

Nanopore sequencing of single-cell transcriptomes with scCOLOR-seq
- PMID: 34211161
- PMCID: PMC8668430
- DOI: 10.1038/s41587-021-00965-w
Nanopore sequencing of single-cell transcriptomes with scCOLOR-seq
Abstract
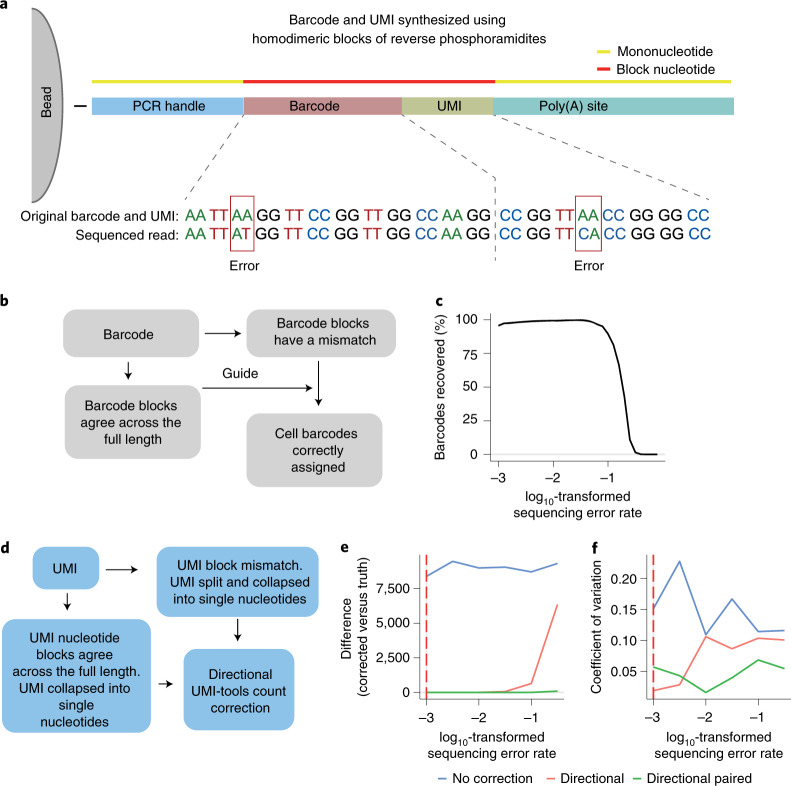
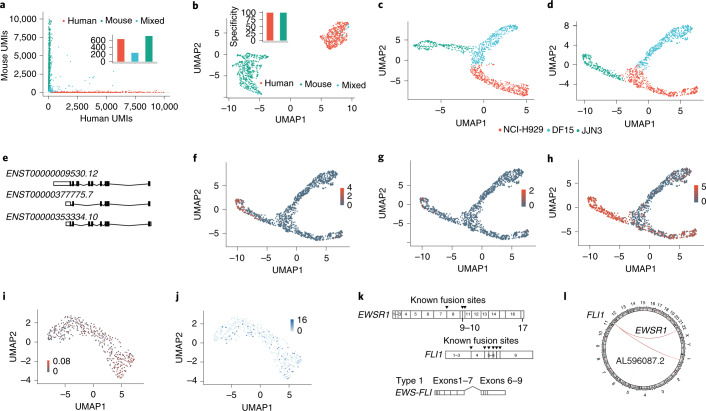
Here we describe single-cell corrected long-read sequencing (scCOLOR-seq), which enables error correction of barcode and unique molecular identifier oligonucleotide sequences and permits standalone cDNA nanopore sequencing of single cells. Barcodes and unique molecular identifiers are synthesized using dimeric nucleotide building blocks that allow error detection. We illustrate the use of the method for evaluating barcode assignment accuracy, differential isoform usage in myeloma cell lines, and fusion transcript detection in a sarcoma cell line.
© 2021. The Author(s).
Conflict of interest statement
A.T. is a full-time employee and shareholder of Bristol Myers Squibb and visiting professor, Weatherall Institute of Molecular Medicine, University of Oxford. M.P., U.O. and A.P.C. are inventors on patents filed by Oxford University Innovations for single-cell technologies and are founders of Caeruleus Genomics. T.B. Jr. is a director and shareholder of ATDBio. T.B. Sr. is a director of ATDBio. The other authors declare no competing interests.
Figures
References
-
- Gupta, I. et al. Single-cell isoform RNA sequencing characterizes isoforms in thousands of cerebellar cells. Nat. Biotechnol.36, 197–1202 (2018). - PubMed
-
- Zheng, Y.-F. et al. HIT-scISOseq: high-throughput and high-accuracy single-cell full-length isoform sequencing for corneal epithelium. Preprint at bioRxiv10.1101/2020.07.27.222349 (2020).
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
