

Supervised clustering of high-dimensional data using regularized mixture modeling
- PMID: 34293851
- PMCID: PMC8294591
- DOI: 10.1093/bib/bbaa291
Supervised clustering of high-dimensional data using regularized mixture modeling
Abstract
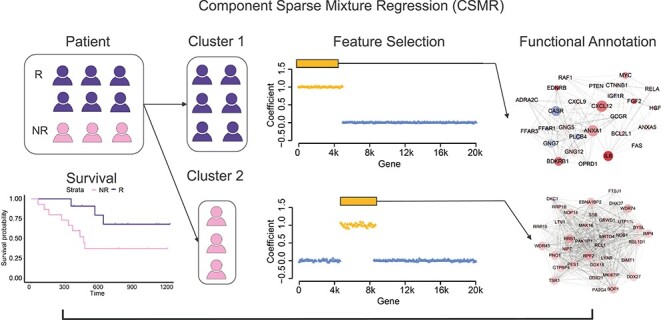
Identifying relationships between genetic variations and their clinical presentations has been challenged by the heterogeneous causes of a disease. It is imperative to unveil the relationship between the high-dimensional genetic manifestations and the clinical presentations, while taking into account the possible heterogeneity of the study subjects.We proposed a novel supervised clustering algorithm using penalized mixture regression model, called component-wise sparse mixture regression (CSMR), to deal with the challenges in studying the heterogeneous relationships between high-dimensional genetic features and a phenotype. The algorithm was adapted from the classification expectation maximization algorithm, which offers a novel supervised solution to the clustering problem, with substantial improvement on both the computational efficiency and biological interpretability. Experimental evaluation on simulated benchmark datasets demonstrated that the CSMR can accurately identify the subspaces on which subset of features are explanatory to the response variables, and it outperformed the baseline methods. Application of CSMR on a drug sensitivity dataset again demonstrated the superior performance of CSMR over the others, where CSMR is powerful in recapitulating the distinct subgroups hidden in the pool of cell lines with regards to their coping mechanisms to different drugs. CSMR represents a big data analysis tool with the potential to resolve the complexity of translating the clinical representations of the disease to the real causes underpinning it. We believe that it will bring new understanding to the molecular basis of a disease and could be of special relevance in the growing field of personalized medicine.
Keywords: disease heterogeneity; mixture modeling; supervised learning.
© The Author(s) 2020. Published by Oxford University Press. All rights reserved. For Permissions, please email: journals.permissions@oup.com.
Figures



Comment in
-
Letter to the Editor: on the stability and internal consistency of component-wise sparse mixture regression-based clustering.Brief Bioinform. 2022 Jan 17;23(1):bbab532. doi: 10.1093/bib/bbab532. Brief Bioinform. 2022. PMID: 34953466 Free PMC article.
References
-
- Cao S, Chang W, Wan C, et al.. Bi-clustering based biological and clinical characterization of colorectal cancer in complementary to cms classification. bioRxiv 508275, 2018.
