Point Cloud to Enhance 3D Object Detection in an Autonomous Driving Environment.Sensors (Basel). 2022 Dec 28;23(1):322. doi: 10.3390/s23010322. Sensors (Basel). 2022. PMID: 36616921 Free PMC article.
-
EPGNet: Enhanced Point Cloud Generation for 3D Object Detection.Sensors (Basel). 2020 Dec 4;20(23):6927. doi: 10.3390/s20236927. Sensors (Basel). 2020. PMID: 33291527 Free PMC article.
-
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR-Based Perception.IEEE Trans Pattern Anal Mach Intell. 2022 Oct;44(10):6807-6822. doi: 10.1109/TPAMI.2021.3098789. Epub 2022 Sep 14. IEEE Trans Pattern Anal Mach Intell. 2022. PMID: 34310286
-
A Survey on Deep-Learning-Based LiDAR 3D Object Detection for Autonomous Driving.Sensors (Basel). 2022 Dec 7;22(24):9577. doi: 10.3390/s22249577. Sensors (Basel). 2022. PMID: 36559950 Free PMC article. Review.
-
Deep Learning on Point Clouds and Its Application: A Survey.Sensors (Basel). 2019 Sep 26;19(19):4188. doi: 10.3390/s19194188. Sensors (Basel). 2019. PMID: 31561639 Free PMC article. Review.
Cited by
-
HP3D-V2V: High-Precision 3D Object Detection Vehicle-to-Vehicle Cooperative Perception Algorithm.Sensors (Basel). 2024 Mar 28;24(7):2170. doi: 10.3390/s24072170. Sensors (Basel). 2024. PMID: 38610381 Free PMC article.
-
Obstacle Detection Using a Facet-Based Representation from 3-D LiDAR Measurements.Sensors (Basel). 2021 Oct 15;21(20):6861. doi: 10.3390/s21206861. Sensors (Basel). 2021. PMID: 34696073 Free PMC article.
-
General-Purpose Deep Learning Detection and Segmentation Models for Images from a Lidar-Based Camera Sensor.Sensors (Basel). 2023 Mar 8;23(6):2936. doi: 10.3390/s23062936. Sensors (Basel). 2023. PMID: 36991648 Free PMC article.
-
Efficient Detection and Tracking of Human Using 3D LiDAR Sensor.Sensors (Basel). 2023 May 12;23(10):4720. doi: 10.3390/s23104720. Sensors (Basel). 2023. PMID: 37430633 Free PMC article.
-
Cascaded Deep Learning Neural Network for Automated Liver Steatosis Diagnosis Using Ultrasound Images.Sensors (Basel). 2021 Aug 5;21(16):5304. doi: 10.3390/s21165304. Sensors (Basel). 2021. PMID: 34450746 Free PMC article.
References
-
- Himmelsbach M., Mueller A., Lüttel T., Wünsche H.J. LIDAR-based 3D object perception; Proceedings of the 1st International Workshop on Cognition for Technical Systems; Munich, Germany. 6–8 October 2008;
-
- Jung J., Bae S.H. Real-time road lane detection in urban areas using LiDAR data. Electronics. 2018;7:276. doi: 10.3390/electronics7110276. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
