

Becoming Team Members: Identifying Interaction Patterns of Mutual Adaptation for Human-Robot Co-Learning
- PMID: 34295926
- PMCID: PMC8290358
- DOI: 10.3389/frobt.2021.692811
Becoming Team Members: Identifying Interaction Patterns of Mutual Adaptation for Human-Robot Co-Learning
Abstract
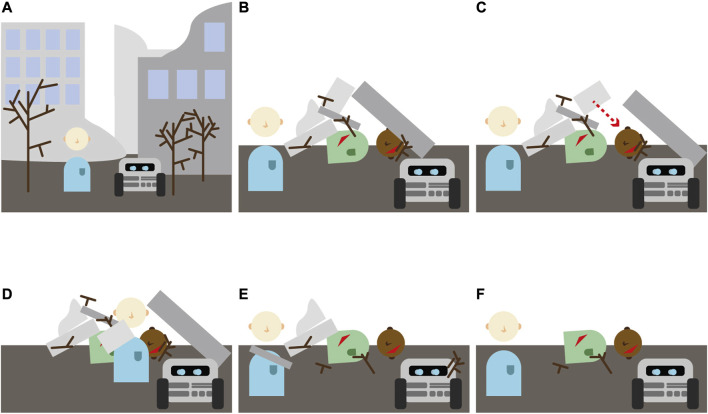
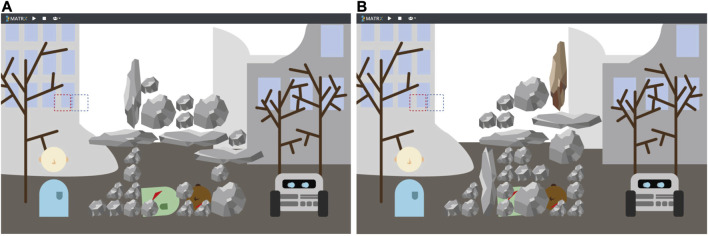
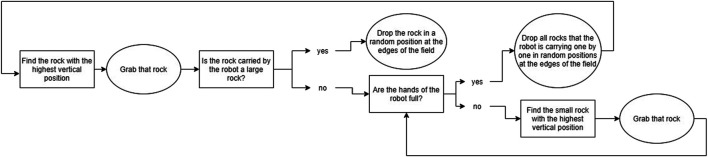
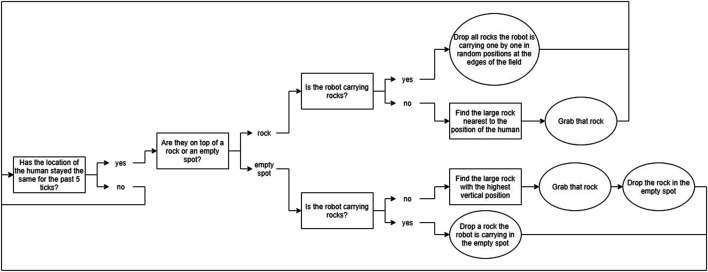
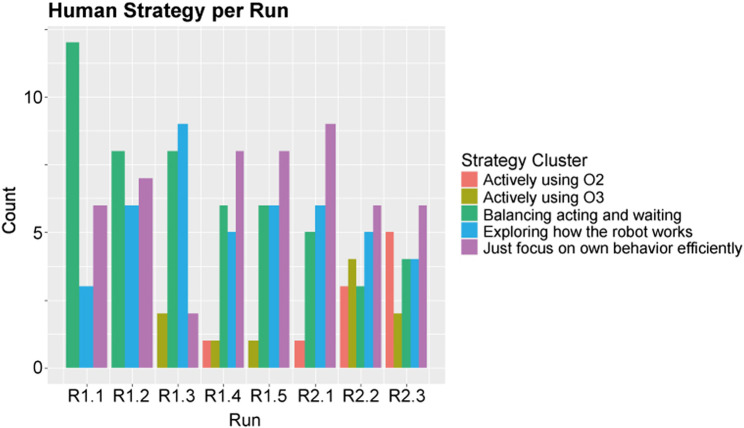
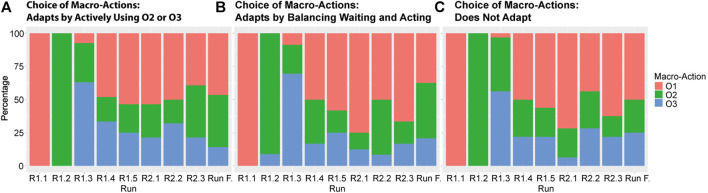
Becoming a well-functioning team requires continuous collaborative learning by all team members. This is called co-learning, conceptualized in this paper as comprising two alternating iterative stages: partners adapting their behavior to the task and to each other (co-adaptation), and partners sustaining successful behavior through communication. This paper focuses on the first stage in human-robot teams, aiming at a method for the identification of recurring behaviors that indicate co-learning. Studying this requires a task context that allows for behavioral adaptation to emerge from the interactions between human and robot. We address the requirements for conducting research into co-adaptation by a human-robot team, and designed a simplified computer simulation of an urban search and rescue task accordingly. A human participant and a virtual robot were instructed to discover how to collaboratively free victims from the rubbles of an earthquake. The virtual robot was designed to be able to real-time learn which actions best contributed to good team performance. The interactions between human participants and robots were recorded. The observations revealed patterns of interaction used by human and robot in order to adapt their behavior to the task and to one another. Results therefore show that our task environment enables us to study co-learning, and suggest that more participant adaptation improved robot learning and thus team level learning. The identified interaction patterns can emerge in similar task contexts, forming a first description and analysis method for co-learning. Moreover, the identification of interaction patterns support awareness among team members, providing the foundation for human-robot communication about the co-adaptation (i.e., the second stage of co-learning). Future research will focus on these human-robot communication processes for co-learning.
Keywords: co-adaptation; co-learning; emergent interactions; human-robot collaboration; human-robot team; interaction patterns.
Copyright © 2021 van Zoelen, van den Bosch and Neerincx.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
References
-
- Ansari F., Erol S., Sihn W. (2018). Rethinking Human-Machine Learning in Industry 4.0: How Does the Paradigm Shift Treat the Role of Human Learning? Proced. Manufacturing 23, 117–122. 10.1016/j.promfg.2018.04.003 - DOI
-
- Bosch K. v. d., Schoonderwoerd T., Blankendaal R., Neerincx M. (2019). Six Challenges for Human-AI Co-learning. Lecture Notes Comput. Sci. 11597, 572–589. 10.1007/978-3-030-22341-0_45 - DOI
LinkOut - more resources
Full Text Sources