

Reward boosts reinforcement-based motor learning
- PMID: 34345810
- PMCID: PMC8319366
- DOI: 10.1016/j.isci.2021.102821
Reward boosts reinforcement-based motor learning
Abstract
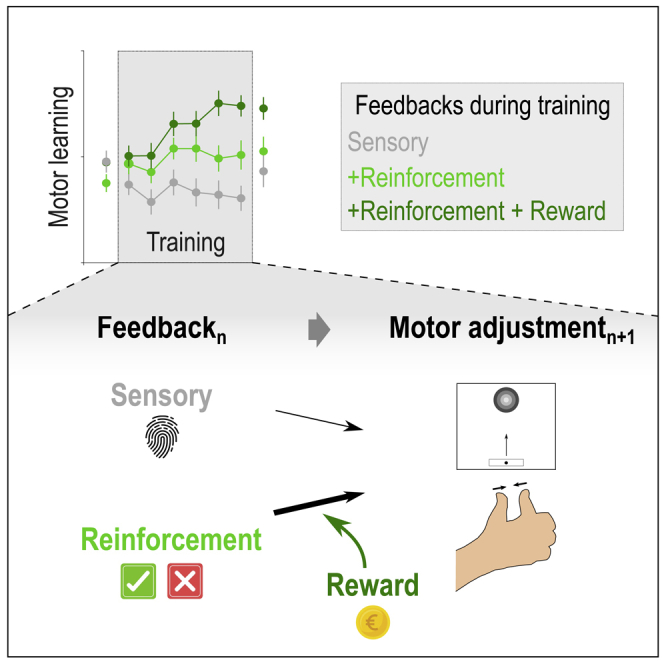
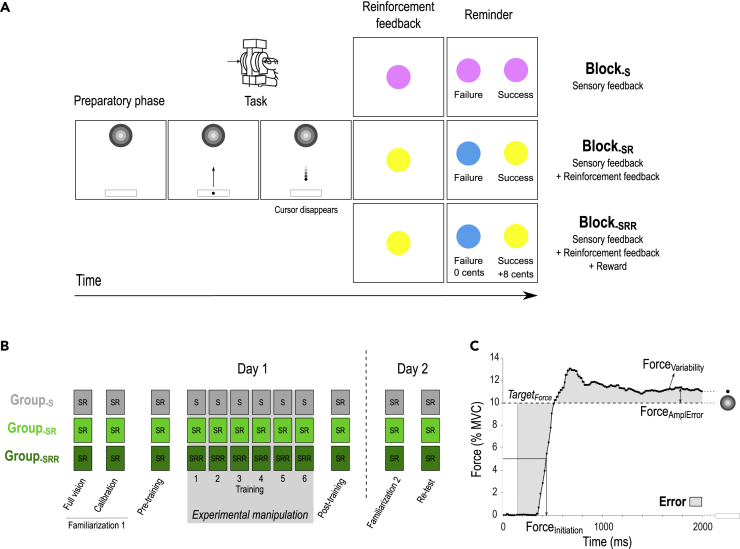
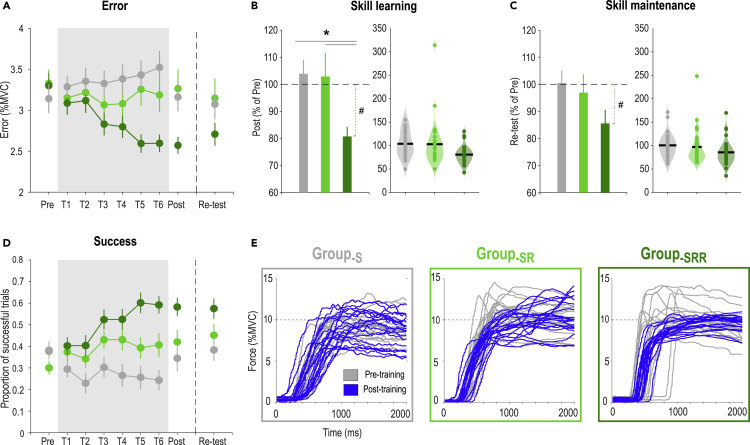
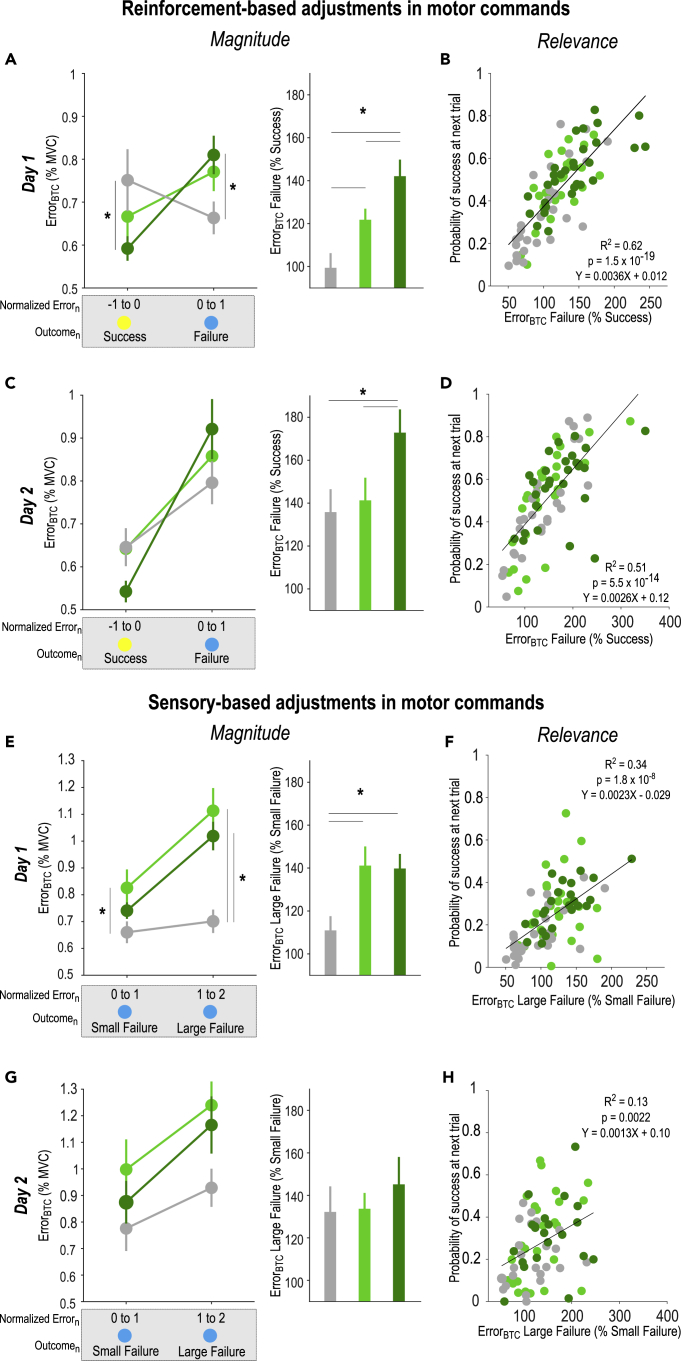
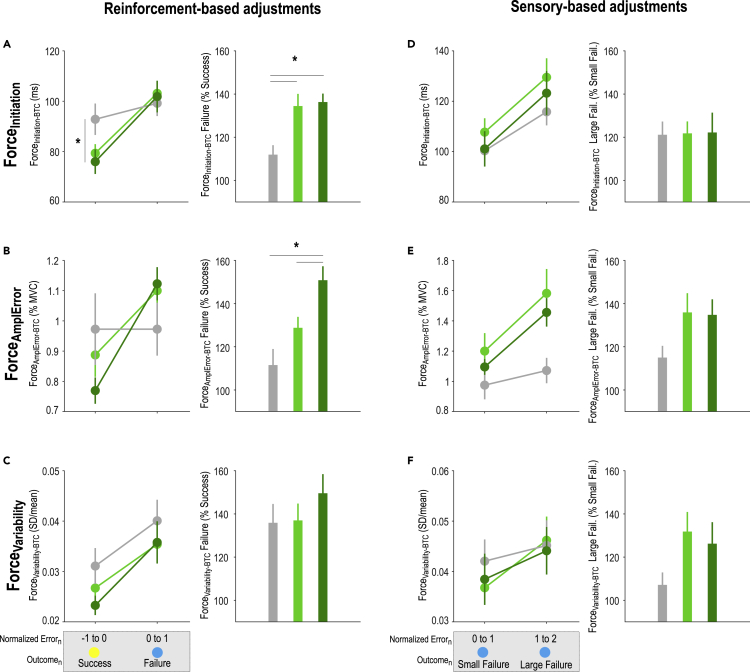
Besides relying heavily on sensory and reinforcement feedback, motor skill learning may also depend on the level of motivation experienced during training. Yet, how motivation by reward modulates motor learning remains unclear. In 90 healthy subjects, we investigated the net effect of motivation by reward on motor learning while controlling for the sensory and reinforcement feedback received by the participants. Reward improved motor skill learning beyond performance-based reinforcement feedback. Importantly, the beneficial effect of reward involved a specific potentiation of reinforcement-related adjustments in motor commands, which concerned primarily the most relevant motor component for task success and persisted on the following day in the absence of reward. We propose that the long-lasting effects of motivation on motor learning may entail a form of associative learning resulting from the repetitive pairing of the reinforcement feedback and reward during training, a mechanism that may be exploited in future rehabilitation protocols.
Keywords: Behavioral neuroscience; Cognitive neuroscience; Neuroscience; Sensory neuroscience.
© 2021 The Author(s).
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
LinkOut - more resources
Full Text Sources
