

Remembering the Past to See the Future
- PMID: 34270350
- PMCID: PMC9751846
- DOI: 10.1146/annurev-vision-093019-112249
Remembering the Past to See the Future
Abstract
In addition to the role that our visual system plays in determining what we are seeing right now, visual computations contribute in important ways to predicting what we will see next. While the role of memory in creating future predictions is often overlooked, efficient predictive computation requires the use of information about the past to estimate future events. In this article, we introduce a framework for understanding the relationship between memory and visual prediction and review the two classes of mechanisms that the visual system relies on to create future predictions. We also discuss the principles that define the mapping from predictive computations to predictive mechanisms and how downstream brain areas interpret the predictive signals computed by the visual system.
Keywords: memory; prediction; vision.
Figures
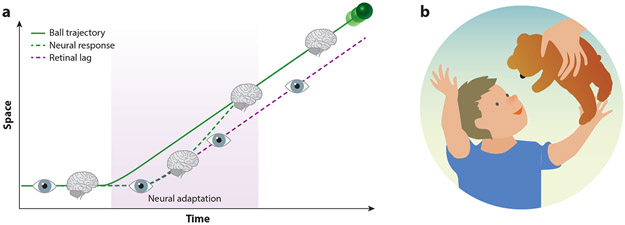
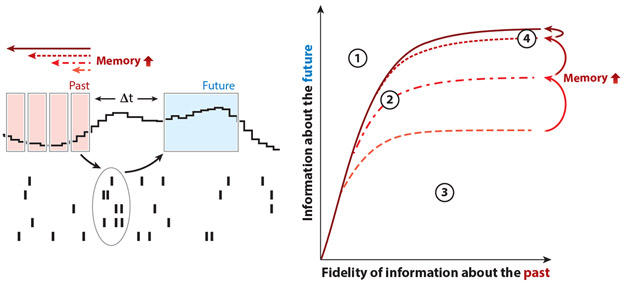
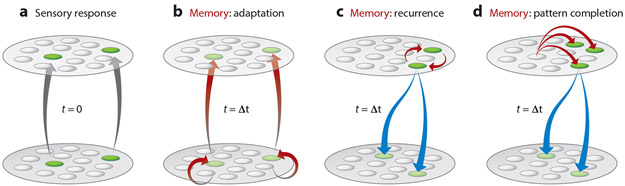
References
-
- Aly M, Turk-Browne NB. 2017. How hippocampal memory shapes, and is shaped by, attention. In The Hippocampus from Cells to Systems: Structure, Connectivity, and Functional Contributions to Memory and Flexible Cognition, ed. Hannula DE, Duff MC, pp. 369–403. Berlin: Springer
-
- Anstis S 2007. The flash-lag effect during illusory chopstick rotation. Perception 36:1043–48 - PubMed
-
- Bellemare MG, Srinivasan S, Ostrovski G, Schaul T, Saxton D, Munos R. 2016. Unifying count-based exploration and intrinsic motivation. In Advances in Neural Information Processing Systems 29 (NIPS 2016), ed. D Lee, Sugiyama M, Luxburg U, Guyon I, Garnett R, pp. 1471–79. N.p.: NeurIPS
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
