

Highly specific and rapid molecular detection of Candida glabrata in clinical samples
- PMID: 34331680
- PMCID: PMC8578511
- DOI: 10.1007/s42770-021-00584-2
Highly specific and rapid molecular detection of Candida glabrata in clinical samples
Abstract
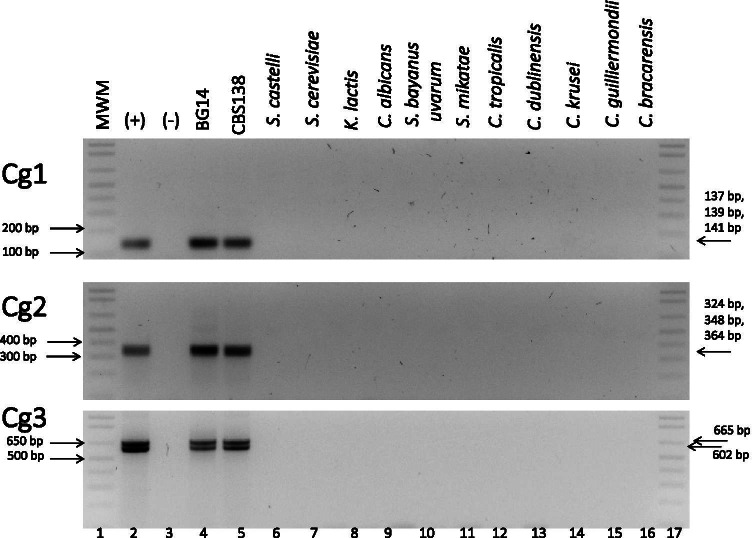
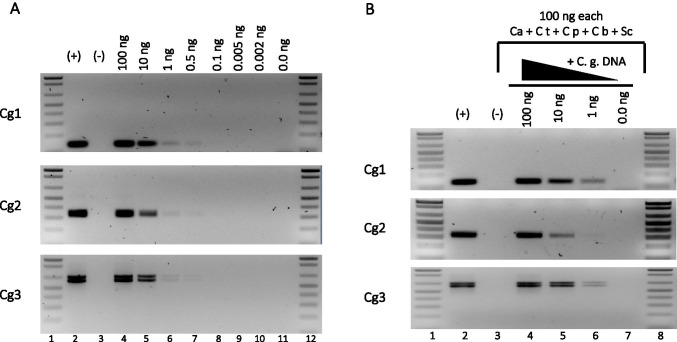
The most common nosocomial fungal infections are caused by several species of Candida, of which Candida glabrata is the second most frequently isolated species from bloodstream infections. C. glabrata displays relatively high minimal inhibitory concentration values (MIC) to the antifungal fluconazole and is associated with high mortality rates. To decrease mortality rates, the appropriate treatment must be administered promptly. C. glabrata contains in its genome several non-identical copies of species-specific sequences. We designed three pairs of C. glabrata-specific primers for endpoint PCR amplification that align to these species-specific sequences and amplify the different copies in the genome. Using these primers, we developed a fast, sensitive, inexpensive, and highly specific PCR-based method to positively detect C. glabrata DNA in a concentration-dependent manner from mixes of purified genomic DNA of several Candida species, as well as from hemocultures and urine clinical samples. This tool can be used for positive identification of C. glabrata in the clinic.
Keywords: Candida glabrata; Molecular detection; PCR amplification; Responsible Editor: Sandro Rogerio de Almeida; Species-specific sequences.
© 2021. Sociedade Brasileira de Microbiologia.
Figures


References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
