

Principles and Practice of Explainable Machine Learning
- PMID: 34278297
- PMCID: PMC8281957
- DOI: 10.3389/fdata.2021.688969
Principles and Practice of Explainable Machine Learning
Abstract
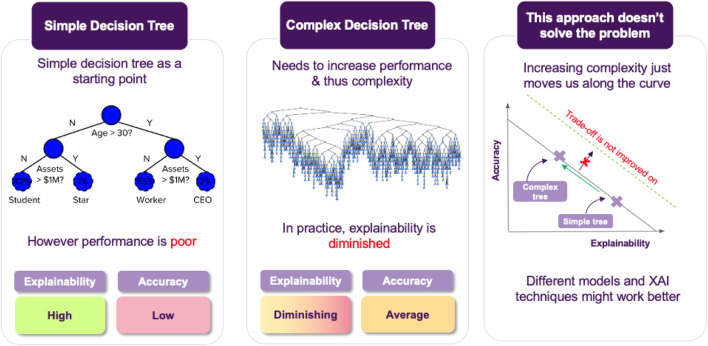
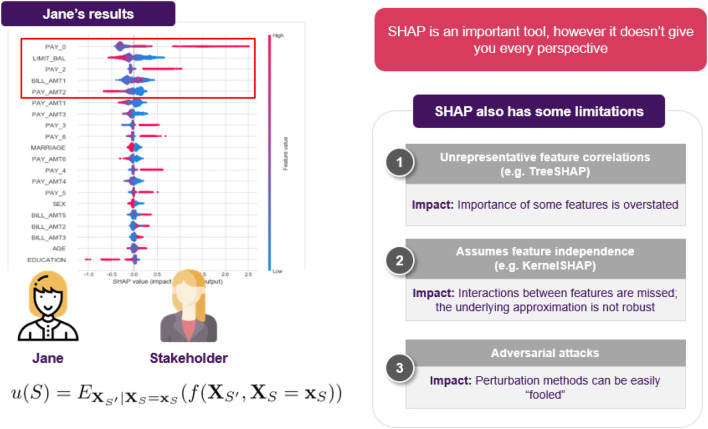
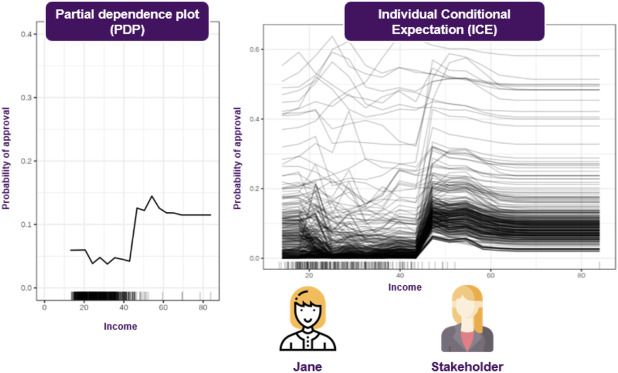
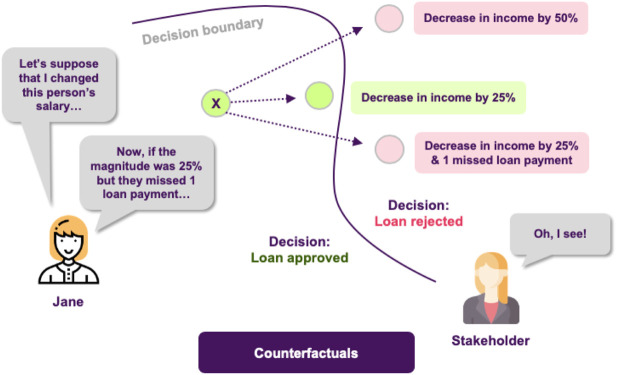
Artificial intelligence (AI) provides many opportunities to improve private and public life. Discovering patterns and structures in large troves of data in an automated manner is a core component of data science, and currently drives applications in diverse areas such as computational biology, law and finance. However, such a highly positive impact is coupled with a significant challenge: how do we understand the decisions suggested by these systems in order that we can trust them? In this report, we focus specifically on data-driven methods-machine learning (ML) and pattern recognition models in particular-so as to survey and distill the results and observations from the literature. The purpose of this report can be especially appreciated by noting that ML models are increasingly deployed in a wide range of businesses. However, with the increasing prevalence and complexity of methods, business stakeholders in the very least have a growing number of concerns about the drawbacks of models, data-specific biases, and so on. Analogously, data science practitioners are often not aware about approaches emerging from the academic literature or may struggle to appreciate the differences between different methods, so end up using industry standards such as SHAP. Here, we have undertaken a survey to help industry practitioners (but also data scientists more broadly) understand the field of explainable machine learning better and apply the right tools. Our latter sections build a narrative around a putative data scientist, and discuss how she might go about explaining her models by asking the right questions. From an organization viewpoint, after motivating the area broadly, we discuss the main developments, including the principles that allow us to study transparent models vs. opaque models, as well as model-specific or model-agnostic post-hoc explainability approaches. We also briefly reflect on deep learning models, and conclude with a discussion about future research directions.
Keywords: black-box models; explainable AI; machine learning; survey; transparent models.
Copyright © 2021 Belle and Papantonis.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
References
-
- Adebayo J., Kagal L. (2016). Iterative Orthogonal Feature Projection for Diagnosing Bias in Black-Box Models, FATML Workshop 2016, New York, NY.
-
- Arrieta A. B., Díaz-Rodríguez N., Del Ser J., Bennetot A., Tabik S., Barbado A., et al. (2019). Explainable Artificial Intelligence (Xai): Concepts, Taxonomies, Opportunities and Challenges toward Responsible Ai. arXiv preprint arXiv:1910.10045.
-
- Augasta M. G., Kathirvalavakumar T. (2012). Reverse Engineering the Neural Networks for Rule Extraction in Classification Problems. Heidelberg, Germany: Neural Processing Letters.
-
- Auret L., Aldrich C. (2012). Interpretation of Nonlinear Relationships between Process Variables by Use of Random Forests. Minerals Eng. 35, 27–42. 10.1016/j.mineng.2012.05.008 - DOI
Publication types
LinkOut - more resources
Full Text Sources