

Text Data Augmentation for Deep Learning
- PMID: 34306963
- PMCID: PMC8287113
- DOI: 10.1186/s40537-021-00492-0
Text Data Augmentation for Deep Learning
Abstract
Natural Language Processing (NLP) is one of the most captivating applications of Deep Learning. In this survey, we consider how the Data Augmentation training strategy can aid in its development. We begin with the major motifs of Data Augmentation summarized into strengthening local decision boundaries, brute force training, causality and counterfactual examples, and the distinction between meaning and form. We follow these motifs with a concrete list of augmentation frameworks that have been developed for text data. Deep Learning generally struggles with the measurement of generalization and characterization of overfitting. We highlight studies that cover how augmentations can construct test sets for generalization. NLP is at an early stage in applying Data Augmentation compared to Computer Vision. We highlight the key differences and promising ideas that have yet to be tested in NLP. For the sake of practical implementation, we describe tools that facilitate Data Augmentation such as the use of consistency regularization, controllers, and offline and online augmentation pipelines, to preview a few. Finally, we discuss interesting topics around Data Augmentation in NLP such as task-specific augmentations, the use of prior knowledge in self-supervised learning versus Data Augmentation, intersections with transfer and multi-task learning, and ideas for AI-GAs (AI-Generating Algorithms). We hope this paper inspires further research interest in Text Data Augmentation.
Keywords: Big Data; Data Augmentation; NLP; Natural Language Processing; Overfitting; Text Data.
© The Author(s) 2021.
Conflict of interest statement
Competing interestsThe authors declare that they have no competing interests.
Figures

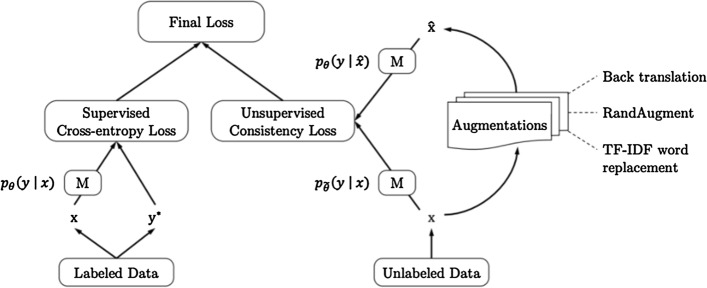
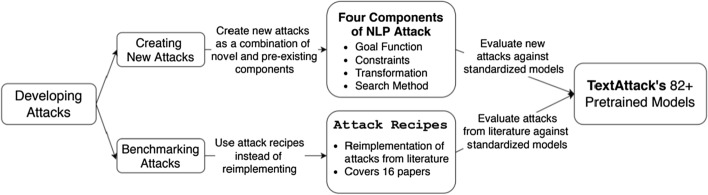
References
-
- Tang R, Nogueira R, Zhang E, Gupta N, Cam P, Cho K, Lin J. Rapidly bootstrapping a question answering dataset for covid-19. 2020. arXiv:2004.11339. Accessed Jul 2021
-
- Cachola I, Lo K, Cohan A, Weld DS. TLDR: extreme summarization of scientific documents. 2020. arXiv:2004.15011. Accessed Jul 2021
-
- Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res. 2014;15(1):1929–58.
-
- Kukačka J, Golkov V, Cremers D. Regularization for deep learning: a taxonomy 2017 . arXiv:1710.10686. Accessed Jul 2021
LinkOut - more resources
Full Text Sources
Other Literature Sources