

Reinforcement learning control of a biomechanical model of the upper extremity
- PMID: 34262081
- PMCID: PMC8280157
- DOI: 10.1038/s41598-021-93760-1
Reinforcement learning control of a biomechanical model of the upper extremity
Abstract
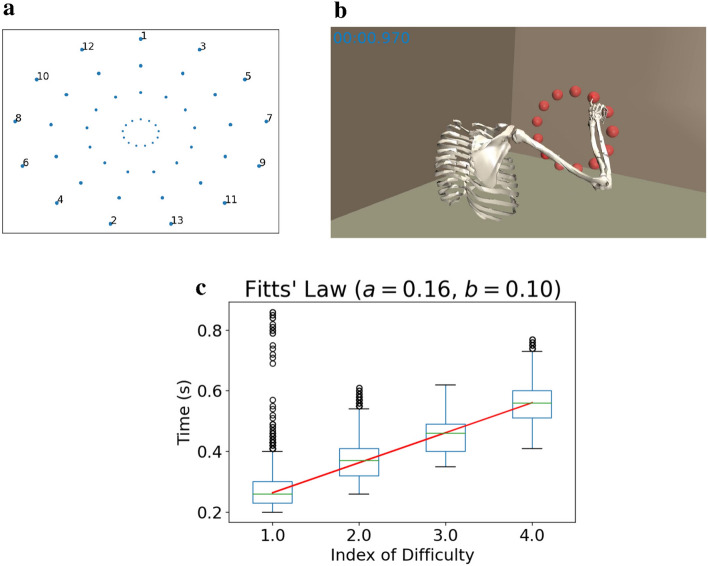
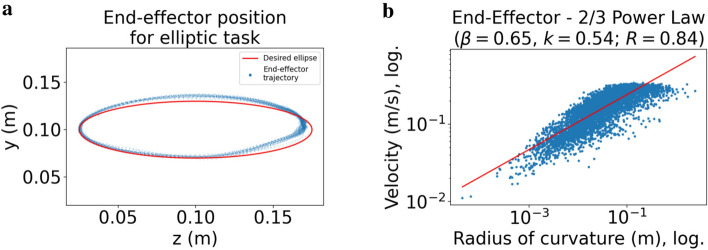
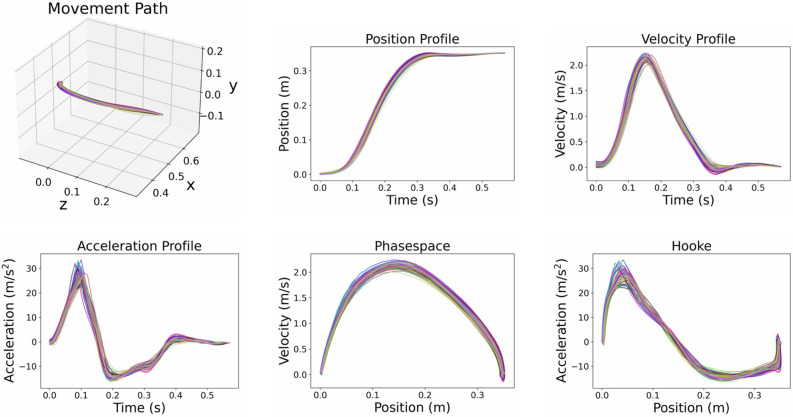
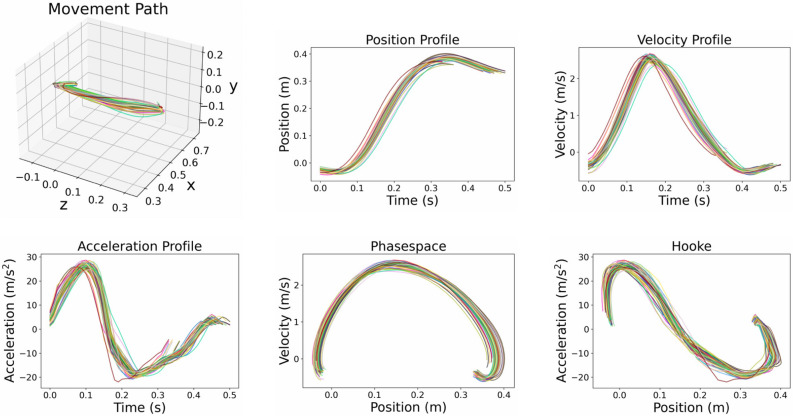
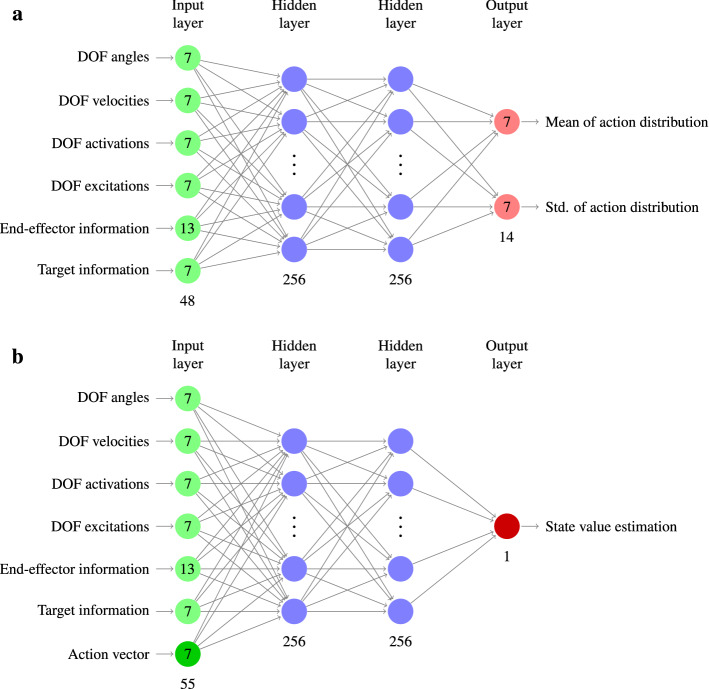
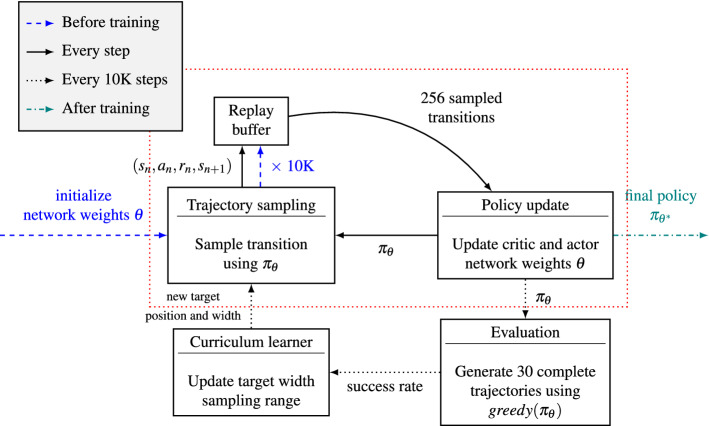
Among the infinite number of possible movements that can be produced, humans are commonly assumed to choose those that optimize criteria such as minimizing movement time, subject to certain movement constraints like signal-dependent and constant motor noise. While so far these assumptions have only been evaluated for simplified point-mass or planar models, we address the question of whether they can predict reaching movements in a full skeletal model of the human upper extremity. We learn a control policy using a motor babbling approach as implemented in reinforcement learning, using aimed movements of the tip of the right index finger towards randomly placed 3D targets of varying size. We use a state-of-the-art biomechanical model, which includes seven actuated degrees of freedom. To deal with the curse of dimensionality, we use a simplified second-order muscle model, acting at each degree of freedom instead of individual muscles. The results confirm that the assumptions of signal-dependent and constant motor noise, together with the objective of movement time minimization, are sufficient for a state-of-the-art skeletal model of the human upper extremity to reproduce complex phenomena of human movement, in particular Fitts' Law and the [Formula: see text] Power Law. This result supports the notion that control of the complex human biomechanical system can plausibly be determined by a set of simple assumptions and can easily be learned.
© 2021. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (A Bradford Book, 2018).
MeSH terms
LinkOut - more resources
Full Text Sources
