

Machine learning in the prediction of cancer therapy
- PMID: 34377366
- PMCID: PMC8321893
- DOI: 10.1016/j.csbj.2021.07.003
Machine learning in the prediction of cancer therapy
Abstract
Resistance to therapy remains a major cause of cancer treatment failures, resulting in many cancer-related deaths. Resistance can occur at any time during the treatment, even at the beginning. The current treatment plan is dependent mainly on cancer subtypes and the presence of genetic mutations. Evidently, the presence of a genetic mutation does not always predict the therapeutic response and can vary for different cancer subtypes. Therefore, there is an unmet need for predictive models to match a cancer patient with a specific drug or drug combination. Recent advancements in predictive models using artificial intelligence have shown great promise in preclinical settings. However, despite massive improvements in computational power, building clinically useable models remains challenging due to a lack of clinically meaningful pharmacogenomic data. In this review, we provide an overview of recent advancements in therapeutic response prediction using machine learning, which is the most widely used branch of artificial intelligence. We describe the basics of machine learning algorithms, illustrate their use, and highlight the current challenges in therapy response prediction for clinical practice.
Keywords: Artificial intelligence; Convolutional neural network; Deep learning; Deep neural network; Drug combinations; Drug synergy; Elastic net; Factorization machine; Graph convolutional network; Higher-order factorization machines; Lasso; Matrix factorization; Monotherapy prediction; Ordinary differential equation; Random forests; Restricted Boltzmann machine; Ridge regression; Support vector machines; Variational autoencoder; Visible neural network.
© 2021 The Author(s).
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
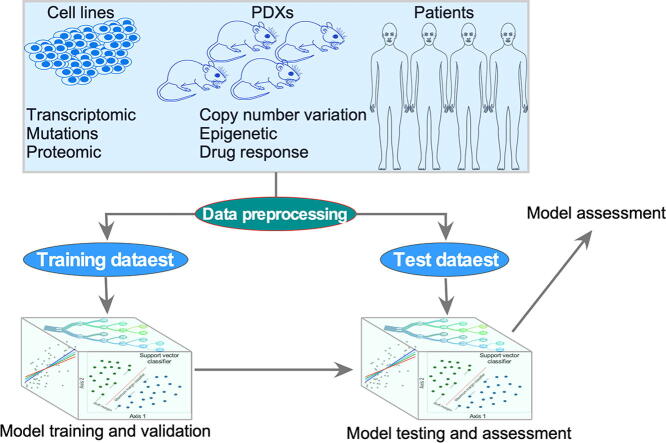
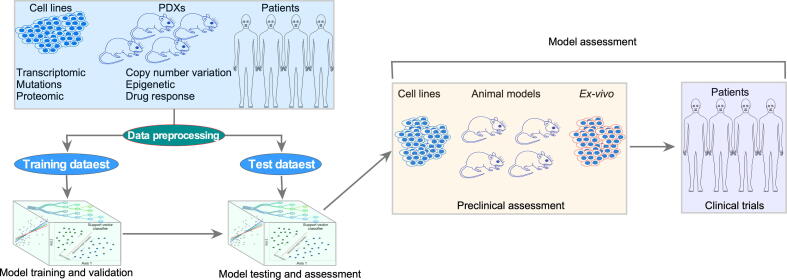
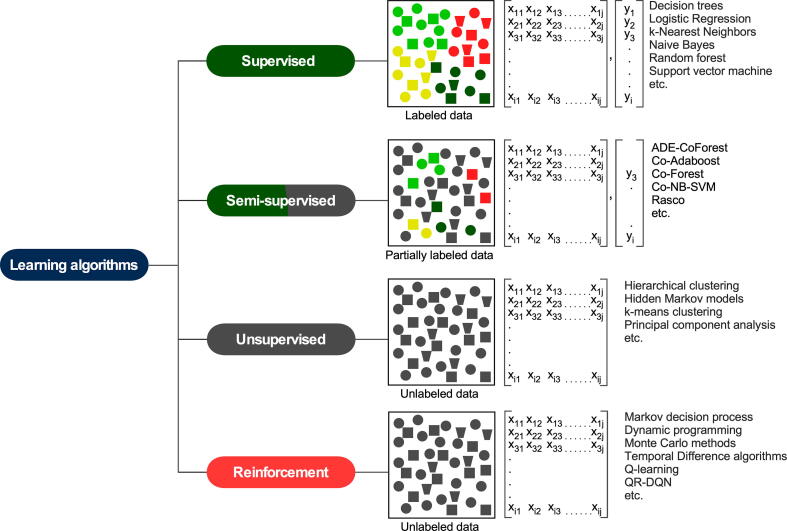
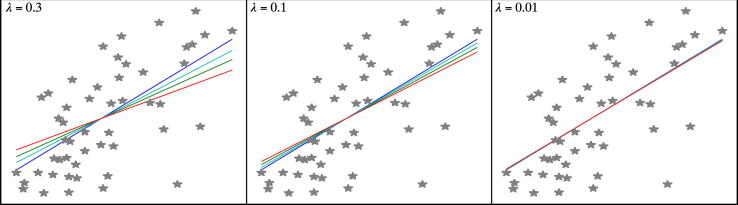


References
-
- Sharma A., Rani R. A systematic review of applications of machine learning in cancer prediction and diagnosis. Arch. Comput. Methods Eng. 2021 doi: 10.1007/s11831-021-09556-z. - DOI
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources