

Assessing the Performance of Clinical Natural Language Processing Systems: Development of an Evaluation Methodology
- PMID: 34297002
- PMCID: PMC8367121
- DOI: 10.2196/20492
Assessing the Performance of Clinical Natural Language Processing Systems: Development of an Evaluation Methodology
Abstract
Background: Clinical natural language processing (cNLP) systems are of crucial importance due to their increasing capability in extracting clinically important information from free text contained in electronic health records (EHRs). The conversion of a nonstructured representation of a patient's clinical history into a structured format enables medical doctors to generate clinical knowledge at a level that was not possible before. Finally, the interpretation of the insights gained provided by cNLP systems has a great potential in driving decisions about clinical practice. However, carrying out robust evaluations of those cNLP systems is a complex task that is hindered by a lack of standard guidance on how to systematically approach them.
Objective: Our objective was to offer natural language processing (NLP) experts a methodology for the evaluation of cNLP systems to assist them in carrying out this task. By following the proposed phases, the robustness and representativeness of the performance metrics of their own cNLP systems can be assured.
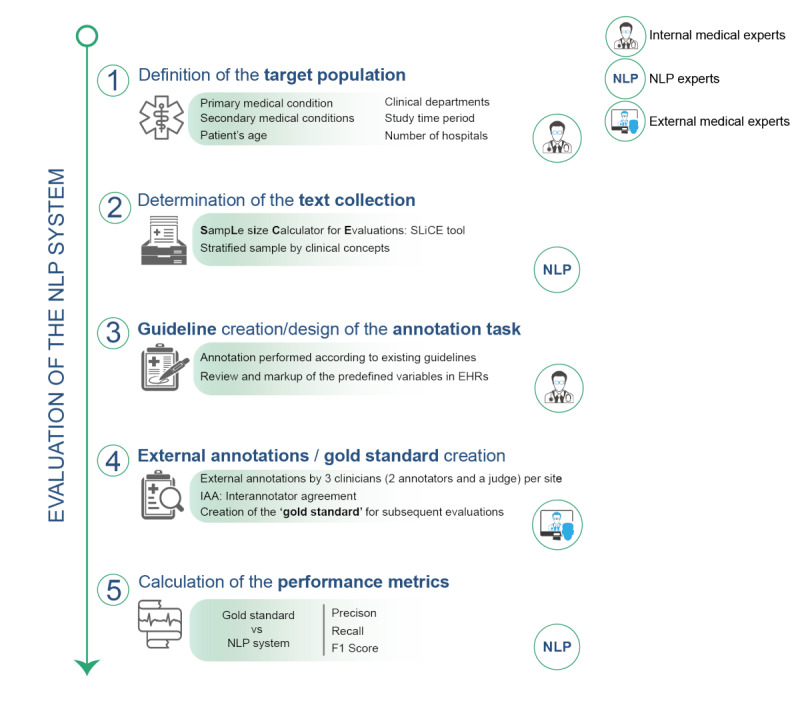
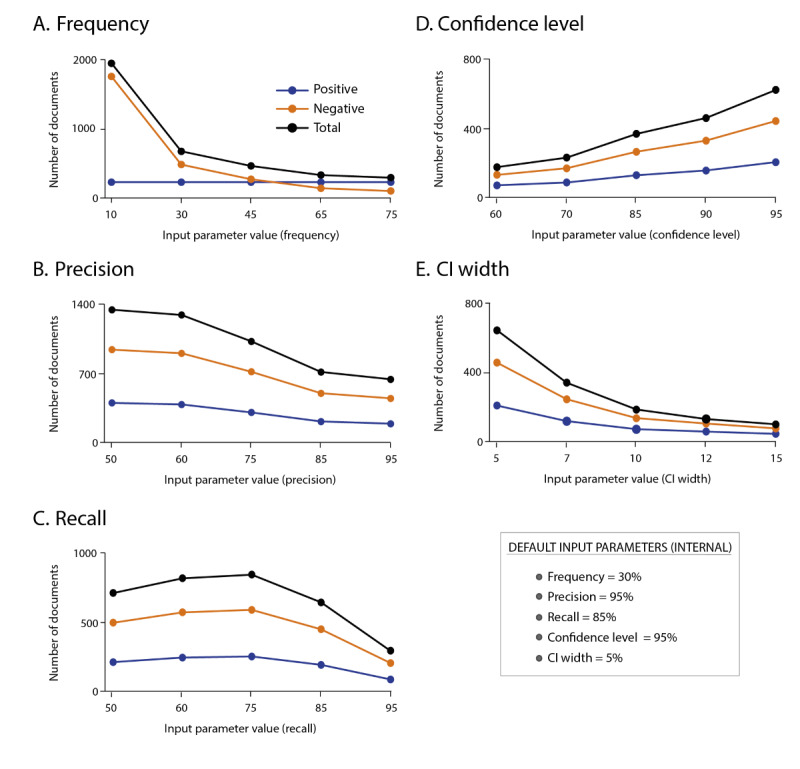
Methods: The proposed evaluation methodology comprised five phases: (1) the definition of the target population, (2) the statistical document collection, (3) the design of the annotation guidelines and annotation project, (4) the external annotations, and (5) the cNLP system performance evaluation. We presented the application of all phases to evaluate the performance of a cNLP system called "EHRead Technology" (developed by Savana, an international medical company), applied in a study on patients with asthma. As part of the evaluation methodology, we introduced the Sample Size Calculator for Evaluations (SLiCE), a software tool that calculates the number of documents needed to achieve a statistically useful and resourceful gold standard.
Results: The application of the proposed evaluation methodology on a real use-case study of patients with asthma revealed the benefit of the different phases for cNLP system evaluations. By using SLiCE to adjust the number of documents needed, a meaningful and resourceful gold standard was created. In the presented use-case, using as little as 519 EHRs, it was possible to evaluate the performance of the cNLP system and obtain performance metrics for the primary variable within the expected CIs.
Conclusions: We showed that our evaluation methodology can offer guidance to NLP experts on how to approach the evaluation of their cNLP systems. By following the five phases, NLP experts can assure the robustness of their evaluation and avoid unnecessary investment of human and financial resources. Besides the theoretical guidance, we offer SLiCE as an easy-to-use, open-source Python library.
Keywords: clinical natural language processing; electronic health records; gold standard; natural language processing; reference standard; sample size.
©Lea Canales, Sebastian Menke, Stephanie Marchesseau, Ariel D’Agostino, Carlos del Rio-Bermudez, Miren Taberna, Jorge Tello. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 23.07.2021.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
Similar articles
-
Evaluation of Natural Language Processing for the Identification of Crohn Disease-Related Variables in Spanish Electronic Health Records: A Validation Study for the PREMONITION-CD Project.JMIR Med Inform. 2022 Feb 18;10(2):e30345. doi: 10.2196/30345. JMIR Med Inform. 2022. PMID: 35179507 Free PMC article.
-
Negation recognition in clinical natural language processing using a combination of the NegEx algorithm and a convolutional neural network.BMC Med Inform Decis Mak. 2023 Oct 13;23(1):216. doi: 10.1186/s12911-023-02301-5. BMC Med Inform Decis Mak. 2023. PMID: 37833661 Free PMC article.
-
Clinical trial cohort selection based on multi-level rule-based natural language processing system.J Am Med Inform Assoc. 2019 Nov 1;26(11):1218-1226. doi: 10.1093/jamia/ocz109. J Am Med Inform Assoc. 2019. PMID: 31300825 Free PMC article.
-
Clinical Text Data in Machine Learning: Systematic Review.JMIR Med Inform. 2020 Mar 31;8(3):e17984. doi: 10.2196/17984. JMIR Med Inform. 2020. PMID: 32229465 Free PMC article. Review.
-
Natural language processing of symptoms documented in free-text narratives of electronic health records: a systematic review.J Am Med Inform Assoc. 2019 Apr 1;26(4):364-379. doi: 10.1093/jamia/ocy173. J Am Med Inform Assoc. 2019. PMID: 30726935 Free PMC article.
Cited by
-
Impact of Advanced Age on the Incidence of Major Adverse Cardiovascular Events in Patients with Type 2 Diabetes Mellitus and Stable Coronary Artery Disease in a Real-World Setting in Spain.J Clin Med. 2023 Aug 10;12(16):5218. doi: 10.3390/jcm12165218. J Clin Med. 2023. PMID: 37629262 Free PMC article.
-
Safety and Effectiveness of Oral Anticoagulants in Atrial Fibrillation: Real-World Insights Using Natural Language Processing and Machine Learning.J Clin Med. 2024 Oct 18;13(20):6226. doi: 10.3390/jcm13206226. J Clin Med. 2024. PMID: 39458177 Free PMC article.
-
Major Adverse Cardiovascular Events in Coronary Type 2 Diabetic Patients: Identification of Associated Factors Using Electronic Health Records and Natural Language Processing.J Clin Med. 2022 Oct 11;11(20):6004. doi: 10.3390/jcm11206004. J Clin Med. 2022. PMID: 36294325 Free PMC article.
-
Validation of a Natural Language Machine Learning Model for Safety Literature Surveillance.Drug Saf. 2024 Jan;47(1):71-80. doi: 10.1007/s40264-023-01367-4. Epub 2023 Nov 8. Drug Saf. 2024. PMID: 37938539 Review.
-
Predictive model for a second hip fracture occurrence using natural language processing and machine learning on electronic health records.Sci Rep. 2024 Jan 4;14(1):532. doi: 10.1038/s41598-023-50762-5. Sci Rep. 2024. PMID: 38177650 Free PMC article.
References
-
- Roberts A. Language, Structure, and Reuse in the Electronic Health Record. AMA J Ethics. 2017 Mar 01;19(3):281–288. doi: 10.1001/journalofethics.2017.19.3.stas1-1703. https://journalofethics.ama-assn.org/article/language-structure-and-reus... - DOI - PubMed
-
- Hernandez Medrano I, Tello Guijarro J, Belda C, Urena A, Salcedo I, Espinosa-Anke L, Saggion H. Savana: Re-using Electronic Health Records with Artificial Intelligence. IJIMAI. 2018;4(7):8. doi: 10.9781/ijimai.2017.03.001. https://www.ijimai.org/journal/bibcite/reference/2613 - DOI
-
- Del Rio-Bermudez C, Medrano IH, Yebes L, Poveda JL. Towards a symbiotic relationship between big data, artificial intelligence, and hospital pharmacy. J Pharm Policy Pract. 2020 Nov 09;13(1):75. doi: 10.1186/s40545-020-00276-6. https://joppp.biomedcentral.com/articles/10.1186/s40545-020-00276-6 - DOI - DOI - PMC - PubMed
-
- Sager N, Lyman M, Bucknall C, Nhan N, Tick LJ. Natural language processing and the representation of clinical data. J Am Med Inform Assoc. 1994 Mar 01;1(2):142–60. doi: 10.1136/jamia.1994.95236145. http://europepmc.org/abstract/MED/7719796 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources
Research Materials
