

doi: 10.1121/10.0005109.
Epub 2021 Jul 9.
Dark tone quality and vocal tract shaping in soprano song production: Insights from real-time MRI
Affiliations
- PMID: 34291230
- PMCID: PMC8273971
- DOI: 10.1121/10.0005109
Item in Clipboard
Dark tone quality and vocal tract shaping in soprano song production: Insights from real-time MRI
JASA Express Lett.
2021 Jul.
Abstract
Tone quality termed "dark" is an aesthetically important property of Western classical voice performance and has been associated with lowered formant frequencies, lowered larynx, and widened pharynx. The present study uses real-time magnetic resonance imaging with synchronous audio recordings to investigate dark tone quality in four professionally trained sopranos with enhanced ecological validity and a relatively complete view of the vocal tract. Findings differ from traditional accounts, indicating that labial narrowing may be the primary driver of dark tone quality across performers, while many other aspects of vocal tract shaping are shown to differ significantly in a performer-specific way.
© 2021 Author(s).
Figures
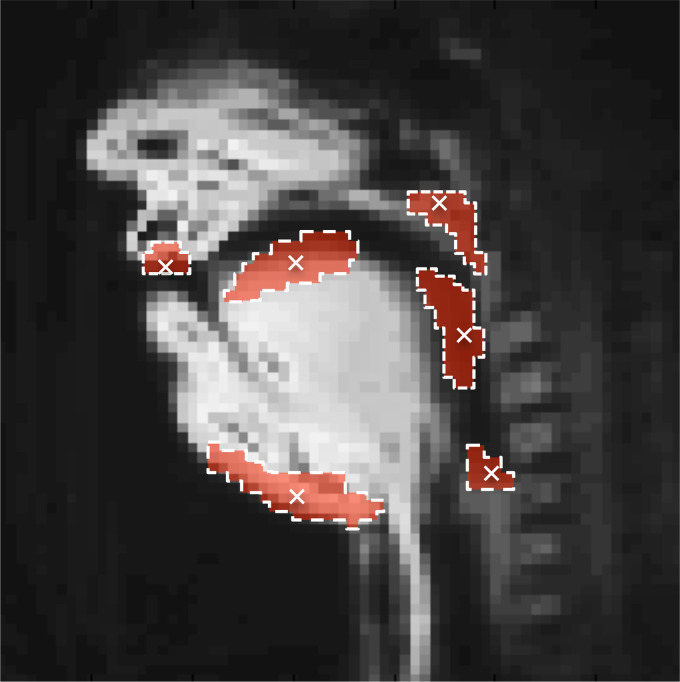
Subject M1 as represented by the mean of all images acquired during her dark (“covered”) aria performance. The six ROIs are superimposed in red, with the selected pixels used to form each region shown as a white “x.” ROIs correspond to labial, coronal, and pharyngeal regions, a region in the larynx immediately superior to the glottis, and regions capturing velum raising and jaw lowering.
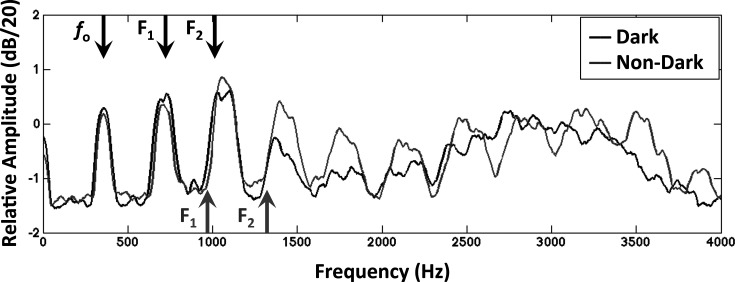
Frequency spectra estimated from audio recordings of subject H5 producing the vowel /a/ in the word “bella.” Spectra from both the dark and non-dark production are shown. Spectra were reconstructed by averaging across windows of a short-time Fourier transform with a 60 ms analysis window, 20% window overlap, Blackman–Harris weighting, and approximately 600 ms total duration. The harmonic structure can be seen, with the spacing between harmonics corresponding to the fundamental frequency (fo), which was ∼357 Hz in both productions. The first two formant frequencies for each production as computed by praat are also indicated. A broad shift in energy toward lower frequencies can be seen when comparing the dark production to the non-dark one, corresponding to the lower formant frequencies in the dark production.
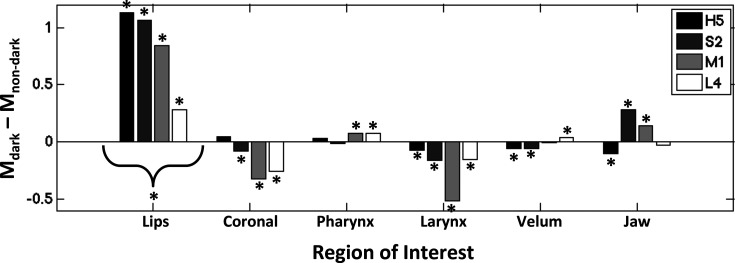
Mean ROI intensity (M) differences between the dark and non-dark performance conditions, expressed as a proportion of mean ROI intensity during the normal performance condition. Differences are shown for each ROI, representing narrowing of the labial, coronal, pharyngeal, and laryngeal regions of the vocal tract. Individual bars represent subject-specific differences. Negative difference values correspond to lower mean formant frequencies during the dark performance. Higher values for the lips, coronal, pharynx, and larynx regions indicate a more constricted vocal tract in that region. Higher values in the velum and jaw regions represent a more raised velum and jaw, respectively. Asterisks (*) indicate corresponding significant effects, described in Sec. 3, within subjects (below/below bars) and across subjects (curly brackets).
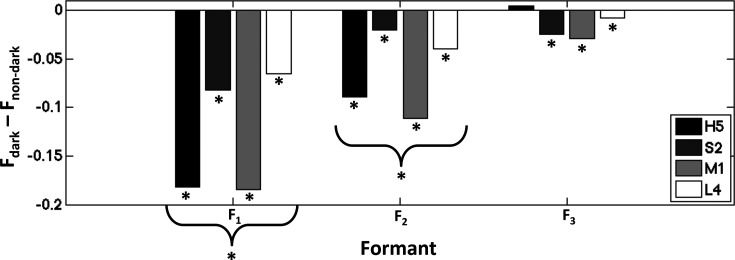
Mean formant frequency (F) differences between the dark and non-dark performance conditions, expressed as a proportion of mean formant frequencies during the normal performance condition. Differences are shown for each formant, 1–3, with bars representing subject-specific differences. Negative difference values correspond to lower mean formant frequencies during the dark performance. Asterisks (*) indicate corresponding significant effects, described in Sec. 3, within subjects (below bars) and across subjects (curly brackets).
Similar articles
-
Articulation and vocal tract acoustics at soprano subject's high fundamental frequencies.J Acoust Soc Am. 2015 May;137(5):2586-95. doi: 10.1121/1.4919356. J Acoust Soc Am. 2015. PMID: 25994691
-
On Short-Time Estimation of Vocal Tract Length from Formant Frequencies.PLoS One. 2015 Jul 15;10(7):e0132193. doi: 10.1371/journal.pone.0132193. eCollection 2015. PLoS One. 2015. PMID: 26177102 Free PMC article.
-
Determining the Relevant Criteria for Three-dimensional Vocal Tract Characterization.J Voice. 2018 Mar;32(2):130-142. doi: 10.1016/j.jvoice.2017.04.001. Epub 2017 Jun 21. J Voice. 2018. PMID: 28647430
-
Interactive Augmentation of Voice Quality and Reduction of Breath Airflow in the Soprano Voice.J Voice. 2016 Nov;30(6):760.e15-760.e21. doi: 10.1016/j.jvoice.2015.09.016. Epub 2015 Nov 10. J Voice. 2016. PMID: 26564580 Review.
-
Acoustics of the trained versus untrained singing voice.Curr Opin Otolaryngol Head Neck Surg. 2009 Jun;17(3):155-9. doi: 10.1097/MOO.0b013e32832af11b. Curr Opin Otolaryngol Head Neck Surg. 2009. PMID: 19365264 Review.
Cited by
-
An open-source toolbox for measuring vocal tract shape from real-time magnetic resonance images.Behav Res Methods. 2024 Mar;56(3):2623-2635. doi: 10.3758/s13428-023-02171-9. Epub 2023 Jul 28. Behav Res Methods. 2024. PMID: 37507650 Free PMC article.
References
-
- Boersma, P. (2001). “ Praat: A system for doing phonetics by computer,” Glot. Int. 5, 341–345.
LinkOut - more resources
Full Text Sources