

Learning Invariant Object and Spatial View Representations in the Brain Using Slow Unsupervised Learning
- PMID: 34366818
- PMCID: PMC8335547
- DOI: 10.3389/fncom.2021.686239
Learning Invariant Object and Spatial View Representations in the Brain Using Slow Unsupervised Learning
Abstract
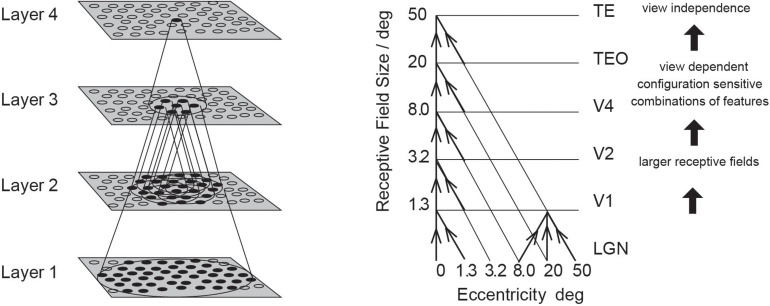
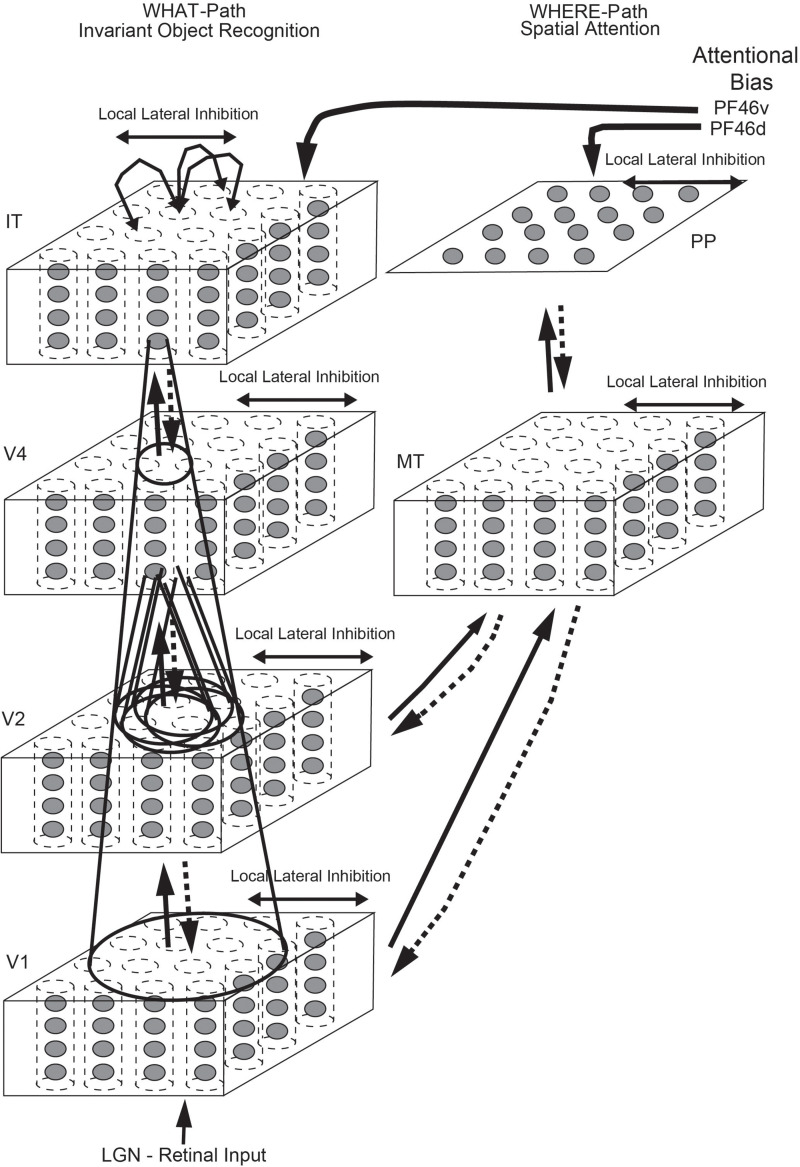
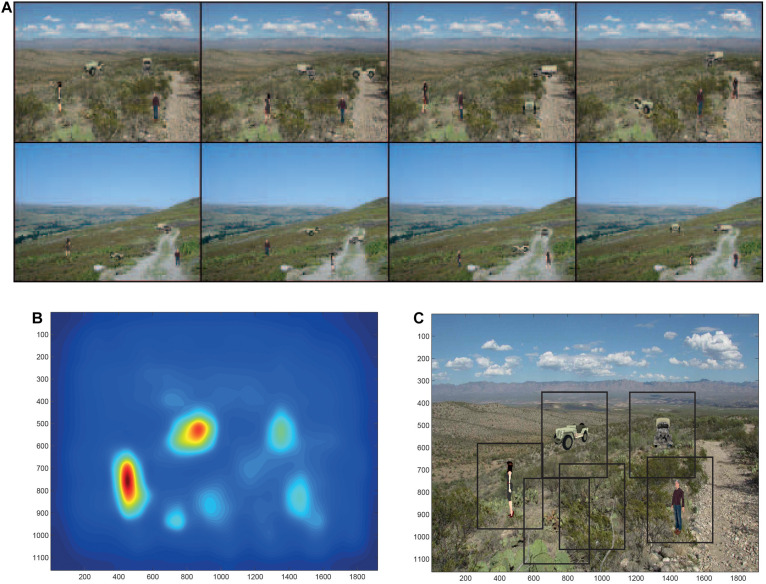
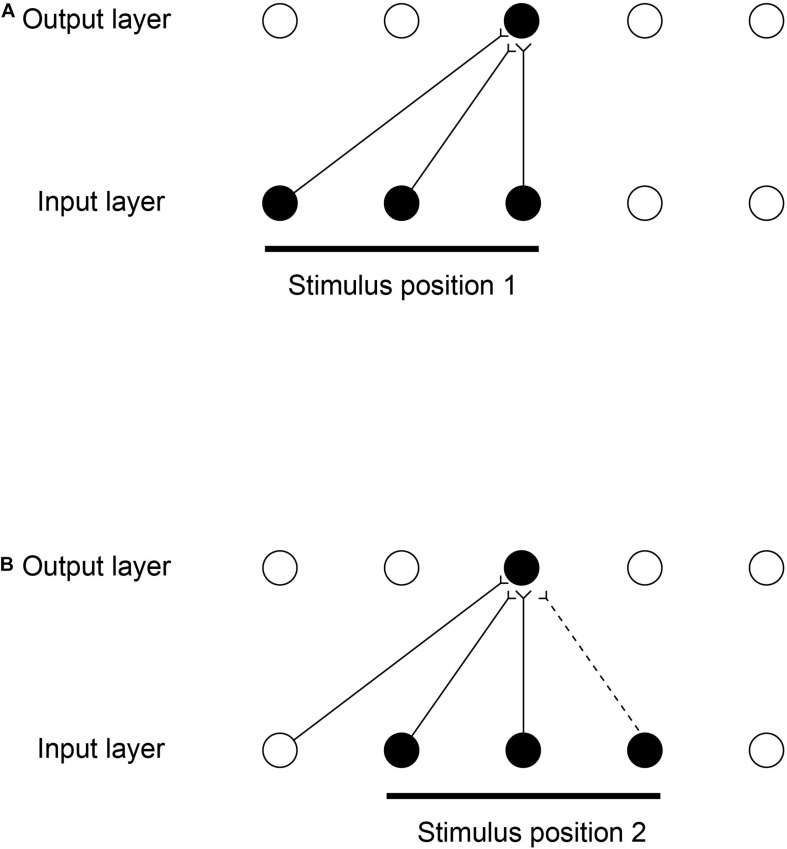
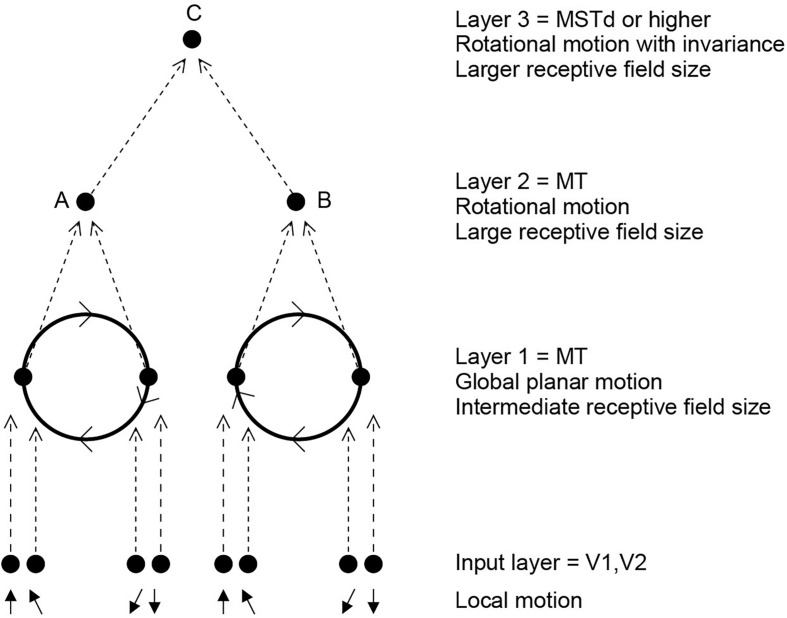
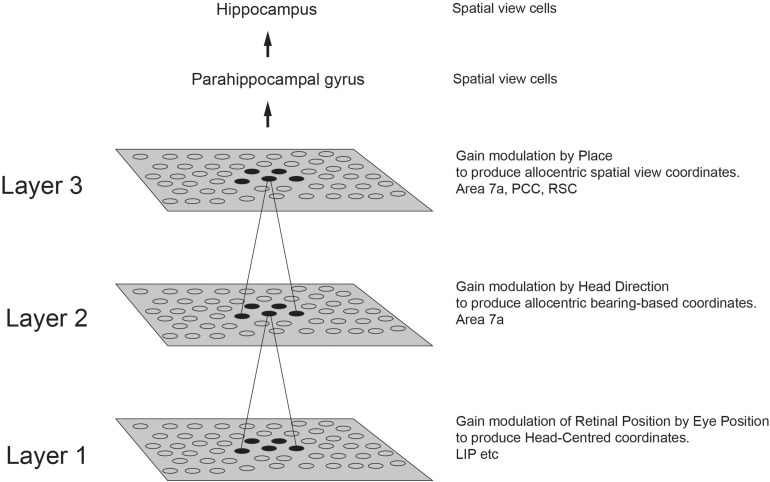
First, neurophysiological evidence for the learning of invariant representations in the inferior temporal visual cortex is described. This includes object and face representations with invariance for position, size, lighting, view and morphological transforms in the temporal lobe visual cortex; global object motion in the cortex in the superior temporal sulcus; and spatial view representations in the hippocampus that are invariant with respect to eye position, head direction, and place. Second, computational mechanisms that enable the brain to learn these invariant representations are proposed. For the ventral visual system, one key adaptation is the use of information available in the statistics of the environment in slow unsupervised learning to learn transform-invariant representations of objects. This contrasts with deep supervised learning in artificial neural networks, which uses training with thousands of exemplars forced into different categories by neuronal teachers. Similar slow learning principles apply to the learning of global object motion in the dorsal visual system leading to the cortex in the superior temporal sulcus. The learning rule that has been explored in VisNet is an associative rule with a short-term memory trace. The feed-forward architecture has four stages, with convergence from stage to stage. This type of slow learning is implemented in the brain in hierarchically organized competitive neuronal networks with convergence from stage to stage, with only 4-5 stages in the hierarchy. Slow learning is also shown to help the learning of coordinate transforms using gain modulation in the dorsal visual system extending into the parietal cortex and retrosplenial cortex. Representations are learned that are in allocentric spatial view coordinates of locations in the world and that are independent of eye position, head direction, and the place where the individual is located. This enables hippocampal spatial view cells to use idiothetic, self-motion, signals for navigation when the view details are obscured for short periods.
Keywords: convolutional neural network; face cells; hippocampus; inferior temporal visual cortex; navigation; object recognition; spatial view cells; unsupervised learning.
Copyright © 2021 Rolls.
Conflict of interest statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures




References
-
- Abeles M. (1991). Corticonics - Neural Circuits of the Cerebral Cortex. New York: Cambridge University Press.
Publication types
LinkOut - more resources
Full Text Sources